
TSDB简介
TSDB (Time Series Database) 是一个专门用于管理时间序列数据的Python工具箱。它的出现极大地简化了研究人员和工程师在处理时间序列数据时的工作流程。TSDB的核心优势在于它能够通过简单的一行代码,即可加载多达172个来自不同领域的公开时间序列数据集。
TSDB的主要特点
-
一站式数据获取:TSDB提供了一个集中的平台,用户可以方便地访问和下载多个时间序列数据集,无需再在网络上四处搜寻。
-
多领域覆盖:包含的数据集涵盖了医疗、金融、电力、交通、天气等多个领域,满足不同研究方向的需求。
-
简单易用:通过简洁的API设计,用户只需一行代码即可完成数据的加载。
-
自动化处理:TSDB会自动完成数据的下载、解压和基本处理,节省了大量的预处理时间。
-
灵活性:虽然提供了基本的数据处理,但TSDB并不会对数据进行过度处理(如标准化),保留了用户自定义处理的空间。
-
缓存机制:已加载的数据集会被缓存,提高了重复使用时的效率。
TSDB的应用场景
TSDB主要服务于以下几类应用场景:
-
学术研究:为时间序列分析、机器学习和深度学习等领域的研究人员提供丰富的数据资源。
-
算法开发与测试:开发者可以利用多样化的数据集来测试和验证自己的算法。
-
教育培训:作为教学资源,帮助学生理解和实践时间序列数据分析。
-
行业应用:为不同行业的数据科学家提供基准数据集,用于模型开发和性能对比。
TSDB的核心功能
-
数据集列表:用户可以通过
tsdb.list()查看所有可用的数据集。 -
数据加载:使用
tsdb.load(dataset_name)即可加载指定的数据集。 -
原始数据获取:如果需要未经处理的原始数据,可以使用
tsdb.download_and_extract()函数。 -
缓存管理:提供了查看、删除缓存的功能,方便用户管理本地存储。
-
缓存迁移:支持将缓存目录迁移到外部存储,以节省本地磁盘空间。
TSDB支持的数据集
TSDB目前支持多个知名的时间序列数据集,包括但不限于:
- PhysioNet Challenge 2012/2019
- 北京多站点空气质量数据
- 意大利空气质量数据
- 电力负荷图表
- 电力变压器温度数据
- 船舶AIS数据
- PeMS交通数据
- 阿拉巴马州太阳能数据
- UCR & UEA数据集(共163个数据集)
这些数据集涵盖了预测、插值、分类等多种任务类型,为研究者提供了丰富的选择。
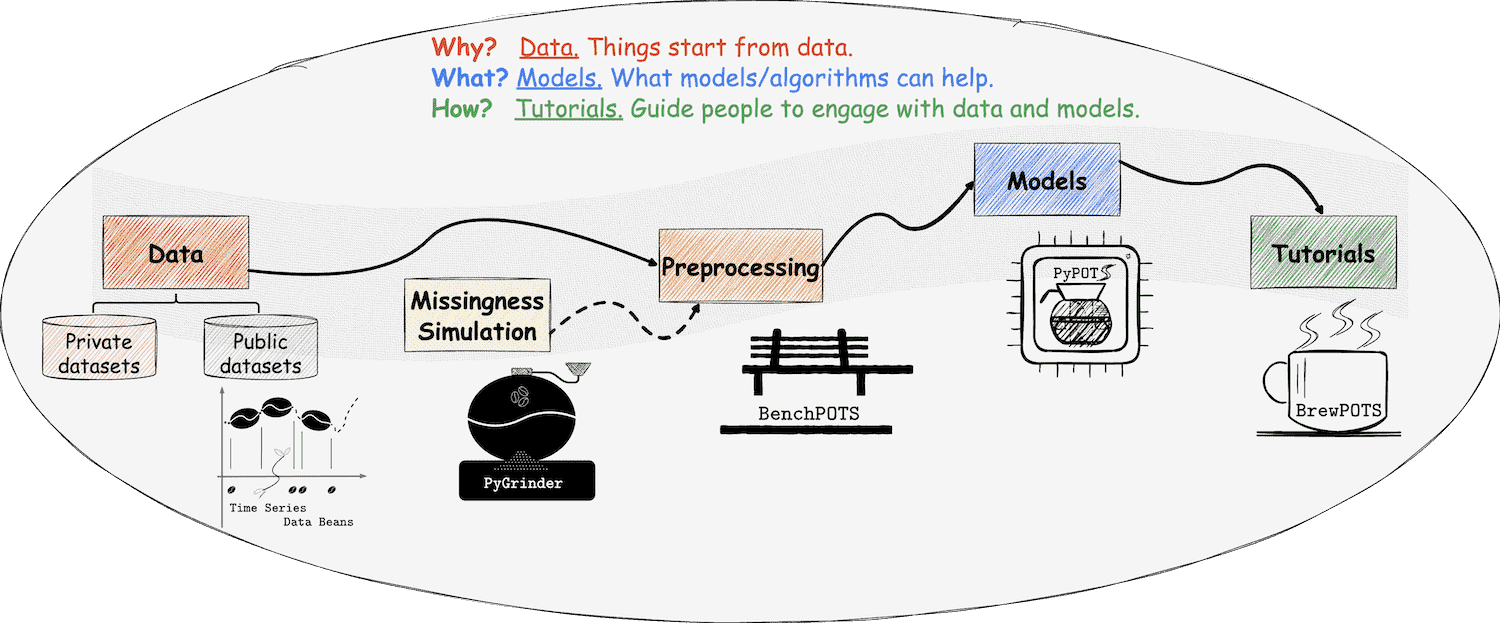
使用TSDB的优势
-
时间节省:免去了手动搜索、下载和预处理数据的繁琐步骤。
-
标准化:所有数据集通过统一的接口访问,提高了代码的可复用性。
-
可靠性:作为开源项目,TSDB得到了社区的持续维护和改进。
-
扩展性:用户可以方便地请求添加新的数据集或自行贡献代码。
安装与使用
TSDB可以通过pip或conda安装:
pip install tsdb
或
conda install tsdb -c conda-forge
基本使用示例:
import tsdb
# 列出所有可用数据集
tsdb.list()
# 加载特定数据集
data = tsdb.load('physionet_2012')
# 下载原始数据
tsdb.download_and_extract('physionet_2012', './save_it_here')
结语
TSDB作为一个强大的时间序列数据管理工具,极大地简化了研究人员和工程师处理时间序列数据的工作流程。它不仅提供了丰富的数据资源,还通过简洁的接口设计,使得数据的获取和处理变得前所未有的简单。随着时间序列分析在各个领域的应用日益广泛,TSDB无疑将成为数据科学家和研究人员的得力助手,推动时间序列相关研究和应用的快速发展。









