
Talk2Arxiv简介
Talk2Arxiv是一个开源的RAG(检索增强生成)系统,专门为学术论文PDF设计。它允许用户通过简单修改URL的方式,将任何ArXiv论文加载到一个响应式的RAG聊天应用中。
例如,只需将原始ArXiv链接 www.arxiv.org/pdf/1706.03762.pdf 前面加上"talk2",即可得到 www.talk2arxiv.org/pdf/1706.03762.pdf ,从而启动与该论文的对话界面。
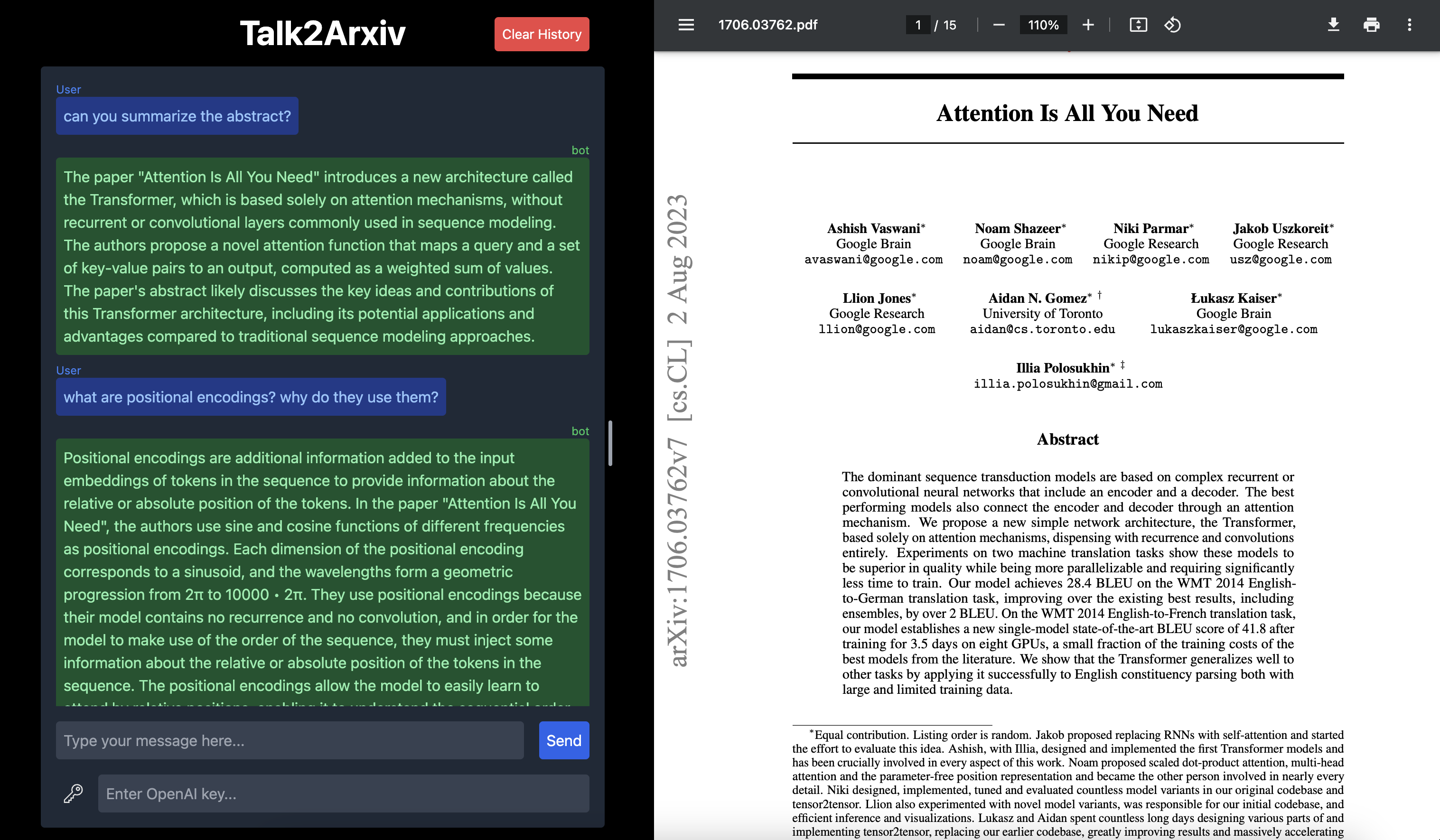
主要功能
Talk2Arxiv具有以下核心功能:
-
PDF解析:利用GROBID高效地从PDF中提取文本。
-
分块算法:采用自定义算法进行最优文本分块。按照逻辑部分(如引言、摘要、作者等)进行分块,并使用递归细分分块(512字符、256字符、128字符等)。
-
文本嵌入:使用Cohere的EmbedV3模型生成准确的文本嵌入。
-
向量数据库集成:使用Qdrant存储和查询嵌入。这也起到缓存研究论文的作用,每篇论文只需嵌入一次。
-
上下文相关性:采用重排序过程,根据用户输入选择最相关的内容。
使用方法
-
在ArXiv论文URL前加上"talk2"
-
加载论文后,即可开始与论文内容进行对话交互
技术实现
- 前端:使用TypeScript、ReactJS、TailwindCSS和NextJS开发
- 后端:由talk2arxiv-server提供支持,使用Flask、Gunicorn和Nginx
未来规划
- 改进分块策略
- 转向提取源LaTeX代码,以提高符号数学公式和非标准文本元素的检索效果
- 使用视觉理解LLM模型
- 基于账户的个性化
开源贡献
Talk2Arxiv是一个开源项目,欢迎社区贡献。您可以通过以下方式参与:
- 在GitHub仓库上提交问题或拉取请求
- 分享使用体验和改进建议
- 帮助改进文档和教程
通过Talk2Arxiv,研究人员和学生可以更轻松地与复杂的学术论文进行互动,提高学习和研究效率。无论您是想快速了解一篇论文的要点,还是深入探讨具体细节,Talk2Arxiv都能为您提供智能的对话支持。
立即尝试Talk2Arxiv,体验AI辅助学术研究的新方式吧!










