
Tiny GPU:从零开始学习GPU工作原理
在现代计算机系统中,图形处理单元(GPU)扮演着越来越重要的角色。不仅在图形渲染方面表现出色,在通用计算和人工智能领域也大放异彩。然而,由于商业竞争激烈,主流GPU厂商对其硬件架构细节往往讳莫如深,这给想要深入了解GPU工作原理的开发者和研究人员带来了不小的挑战。
为了解决这个问题,一位名叫Adam Majmudar的开发者创建了Tiny GPU项目。这是一个使用Verilog实现的最小化GPU设计,旨在帮助人们从底层理解GPU的工作原理。让我们一起来深入探索这个有趣的项目吧!
Tiny GPU概述
Tiny GPU是一个极简的GPU实现,专门为学习GPU工作原理而设计。它包含了不到15个完整注释的Verilog文件,提供了完整的架构和指令集文档,并实现了矩阵加法和矩阵乘法等示例内核,同时支持内核模拟和执行跟踪。
与现代GPU相比,Tiny GPU简化了许多复杂的功能,专注于展示GPU的核心元素和基本工作原理。它主要探索以下三个方面:
- 架构 - GPU的整体结构是什么样的?最重要的组成部分有哪些?
- 并行化 - 如何在硬件层面实现SIMD(单指令多数据)编程模型?
- 内存 - GPU如何在有限的内存带宽约束下工作?
通过学习Tiny GPU,我们可以掌握GPU的基本工作原理,为进一步理解现代GPU中的高级功能和优化奠定基础。
Tiny GPU架构
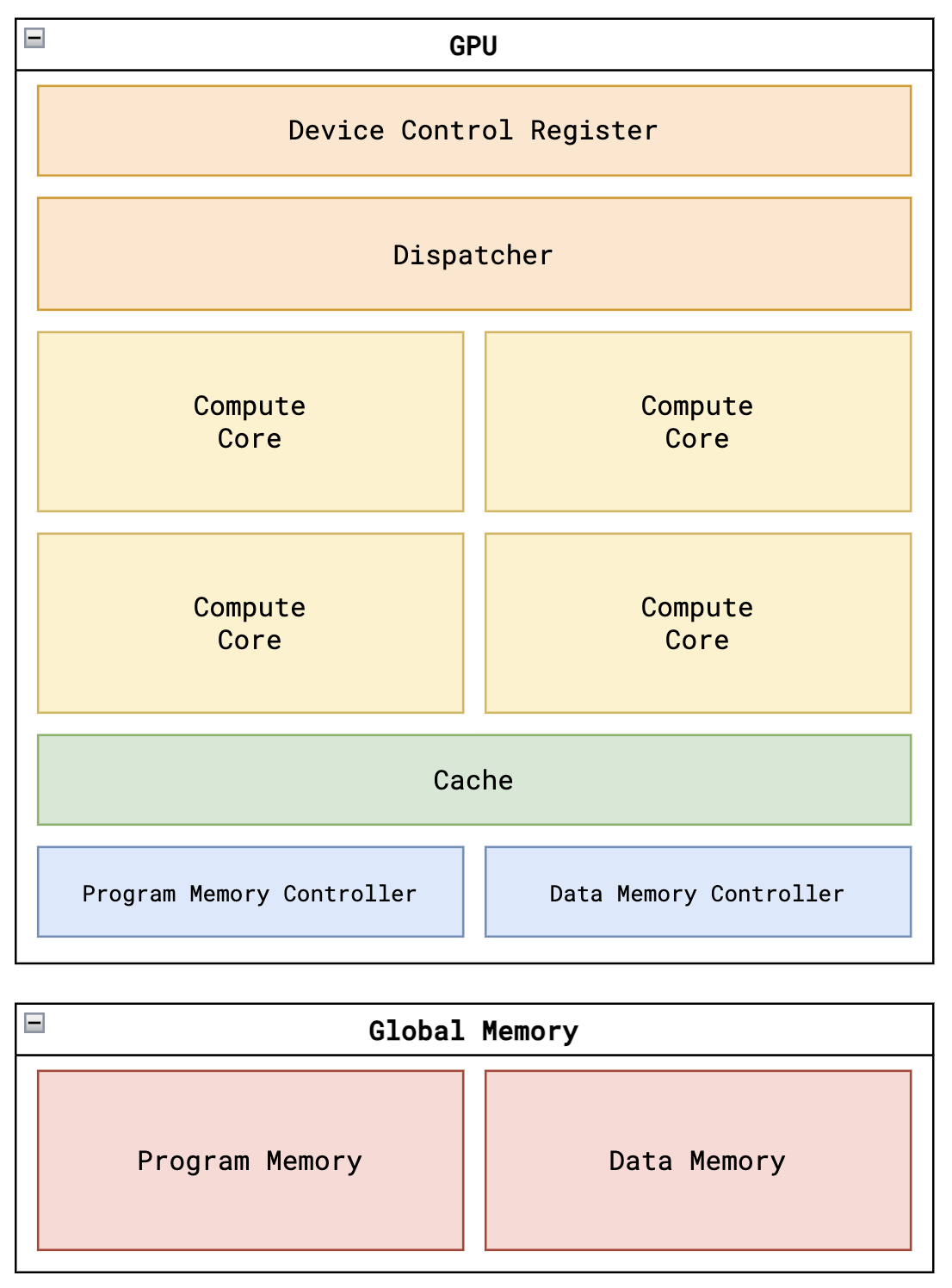
Tiny GPU的整体架构如上图所示,主要包含以下几个部分:
- 设备控制寄存器:存储内核执行的元数据,如线程数量等。
- 调度器:负责将线程分配到不同的计算核心上执行。
- 多个计算核心:执行具体的计算任务。
- 内存控制器:管理数据内存和程序内存的访问。
- 缓存:存储最近访问的数据,提高访问效率。
GPU执行流程
Tiny GPU被设计为一次执行一个内核。要启动一个内核,需要执行以下步骤:
- 将内核代码加载到全局程序内存
- 将必要的数据加载到数据内存
- 在设备控制寄存器中指定要启动的线程数量
- 将启动信号设置为高电平,开始执行内核
内存架构
Tiny GPU的内存系统分为数据内存和程序内存两部分:
- 数据内存:8位寻址(共256行),每行8位数据
- 程序内存:8位寻址(共256行),每行16位数据(对应一条指令)
内存控制器负责管理计算核心对内存的访问请求,根据实际内存带宽限制请求,并将外部内存的响应传回相应的资源。
计算核心
每个计算核心都有一定数量的计算资源,通常围绕其支持的线程数量构建。为了最大化并行性,这些资源需要被优化管理以最大化资源利用率。
在这个简化的GPU中,每个核心一次处理一个线程块,对于块中的每个线程,核心都有专用的算术逻辑单元(ALU)、加载/存储单元(LSU)、程序计数器(PC)和寄存器文件。
指令集架构(ISA)
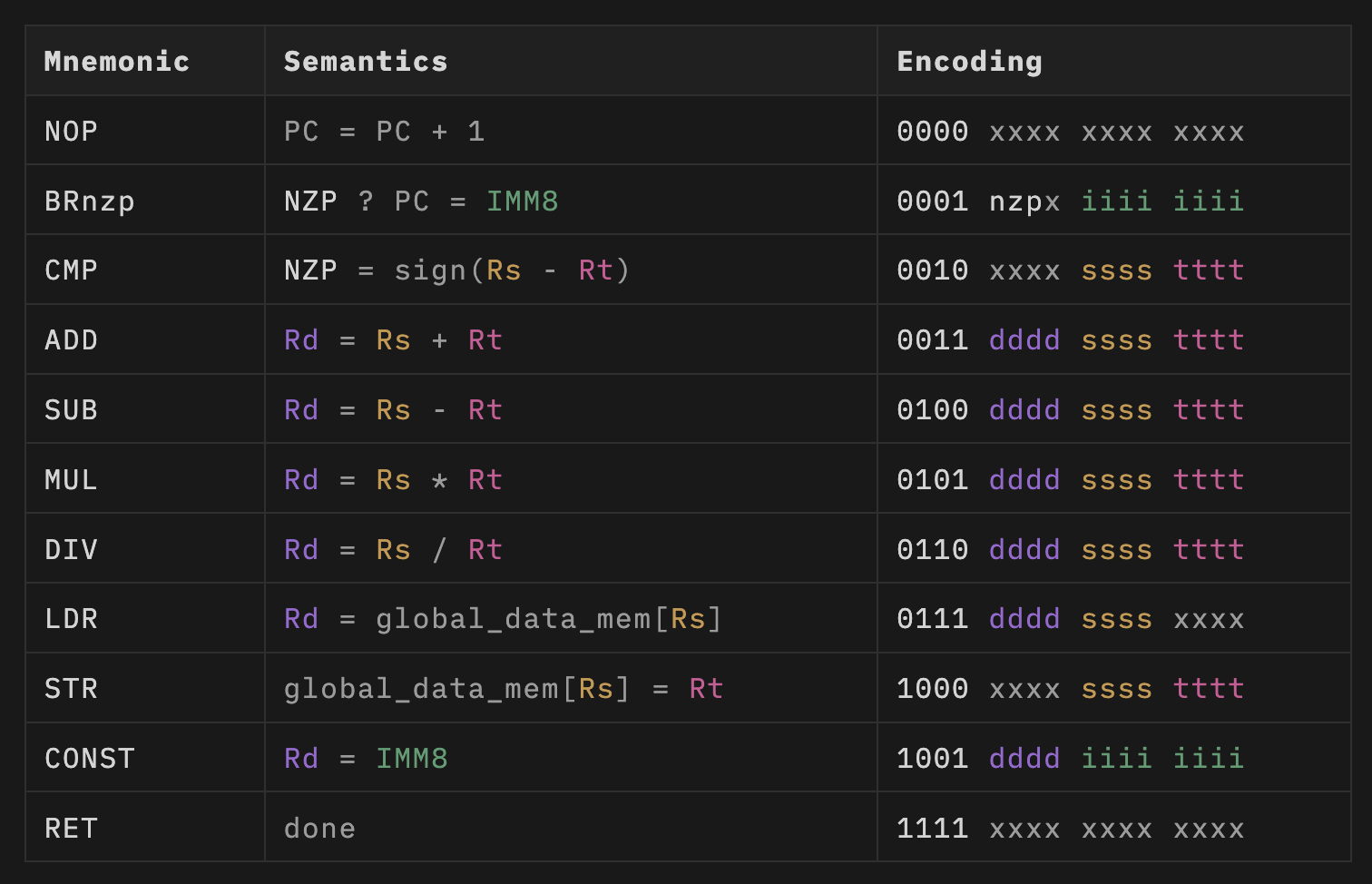
Tiny GPU实现了一个简单的11指令ISA,用于支持矩阵加法和矩阵乘法等简单的概念验证内核。主要包括以下指令:
BRnzp: 分支指令,用于实现循环和条件语句CMP: 比较两个寄存器的值ADD,SUB,MUL,DIV: 基本算术运算LDR: 从全局内存加载数据STR: 将数据存储到全局内存CONST: 将常量值加载到寄存器RET: 表示当前线程执行结束
每个寄存器由4位指定,意味着总共有16个寄存器。其中R0-R12是可读写的通用寄存器,最后3个是只读的特殊寄存器,用于提供%blockIdx、%blockDim和%threadIdx等SIMD关键信息。
执行流程
核心执行流程
每个核心按照以下步骤执行指令:
FETCH: 从程序内存获取下一条指令DECODE: 将指令解码为控制信号REQUEST: 如果需要,从全局内存请求数据WAIT: 等待内存响应(如果适用)EXECUTE: 执行计算UPDATE: 更新寄存器文件和NZP寄存器
线程执行
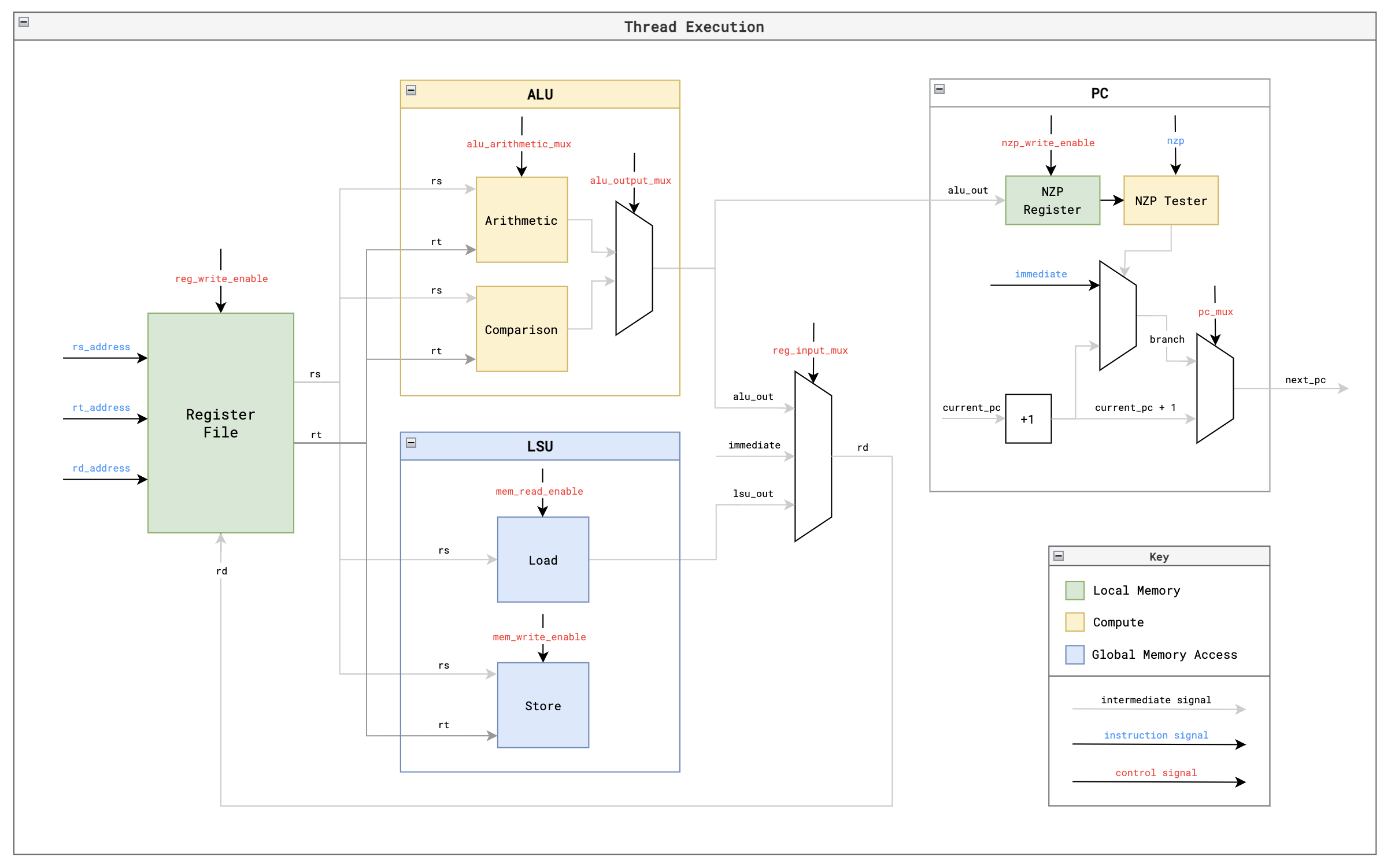
每个核心内的每个线程都遵循上述执行路径,对其专用寄存器文件中的数据执行计算。这与标准CPU的功能非常相似,主要区别在于%blockIdx、%blockDim和%threadIdx值位于每个线程的只读寄存器中,从而实现SIMD功能。
矩阵运算内核
为了展示Tiny GPU的SIMD编程和执行能力,项目实现了矩阵加法和矩阵乘法两个示例内核。
矩阵加法
矩阵加法内核将两个1x8矩阵相加,通过8个独立的线程执行元素级加法。这个演示利用了%blockIdx、%blockDim和%threadIdx寄存器来展示SIMD编程,同时使用了需要异步内存管理的LDR和STR指令。
.threads 8
.data 0 1 2 3 4 5 6 7 ; 矩阵A (1 x 8)
.data 0 1 2 3 4 5 6 7 ; 矩阵B (1 x 8)
MUL R0, %blockIdx, %blockDim
ADD R0, R0, %threadIdx ; i = blockIdx * blockDim + threadIdx
CONST R1, #0 ; baseA (矩阵A基址)
CONST R2, #8 ; baseB (矩阵B基址)
CONST R3, #16 ; baseC (矩阵C基址)
ADD R4, R1, R0 ; addr(A[i]) = baseA + i
LDR R4, R4 ; 从全局内存加载A[i]
ADD R5, R2, R0 ; addr(B[i]) = baseB + i
LDR R5, R5 ; 从全局内存加载B[i]
ADD R6, R4, R5 ; C[i] = A[i] + B[i]
ADD R7, R3, R0 ; addr(C[i]) = baseC + i
STR R7, R6 ; 将C[i]存储到全局内存
RET ; 内核结束
矩阵乘法
矩阵乘法内核将两个2x2矩阵相乘。它执行相关行和列的点积的元素级计算,并使用CMP和BRnzp指令来演示线程内的分支(值得注意的是,所有分支都会收敛,因此该内核可以在当前的Tiny GPU实现上运行)。
.threads 4
.data 1 2 3 4 ; 矩阵A (2 x 2)
.data 1 2 3 4 ; 矩阵B (2 x 2)
MUL R0, %blockIdx, %blockDim
ADD R0, R0, %threadIdx ; i = blockIdx * blockDim + threadIdx
CONST R1, #1 ; 增量
CONST R2, #2 ; N (矩阵内部维度)
CONST R3, #0 ; baseA (矩阵A基址)
CONST R4, #4 ; baseB (矩阵B基址)
CONST R5, #8 ; baseC (矩阵C基址)
DIV R6, R0, R2 ; row = i // N
MUL R7, R6, R2
SUB R7, R0, R7 ; col = i % N
CONST R8, #0 ; acc = 0
CONST R9, #0 ; k = 0
LOOP:
MUL R10, R6, R2
ADD R10, R10, R9
ADD R10, R10, R3 ; addr(A[i]) = row * N + k + baseA
LDR R10, R10 ; 从全局内存加载A[i]
MUL R11, R9, R2
ADD R11, R11, R7
ADD R11, R11, R4 ; addr(B[i]) = k * N + col + baseB
LDR R11, R11 ; 从全局内存加载B[i]
MUL R12, R10, R11
ADD R8, R8, R12 ; acc = acc + A[i] * B[i]
ADD R9, R9, R1 ; 增加k
CMP R9, R2
BRn LOOP ; 当k < N时循环
ADD R9, R5, R0 ; addr(C[i]) = baseC + i
STR R9, R8 ; 将C[i]存储到全局内存
RET ; 内核结束
模拟与执行
Tiny GPU提供了模拟执行上述两个内核的功能。通过运行make test_matadd和make test_matmul命令,可以模拟执行矩阵加法和矩阵乘法内核。执行模拟后,会在test/logs目录下生成一个日志文件,包含初始数据内存状态、内核的完整执行跟踪以及最终数据内存状态。
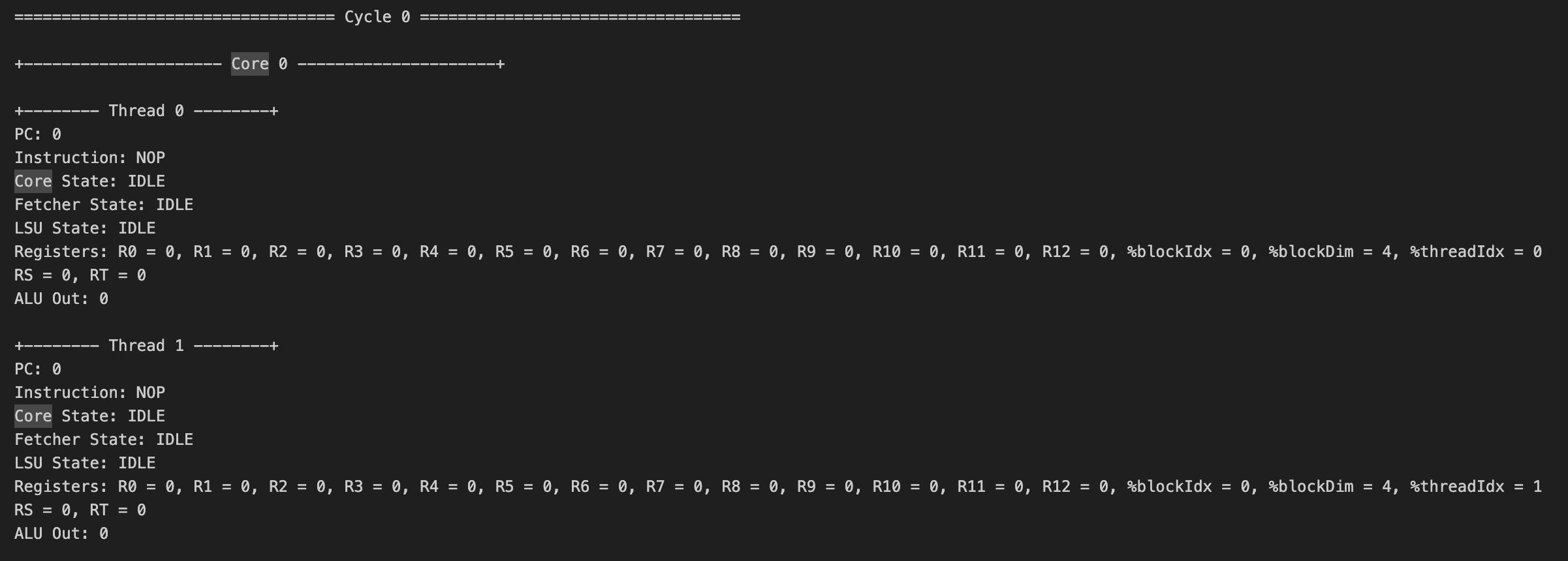
通过查看这些日志,我们可以详细了解内核执行的每一个步骤,包括每个线程的指令执行、寄存器值变化等信息,这对于深入理解GPU的工作原理非常有帮助。
高级功能与未来展望
为了保持简单性,Tiny GPU省略了许多现代GPU中用于提高性能和功能的高级特性。这些特性包括:
- 多层缓存和共享内存
- 内存合并(Memory Coalescing)
- 流水线(Pipelining)
- 线程束调度(Warp Scheduling)
- 分支分歧(Branch Divergence)
- 同步和屏障(Synchronization & Barriers)
这些高级特性是现代GPU性能优化的关键,了解它们的工作原理对于全面掌握GPU技术至关重要。
在未来,Tiny GPU项目计划添加一些基本的高级功能,如简单的指令缓存、基本的分支分歧处理、内存合并和流水线等。此外,还计划优化控制流程和寄存器使用,以提高周期时间,并可能添加简单的图形硬件来演示图形功能。
总结
Tiny GPU项目为我们提供了一个绝佳的机会,让我们能够从底层了解GPU的工作原理。通过学习这个简化的GPU实现,我们可以掌握GPU架构的基本概念、并行计算模型、内存管理策略等核心知识。这不仅有助于我们更好地理解和使用现代GPU,还为进一步研究和优化GPU技术奠定了坚实的基础。
对于有志于深入GPU领域的开发者和研究人员来说,Tiny GPU无疑是一个极具价值的学习资源。它提供了一个清晰、简洁的GPU模型,让我们能够在不被复杂细节困扰的情况下,专注于理解GPU的核心工作原理。
如果你对GPU技术感兴趣,不妨尝试克隆Tiny GPU的代码库,运行示例内核,甚至为项目贡献新的功能。通过实际动手,你将获得更深入的理解和宝贵的经验。让我们一起探索GPU的奥秘,推动图形计算技术的进步!


















