SyncTalk:说话头合成中的同步魔鬼
 Ray
RaySyncTalk:突破说话头合成的同步瓶颈
在计算机视觉和人工智能领域,生成逼真的说话头视频一直是一个具有挑战性的任务。近日,来自北京大学和华为云的研究团队提出了一种名为SyncTalk的创新方法,有望在这一领域取得重大突破。SyncTalk巧妙地解决了说话头合成中的同步问题,被认为是该领域的一项重要进展。
同步:说话头合成的魔鬼所在
传统的说话头合成方法往往面临着多个挑战。基于生成对抗网络(GAN)的方法难以保持一致的面部身份,而基于神经辐射场(NeRF)的方法虽然可以解决身份问题,但常常产生不匹配的唇部运动、不充分的面部表情和不稳定的头部姿势。研究人员意识到,要生成逼真的说话头视频,需要同步协调人物身份、唇部运动、面部表情和头部姿势。这种同步的缺失是导致生成结果不真实和人工痕迹明显的根本原因。
SyncTalk:精准同步的革新方案
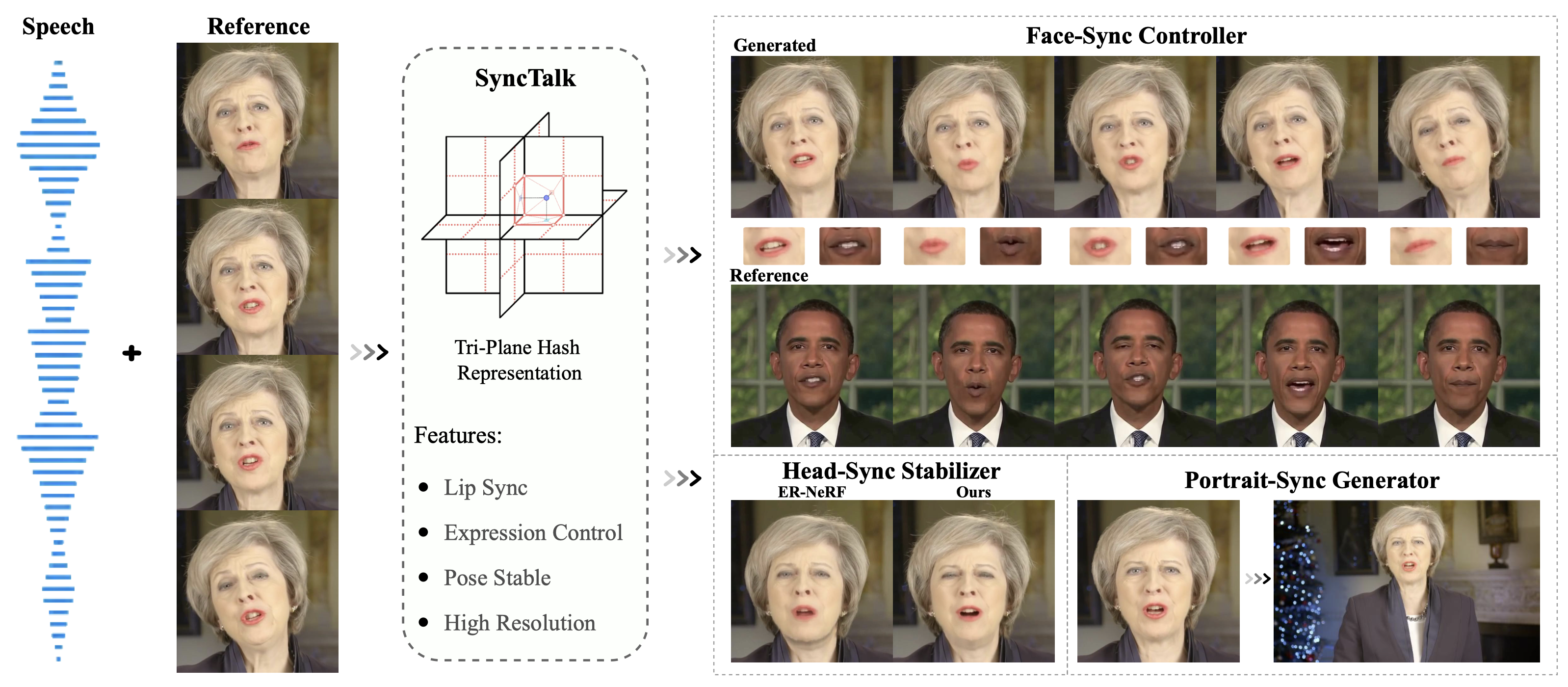
为了解决这一关键问题,研究团队开发了SyncTalk方法。SyncTalk基于NeRF技术,但引入了多项创新来增强同步性和真实感:
-
Face-Sync Controller:该组件负责将唇部运动与语音精确对齐,确保口型与声音的同步。
-
3D面部混合形状模型:这一创新使用可以捕捉准确面部表情的三维模型,使表情更加自然生动。
-
Head-Sync Stabilizer:该稳定器优化头部姿势,实现更自然的头部运动,避免不自然的抖动或僵硬。
-
Portrait-Sync Generator:这一组件负责恢复头发细节并将生成的头部与躯干无缝融合,提供完整的视觉体验。
技术亮点与创新
SyncTalk的核心创新在于其采用的三平面哈希表示技术。这种技术能够有效维持人物的身份特征,同时允许对唇部运动、面部表情和头部姿势进行精确控制。与传统方法相比,SyncTalk在以下方面表现出色:
- 身份保持:通过三平面哈希表示,SyncTalk能够在整个视频中保持一致的人物身份。
- 唇形同步:Face-Sync Controller确保唇部运动与语音完美匹配,大大提高了视频的真实感。
- 表情丰富:3D面部混合形状模型使生成的面部表情更加丰富自然,避免了呆板或过于夸张的表情。
- 头部稳定:Head-Sync Stabilizer实现了平滑自然的头部运动,避免了许多其他方法中常见的抖动或僵硬问题。
- 细节还原:Portrait-Sync Generator在保证整体真实感的同时,还能还原头发等细节,提升了视频的整体质量。
实验结果与性能评估
研究团队进行了广泛的实验和用户研究,结果表明SyncTalk在同步性和真实感方面都显著优于现有的最先进方法。具体来说:
- 在PSNR(峰值信噪比)指标上,SyncTalk(带Portrait模式)达到了37.644,远高于不带Portrait模式的32.201。
- 在LPIPS(感知相似度)指标上,SyncTalk(带Portrait模式)仅为0.0117,表现优异。
- 在LMD(唇部运动差异)指标上,SyncTalk的表现也非常稳定,保持在2.825左右。
这些数据充分证明了SyncTalk在图像质量、感知相似度和唇形同步方面的卓越表现。
应用前景与潜在影响
SyncTalk的成功开发为多个领域带来了新的可能性:
- 影视制作:可用于快速生成配音角色或进行语言配音,大大提高制作效率。
- 虚拟主播:为新闻、教育等领域提供更真实、��更具表现力的虚拟主播。
- 远程通讯:可能改变视频会议的体验,让远程交流更加自然和身临其境。
- 虚拟现实(VR)和增强现实(AR):为这些新兴技术提供更逼真的人物互动体验。
- 个性化数字助手:开发更具表现力和个性化的AI助手界面。
未来展望与研究方向
尽管SyncTalk取得了显著进展,但研究团队认为仍有进一步改进的空间:
- 实时性能优化:提高处理速度,实现实时或近实时的视频生成。
- 多语言支持:扩展系统以支持更多语言,适应全球化需求。
- 情感表达增强:进一步提升面部表情的细微变化,使情感表达更加丰富。
- 个性化定制:开发工具允许用户自定义或微调生成的说话头特征。
- 伦理与隐私考虑:研究如何防止技术被滥用,保护个人隐私和知识产权。
结语
SyncTalk的出现标志着说话头合成技术迈入了一个新的时代。通过巧妙解决同步问题,这项技术为创造更真实、更具表现力的数字人物铺平了道路。随着技术的不断完善和应用范围的扩大,我们可以期待看到SyncTalk在多个领域带来的革新性变化。然而,在享受技术进步带来的便利的同时,我们也需要警惕其潜在的风险,确保这项强大的工具被正确且负责任地使用。
SyncTalk不仅是一项技术突破,更是一个激发我们思考人工智能与人类交互未来的契机。它展示了当我们专注于解决核心问题时,能够取得怎样令人惊叹的进展。未来,随着更多研究者和开发者的加入,我们有理由相信,数字世界与现实世界之间的界限将变得越来越模糊,为人类交流和表达开辟出前所未有的可能性。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用��于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播��,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号