T-Rex2: revolucionando la detección de objetos con sinergia texto-visual
 Ray
RayLa evolución de la detección de objetos: T-Rex2 🦖
La detección de objetos ha sido durante mucho tiempo un pilar fundamental en el campo de la visión por computadora, con aplicaciones que van desde la conducción autónoma hasta la moderación de contenido. Sin embargo, los modelos tradicionales de detección de objetos han enfrentado limitaciones significativas debido a su naturaleza de conjunto cerrado, restringiendo su capacidad para reconocer solo categorías predeterminadas. T-Rex2 surge como una solución innovadora a estos desafíos, integrando de manera única prompts tanto textuales como visuales en un solo modelo poderoso.
Superando las limitaciones tradicionales 🚀
Los enfoques convencionales de detección de objetos requieren un proceso de entrenamiento arduo y costoso. Demandan conocimientos especializados, conjuntos de datos extensos y una afinación meticulosa del modelo para lograr la precisión deseada. Además, la introducción de una nueva categoría de objetos exacerba estos desafíos, obligando a repetir todo el proceso desde cero.
T-Rex2 aborda estas limitaciones de frente al aprovechar la sinergia entre prompts textuales y visuales. Esta combinación única equipa al modelo con robustas capacidades de cero disparo, convirtiéndolo en una herramienta versátil capaz de adaptarse al paisaje siempre cambiante de la detección de objetos.
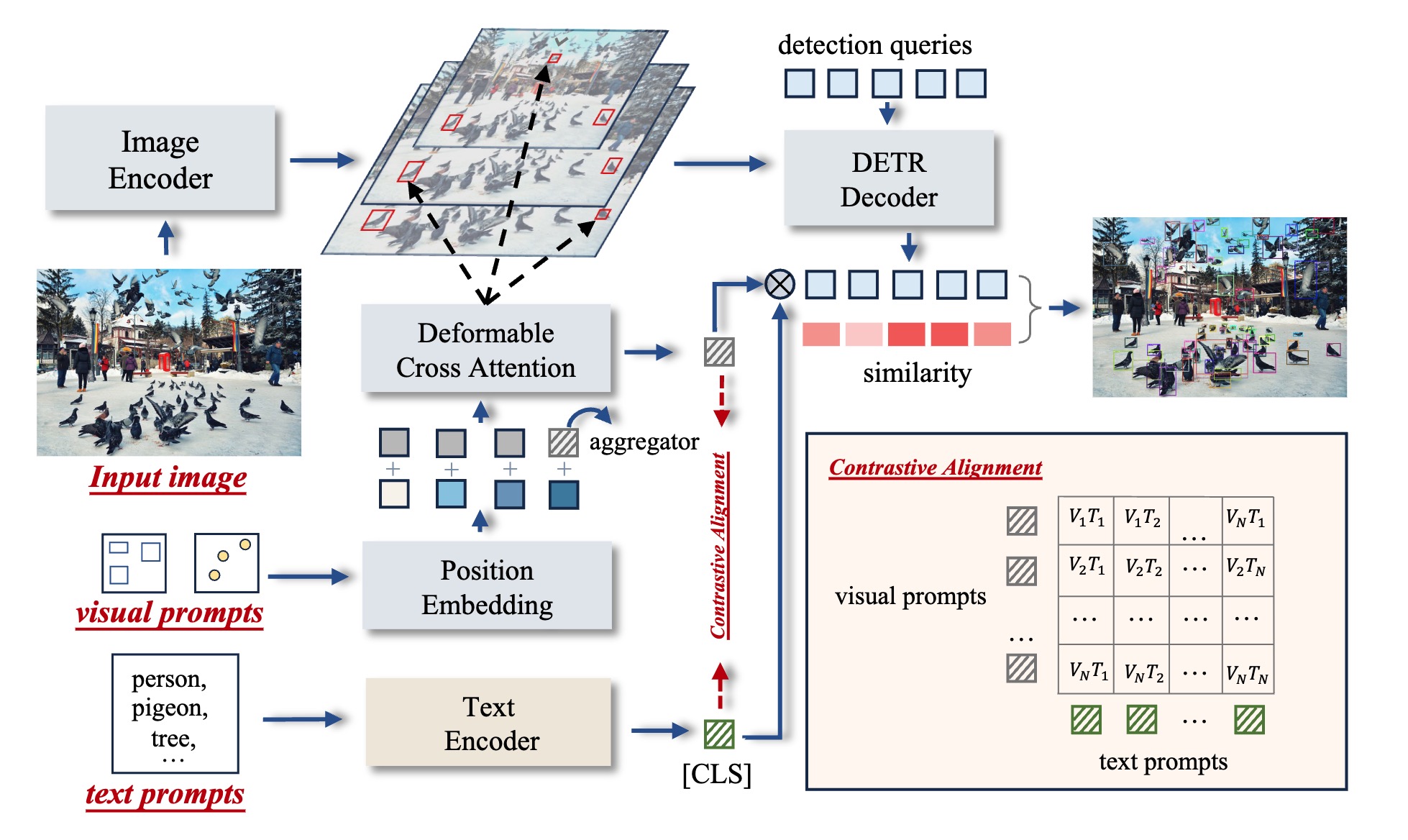
Capacidades y aplicaciones de T-Rex2 📊
T-Rex2 no es solo una mejora incremental; representa un salto cuántico en las capacidades de detección de objetos. El modelo es excepcionalmente adecuado para una amplia gama de aplicaciones del mundo real, incluyendo:
- Agricultura: Detección de cultivos, plagas y enfermedades de plantas.
- Industria: Inspección de calidad y detección de defectos en líneas de producción.
- Monitoreo de ganado y vida silvestre: Seguimiento de animales y estudios ecológicos.
- Biología y medicina: Análisis de imágenes médicas y microscopía.
- OCR (Reconocimiento Óptico de Caracteres): Extracción de texto de imágenes y documentos.
- Retail: Inventario automático y análisis de estanterías.
- Electrónica: Inspección de componentes y circuitos.
- Transporte y logística: Seguimiento de paquetes y gestión de almacenes.
T-Rex2 soporta principalmente tres flujos de trabajo principales:
- Flujo de trabajo de prompt visual interactivo
- Flujo de trabajo de prompt visual genérico
- Flujo de trabajo de prompt de texto
Esta versatilidad permite que T-Rex2 cubra la mayoría de los escenarios de aplicación que requieren detección de objetos, adaptándose a las necesidades específicas de cada industria y caso de uso.
Demostración y accesibilidad 🖥️
Para facilitar la adopción y experimentación con T-Rex2, los desarrolladores han puesto a disposición una demostración en línea. Esta plataforma interactiva permite a los usuarios explorar las capacidades del modelo de primera mano.
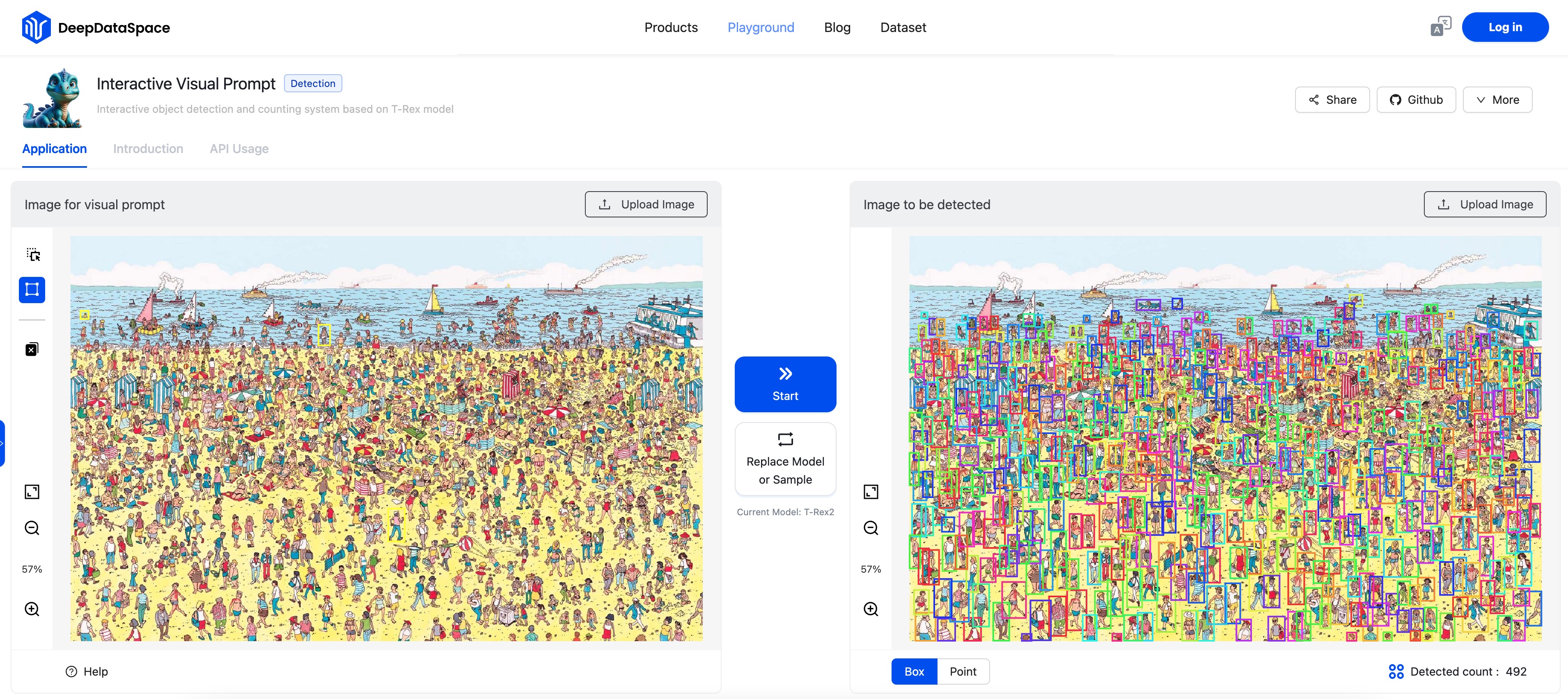
Además de la demo en línea, el equipo detrás de T-Rex2 ha abierto el acceso gratuito a la API del modelo. Esta iniciativa es particularmente beneficiosa para educadores, estudiantes e investigadores, ofreciendo un API con tiempos de uso extensos para apoyar esfuerzos educativos y de investigación.
Uso de la API de T-Rex2 🛠️
Para comenzar a utilizar la API de T-Rex2, los usuarios deben seguir un proceso de configuración simple:
- Clonar el repositorio de GitHub
- Instalar el paquete de API
- Obtener un token de API a través del correo electrónico
Una vez configurado, los desarrolladores pueden aprovechar varios funcionalidades clave:
- API de Prompt Visual Interactivo: Permite a los usuarios proporcionar prompts visuales en formato de cajas o puntos en una imagen dada para especificar el objeto a detectar.
- API de Prompt Visual Genérico: Facilita la provisión de prompts visuales en una imagen de referencia para detectar objetos en otra imagen.
- API de Personalización de Embedding de Prompt Visual: Permite a los usuarios personalizar un embedding visual para una categoría de objeto utilizando múltiples imágenes.
- API de Inferencia de Embedding: Utiliza los embeddings de prompt visual generados para detectar objetos en cualquier imagen.
Impacto y futuro de T-Rex2 🔮
T-Rex2 no solo representa un avance significativo en la tecnología de detección de objetos, sino que también abre nuevas posibilidades para la investigación y aplicación en diversos campos. Su capacidad para manejar escenarios de conjunto abierto y su flexibilidad para adaptarse a nuevas categorías sin reentrenamiento extensivo lo posicionan como una herramienta invaluable para investigadores y profesionales por igual.
La comunidad académica y la industria están comenzando a reconocer el potencial transformador de T-Rex2. Con su capacidad para sinergizar prompts textuales y visuales, el modelo está allanando el camino para sistemas de visión por computadora más adaptativos e inteligentes.
Conclusión y llamado a la acción 🎯
T-Rex2 representa un hito significativo en la evolución de la detección de objetos, ofreciendo una solución versátil y potente para una amplia gama de aplicaciones. Su combinación única de prompts textuales y visuales, junto con sus robustas capacidades de cero disparo, lo posicionan como una herramienta indispensable en el kit de herramientas de cualquier profesional de visión por computadora.
Invitamos a investigadores, desarrolladores y entusiastas a explorar las capacidades de T-Rex2. Ya sea a través de la demo en línea, experimentando con la API, o contribuyendo al desarrollo continuo del proyecto, hay numerosas oportunidades para participar y aprovechar esta tecnología innovadora.
Para obtener más información, acceder a la API, o contribuir al proyecto, visita el repositorio oficial de T-Rex2 en GitHub. Juntos, podemos continuar empujando los límites de lo que es posible en el campo de la detección de objetos y la visión por computadora.
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等�。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目�。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方��面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号