
Tabular-LLM学习资源汇总 - 构建面向表格智能任务的大型语言模型
Tabular-LLM是一个旨在构建专门面向表格智能任务的大型语言模型的开源项目。如果您对"表格+LLM"感兴趣,这里为您汇总了一些相关的学习资源:
项目介绍
Tabular-LLM项目的主要目标是:
- 广泛收集开源的表格智能任务数据集(如表格问答、表格-文本生成等)
- 将原始任务数据整理为指令微调格式的数据
- 基于整理好的数据微调LLM,增强其对表格数据的理解能力
- 最终构建出专门面向表格智能任务的大型语言模型
该项目希望能助力开源社区复现并进一步增强类似ChatGPT的表格处理能力,同时为研究者构建特定领域的表格智能LLM提供更好的数据和模型基础。
项目地址
- GitHub: https://github.com/SpursGoZmy/Tabular-LLM
- Hugging Face: https://huggingface.co/datasets/QingyiSi/Alpaca-CoT/tree/main/Tabular-LLM-Data
主要内容
- 探索不同类型表格的表示方法
- 收集并整理涵盖多种类型表格、多种表格智能任务的数据
- 开源表格智能LLM并进行测试分析
数据资源
项目整理了多个表格智能任务的数据集,包括:
- 表格问答: WikiTableQuestions, TabFact, HybridQA等
- 表格事实验证: TabFact, FEVEROUS等
- 表格-文本生成: ToTTo, Logic2Text等
所有数据集都被统一整理为指令微调格式,可直接用于LLM训练。
模型资源
基于整理的数据,项目提供了多个微调后的LoRA权重:
- saved-bloomz-7b-mt_TQA: 基于TQA数据微调的bloomz-7b-mt
- saved-llama-7b-hf_TQA: 基于TQA数据微调的llama-7b-hf
相关论文
项目还维护了一份"LLM+表格"相关论文列表: https://github.com/SpursGoZmy/Awesome-Tabular-LLMs
学习资料
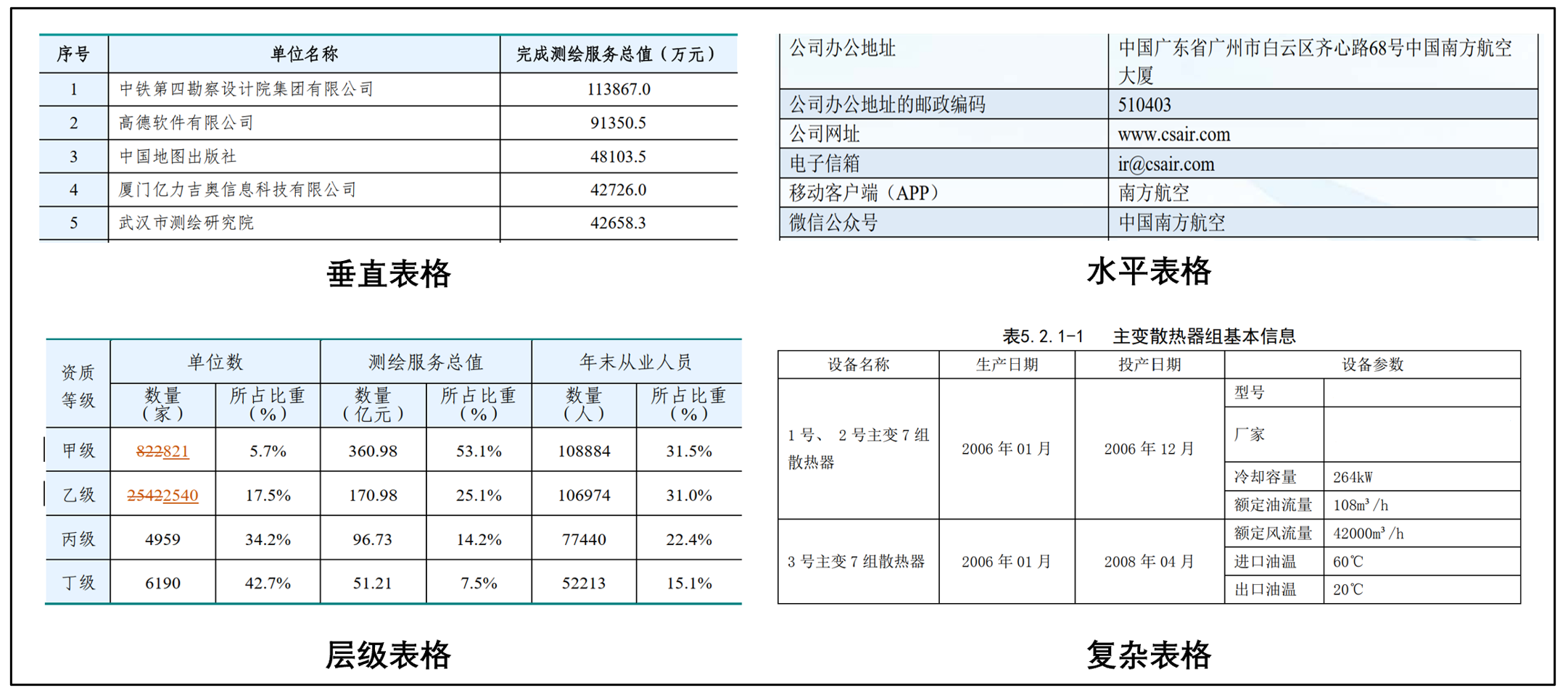
Tabular-LLM项目为构建表格智能LLM提供了丰富的数据和基础模型资源。无论您是想了解表格智能任务,还是希望构建自己的表格LLM,都可以从该项目中获得有价值的参考。欢迎关注该项目的最新进展,共同推动表格智能LLM的发展!










