
Tiny GPU:探索图形处理器的内部工作原理
在计算机硬件领域,图形处理器(GPU)一直是一个神秘而复杂的组件。虽然关于GPU编程的资源很多,但要深入了解GPU在硬件层面的工作原理却并不容易。这正是Tiny GPU项目的初衷 - 通过一个最小化的GPU实现,帮助人们从底层理解GPU的核心概念和工作机制。
什么是Tiny GPU?
Tiny GPU是由Adam Majmudar开发的一个用Verilog实现的最小化GPU设计。它专注于突出现代硬件加速器的一般原理,而不是图形特定的硬件细节。通过简化掉生产级图形卡所涉及的大部分复杂性,Tiny GPU让我们能够关注所有现代硬件加速器的核心要素。
这个项目主要探索了以下几个方面:
- 架构 - GPU的架构是什么样的?最重要的元素是什么?
- 并行化 - SIMD(单指令多数据)编程模型如何在硬件中实现?
- 内存 - GPU如何解决有限内存带宽的约束?

Tiny GPU的架构设计
Tiny GPU被设计为一次执行一个内核。其整体架构包括以下几个主要组件:
- 设备控制寄存器 - 存储内核执行的元数据
- 调度器 - 管理线程分配到不同的计算核心
- 可变数量的计算核心
- 数据内存和程序内存的内存控制器
- 缓存
GPU核心
每个GPU核心都有一定数量的计算资源,通常围绕它所能支持的线程数量构建。为了最大化并行性,这些资源需要进行最优管理以实现最高的资源利用率。
在这个简化的GPU中,每个核心一次处理一个线程块,对于块中的每个线程,核心都有专用的ALU、LSU、PC和寄存器文件。管理这些资源上的线程指令执行是GPU中最具挑战性的问题之一。
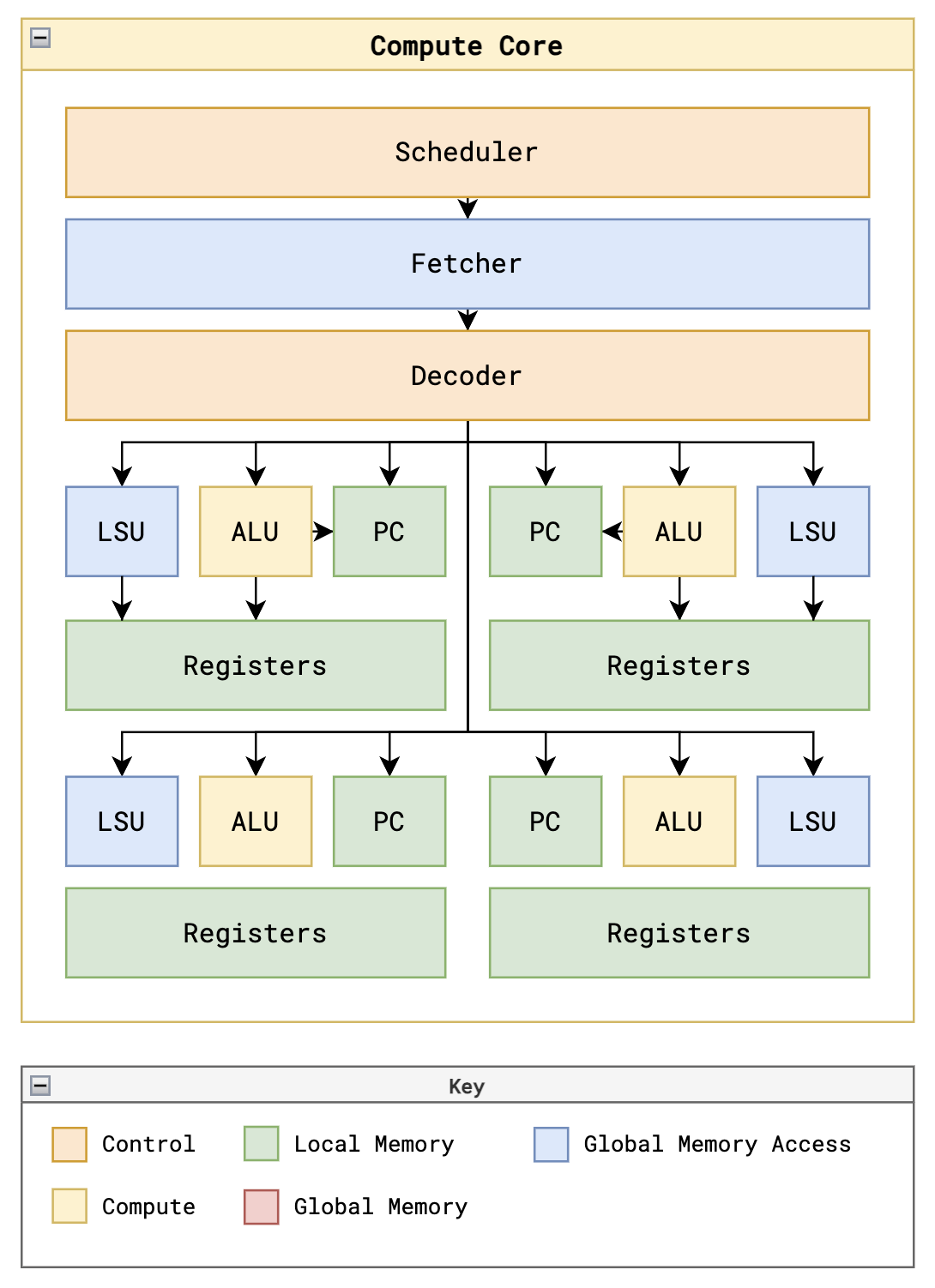
内存系统
Tiny GPU的内存系统包括:
- 全局内存:外部接口,数据内存和程序内存分开
- 内存控制器:管理来自计算核心的内存请求
- 缓存:存储从外部内存检索的数据,以减少重复访问
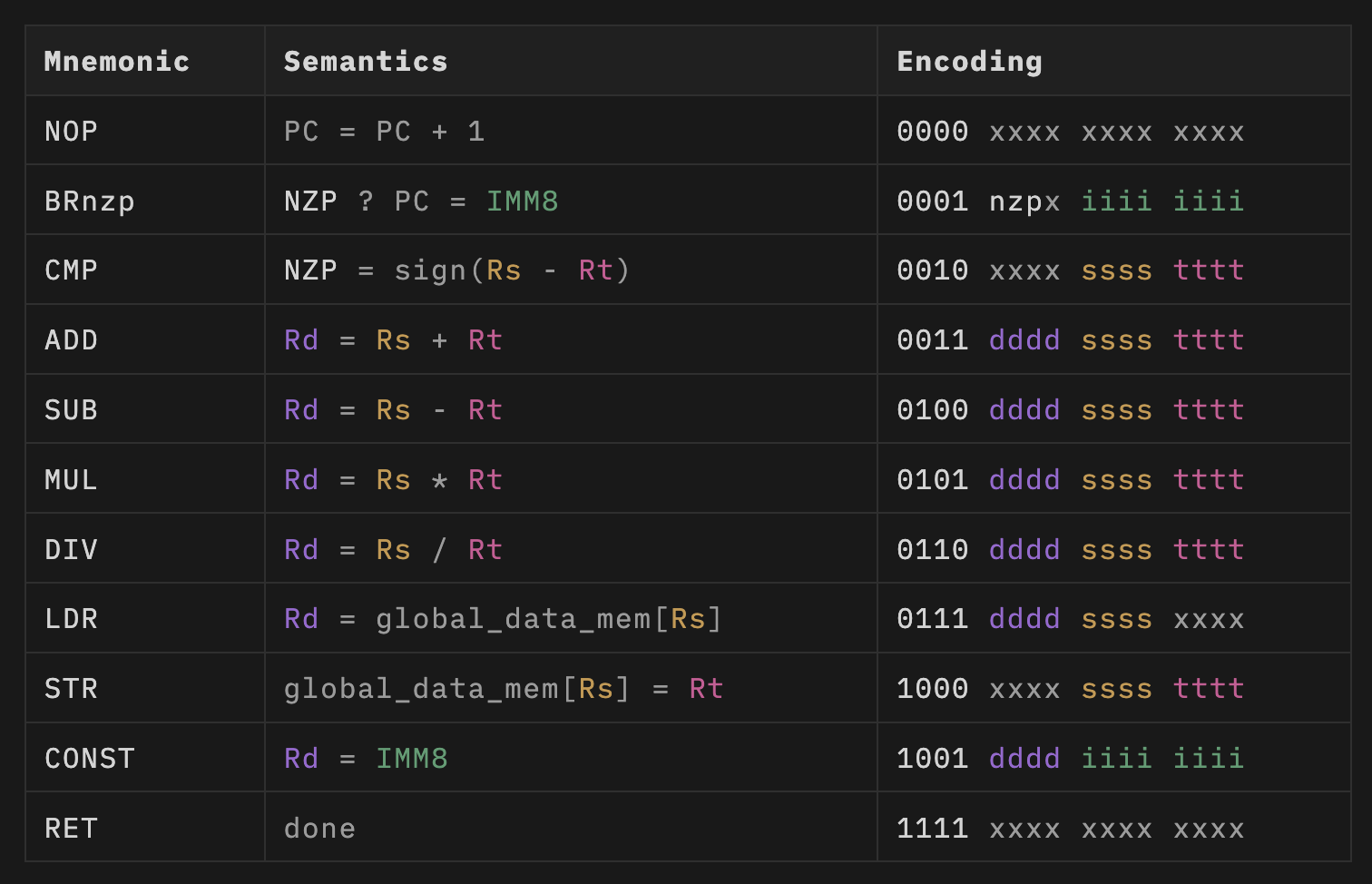
指令集架构(ISA)
Tiny GPU实现了一个简单的11条指令的ISA,用于实现简单的内核,如矩阵加法和矩阵乘法。主要指令包括:
- 分支指令(BRnzp)
- 比较指令(CMP)
- 基本算术运算(ADD, SUB, MUL, DIV)
- 内存加载/存储(LDR, STR)
- 常量加载(CONST)
- 返回指令(RET)
内核执行
Tiny GPU可以执行矩阵加法和矩阵乘法等简单内核。以下是矩阵加法内核的示例代码:
.threads 8
.data 0 1 2 3 4 5 6 7 ; matrix A (1 x 8)
.data 0 1 2 3 4 5 6 7 ; matrix B (1 x 8)
MUL R0, %blockIdx, %blockDim
ADD R0, R0, %threadIdx ; i = blockIdx * blockDim + threadIdx
CONST R1, #0 ; baseA (matrix A base address)
CONST R2, #8 ; baseB (matrix B base address)
CONST R3, #16 ; baseC (matrix C base address)
ADD R4, R1, R0 ; addr(A[i]) = baseA + i
LDR R4, R4 ; load A[i] from global memory
ADD R5, R2, R0 ; addr(B[i]) = baseB + i
LDR R5, R5 ; load B[i] from global memory
ADD R6, R4, R5 ; C[i] = A[i] + B[i]
ADD R7, R3, R0 ; addr(C[i]) = baseC + i
STR R7, R6 ; store C[i] in global memory
RET ; end of kernel
这个内核通过在单独的线程中执行8个元素的加法来将两个1x8矩阵相加。它展示了SIMD编程模型在Tiny GPU上的实现。
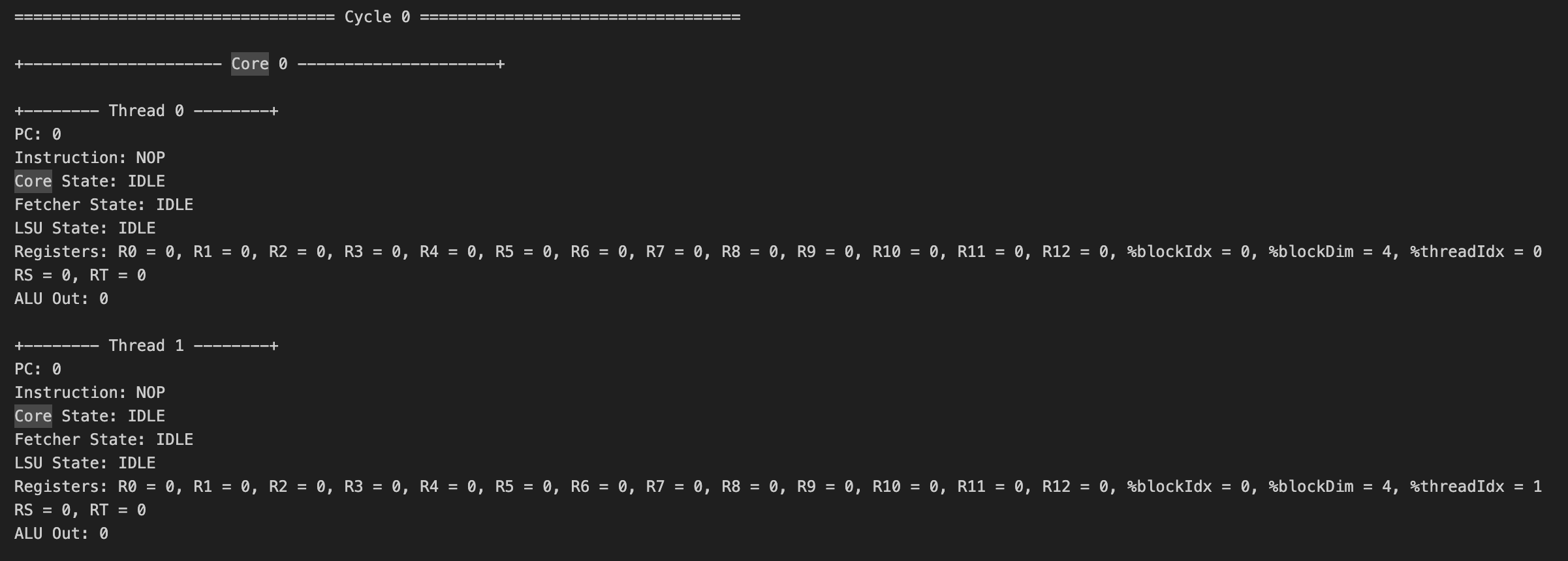
模拟与执行跟踪
Tiny GPU提供了完整的模拟环境,可以模拟上述内核的执行。模拟过程会输出初始数据内存状态、完整的内核执行跟踪以及最终的数据内存状态。这使得我们能够详细观察GPU内核的执行过程。
高级功能与未来展望
虽然Tiny GPU为了简单起见省略了许多现代GPU中的高级功能,但了解这些功能对于全面理解GPU的工作原理非常重要。一些关键的高级功能包括:
- 多层缓存和共享内存
- 内存合并
- 流水线
- 线程束调度
- 分支分歧处理
- 同步与屏障
作者计划在未来对Tiny GPU进行进一步改进,包括:
- 为指令添加简单缓存
- 构建适配器以与Tiny Tapeout 7一起使用GPU
- 添加基本的分支分歧处理
- 添加基本的内存合并
- 添加基本的流水线
- 优化控制流和寄存器使用以提高周期时间
- 编写基本的图形内核或添加简单的图形硬件以演示图形功能
结语
Tiny GPU项目为我们提供了一个独特的机会,让我们能够从底层理解GPU的工作原理。通过简化复杂性并专注于核心概念,它使得学习GPU架构变得更加容易和直观。无论你是硬件工程师、软件开发者还是对计算机架构感兴趣的学生,Tiny GPU都是一个值得深入研究的项目。
如果你对GPU感兴趣,不妨尝试运行Tiny GPU的模拟器,或者为项目贡献自己的改进。通过实践,你将获得对GPU内部工作机制更深入的理解,这对于优化GPU程序或设计下一代硬件加速器都将是宝贵的经验。
让我们一起探索GPU的奥秘,推动计算机图形和并行计算技术的发展!


















