
tiny-cuda-nn: 轻量级高性能CUDA神经网络框架
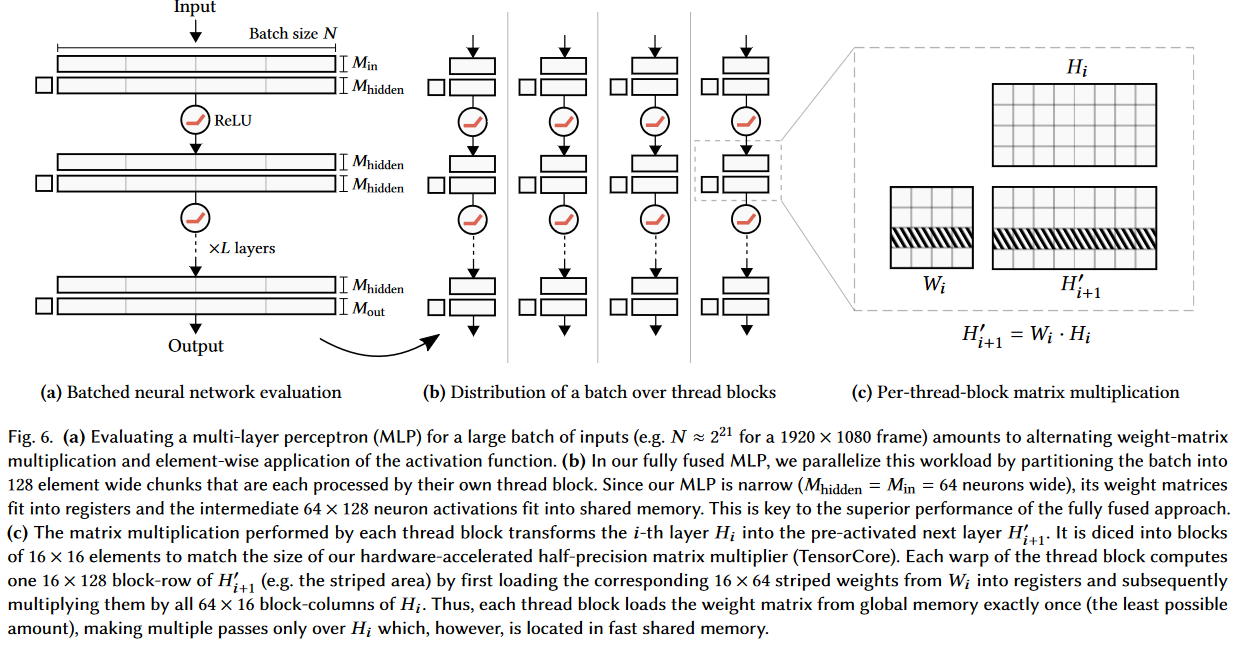
tiny-cuda-nn是由NVIDIA研究院开发的一个小型但功能强大的CUDA神经网络框架。它专注于提供高性能的神经网络训练和推理能力,特别适合于需要快速迭代的研究项目和实时应用程序。虽然体积小巧,但tiny-cuda-nn却包含了许多创新技术,使其在特定任务上的性能远超其他主流深度学习框架。
主要特性
- 闪电般快速的全连接网络
tiny-cuda-nn最引人注目的特性是其"完全融合"的多层感知机(MLP)实现。这种实现方式可以将整个MLP网络融合到单个CUDA核心中,大大减少了内存访问和同步开销。在RTX 3090 GPU上,tiny-cuda-nn的MLP可以比TensorFlow快10-100倍。
- 多分辨率哈希编码
框架还提供了一种新颖的多分辨率哈希编码技术。这种编码方法可以高效地表示高维空间中的稀疏数据,在神经辐射场(NeRF)等三维重建任务中表现出色。
- 灵活的组件化设计
tiny-cuda-nn采用模块化设计,包含多种网络结构、编码方法、损失函数和优化器。用户可以根据需求自由组合这些组件,快速构建出定制的神经网络模型。
- PyTorch扩展
框架提供了PyTorch扩展,允许在Python环境中使用其高性能组件。这为研究人员提供了熟悉的编程接口,同时保留了CUDA级别的极致性能。
性能对比
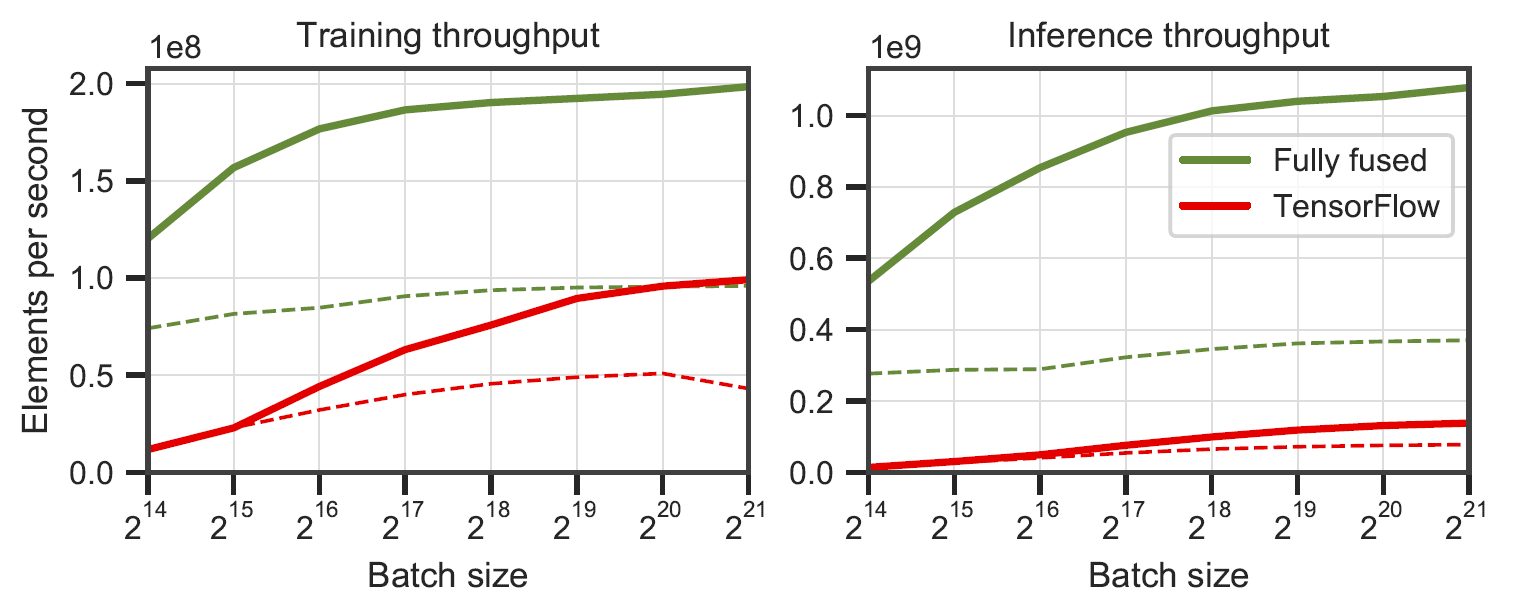
上图展示了tiny-cuda-nn与TensorFlow在MLP训练上的性能对比。可以看到,tiny-cuda-nn在各种网络规模下都保持了显著的性能优势。特别是在较小的网络上,tiny-cuda-nn的训练速度可以比TensorFlow快100倍以上。
应用示例
tiny-cuda-nn提供了一个简单的2D图像学习示例,展示了框架的基本用法:
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.json
这个命令会训练一个神经网络来重建输入图像。下面是不同训练步数的重建结果:
| 10 steps | 100 steps | 1000 steps | Reference image |
|---|---|---|---|
 |  |  |  |
可以看到,仅仅1000步训练就可以得到非常接近原图的重建结果。在RTX 4090上,这个过程只需要1秒多一点的时间。
系统要求
- NVIDIA GPU (推荐RTX 20系列以上)
- CUDA 10.2+
- C++14兼容的编译器
- CMake 3.21+
安装使用
tiny-cuda-nn支持从源码编译安装:
git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
cd tiny-cuda-nn
cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
cmake --build build --config RelWithDebInfo -j
对于Python用户,可以通过pip安装PyTorch扩展:
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
应用领域
tiny-cuda-nn已经在多个前沿研究项目中得到应用,包括:
- 即时神经图形基元 (Instant Neural Graphics Primitives)
- 从图像中提取三角形3D模型、材质和光照
- 实时神经辐射缓存路径追踪
这些项目展示了tiny-cuda-nn在计算机图形学和机器学习交叉领域的强大潜力。
结语
tiny-cuda-nn为需要极致性能的神经网络应用提供了一个轻量级但功能强大的解决方案。它的高效实现和创新技术使其在特定任务上远超传统深度学习框架。无论是进行学术研究还是开发实时应用,tiny-cuda-nn都是一个值得考虑的强大工具。
随着深度学习和图形学的不断融合,像tiny-cuda-nn这样专注于高性能的框架必将在未来发挥越来越重要的作用。我们期待看到更多基于tiny-cuda-nn的创新应用和突破性研究成果。









