T-Eval: 评估大型语言模型工具使用能力的创新方法
 Ray
RayT-Eval: 解构大型语言模型的工具使用能力
在人工智能领域,大型语言模型(LLM)的发展一直备受关注。这些模型在各种自然语言处理任务中展现出惊人的性能,并通过工具的辅助进一步拓展了应用范围。然而,如何有效评估和分析LLM的工具使用能力一直是一个有待深入探索的问题。针对这一挑战,研究人员提出了一种创新的评估框架——T-Eval,旨在逐步评估大型语言模型的工具使用能力。
T-Eval的创新之处
T-Eval的独特之处在于其全面而细致的评估方法。与以往整体评估模型的方法不同,T-Eval将工具使用过程分解为多个子过程,包括指令遵循、规划、推理、检索、理解和审查。这种分解方法使得研究者能够更深入地理解LLM在工具使用各个环节的表现。
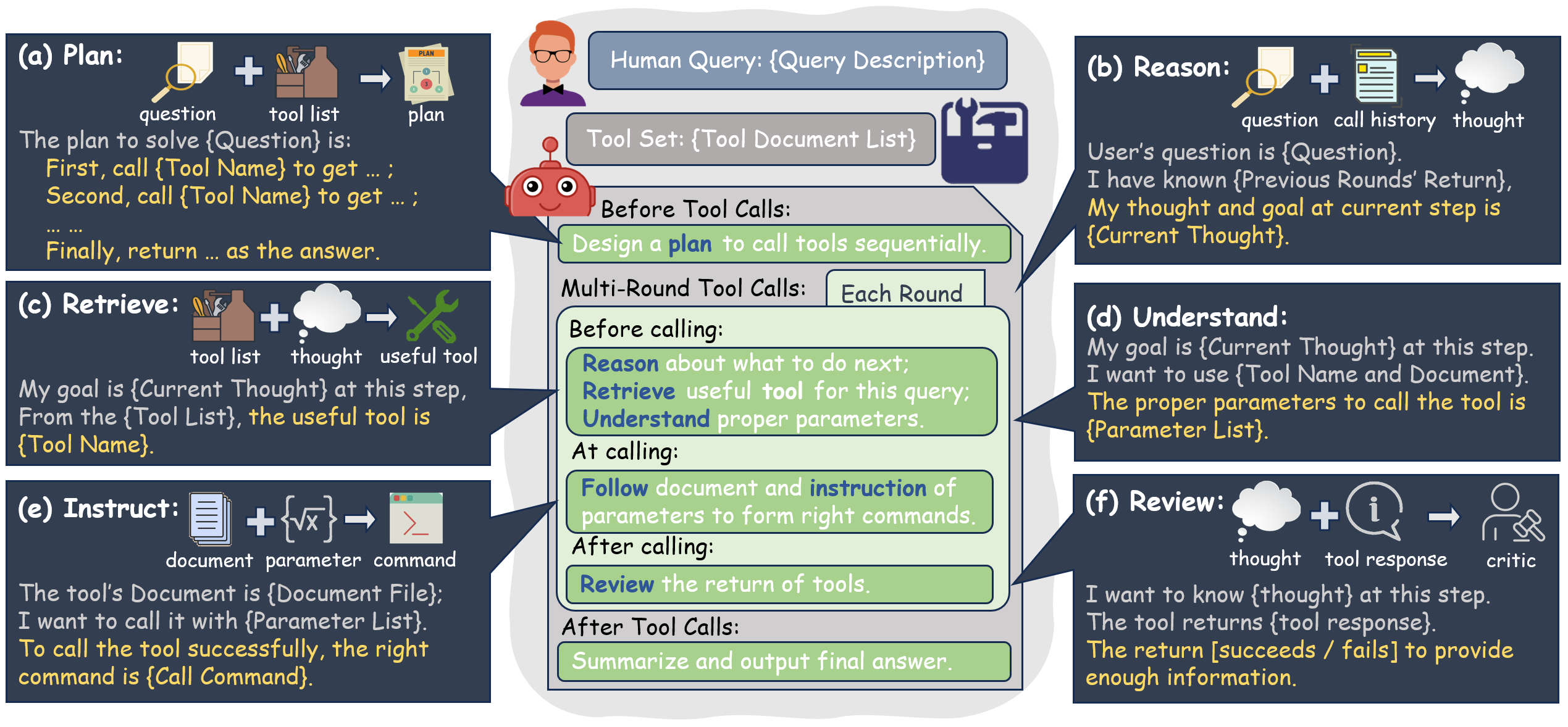
通过这种细粒度的评估,T-Eval不仅能够评估模型的整体能力,还能够分析模型在各个子能力上的表现。这为我们提供了一个新的视角,可以更全面地了解LLM的工具使用能力。
T-Eval的实施过程
T-Eval的评估过程采用多轮对话的方式进行。评估者会向模型提供一系列指令和任务,模型需要调用相应的API或工具来完成这些任务。评估过程中,系统会记录模型的每一步操作,包括指令理解、工具选择、参数设置等。
例如,在一个典型的评估场景中,系统可能会要求模型使用Airbnb的搜索API来查找特定城市的房源信息。模型需要正确理解指令,选择合适的API,设置正确的参数,并解释返回的结果。
[ { "role": "system", "content": "You have access to the following API:\n{'name': 'AirbnbSearch.search_property_by_place', 'description': 'This function takes various parameters to search properties on Airbnb.', 'required_parameters': [{'name': 'place', 'type': 'STRING', 'description': 'The name of the destination.'}], 'optional_parameters': [], 'return_data': [{'name': 'property', 'description': 'a list of at most 3 properties, containing id, name, and address.'}]} Please generate the response in the following format:\ngoal: goal to call this action\n\nname: api name to call\n\nargs: JSON format api args in ONLY one line\n" }, { "role": "user", "content": "Call the function AirbnbSearch.search_property_by_place with the parameter as follows: 'place' is 'Berlin'." } ]
这种评估方法不仅测试了模型的基本语言理解能力,还评估了其使用工具的实际操作能力。
T-Eval的技术实现
T-Eval的实现依赖于Lagent和OpenCompass这两个开源工具。研究团队提供了详细的使用说明,包括如何设置环境、准备测试数据、运行评估脚本等。
T-Eval支持对API-based模型和HuggingFace模型进行评估。对于API-based模型,用户需要设置相应的API密钥;对于HuggingFace模型,则需要下载模型到本地并进行相应的配置。
T-Eval的应用价值
T-Eval的提出为LLM的评估带来了新的可能性。它不仅提供了一个标准化的评估框架,还为研究人员和开发者提供了深入分析模型能力的工具。通过T-Eval,我们可以:
- 更精确地定位模型在工具使用过程中的优势和不足
- 为模型的改进提供具体方向
- 比较不同模型在各个子能力上的表现差异
- 为LLM的实际应用场景提供更可靠的性能评估
T-Eval的最新进展
T-Eval项目一直在不断更新和完善。最近的一些重要更新包括:
- 2024年2月22日:发布了新的数据集和1/5子集(包含中英文版本),并优化了推理速度。
- 2024年1月8日:发布了中文评测数据集和榜单。
- 2023年12月22日:相关论文在ArXiv上发布。
这些更新表明T-Eval正在不断扩展其应用范围,并努力提高其评估效率和准确性。
参与T-Eval项目
T-Eval是一个开源项目,欢迎研究者和开发者参与贡献。项目团队提供了详细的使用说明和代码示例,使得参与者可以快速上手。同时,项目还设立了官方排行榜,鼓励研究者提交自己的评估结果,促进了整个领域的交流和进步。
如果您对T-Eval项目感兴趣,可以通过以下方式参与:
- 访问GitHub仓库了解详情
- 下载并使用T-Eval评估您的模型
- 提交评估结果到官方排行榜
- 为项目贡献代码或提出改进建议
结语
T-Eval的出现为大型语言模型的评估带来了新的视角和方法。通过将工具使用能力分解为多个子过程,T-Eval提供了一种更加细致和全面的评估方法。这不仅有助于我们更好地理解LLM的能力,也为未来LLM的改进和应用提供了重要指导。
随着人工智能技术的不断发展,像T-Eval这样的评估工具将在推动LLM技术进步中发挥越来越重要的作用。我们期待看到T-Eval在未来能够产生更广泛的影响,为LLM的研究和应用带来更多创新。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号