
Transformer-TTS简介
Transformer-TTS是一个基于Transformer网络架构的神经语音合成系统,由Seo等人在2019年提出。它是对传统序列到序列模型如Tacotron的改进,通过使用自注意力机制和前馈神经网络,实现了更快速和高效的文本到语音转换。
Transformer-TTS的主要特点包括:
-
训练速度快:比传统的seq2seq模型如Tacotron快3-4倍,每步训练时间约为0.5秒。
-
合成质量高:生成的语音质量与Tacotron等模型相当。
-
非自回归结构:避免了自回归模型中的错误累积问题。
-
并行计算:利用Transformer的并行特性,可以充分利用GPU加速。
-
可控性强:可以控制生成语音的速度和音高。
下面我们将详细介绍Transformer-TTS的网络结构、训练方法和实验结果。
Transformer-TTS网络结构
Transformer-TTS的整体网络结构如下图所示:
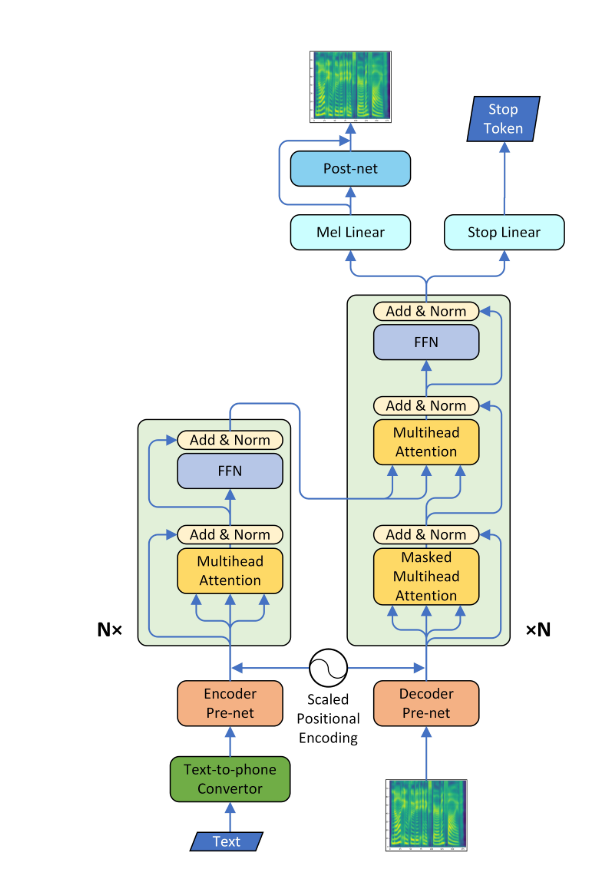
整个网络由以下几个主要部分组成:
-
文本编码器:将输入文本转换为向量表示。
-
Transformer编码器:对文本向量进行编码,捕捉长距离依赖关系。
-
Transformer解码器:根据编码器输出生成梅尔频谱图。
-
后处理网络:将梅尔频谱图转换为线性频谱图。
-
声码器:将频谱图转换为波形。
其中,Transformer编码器和解码器是整个网络的核心,它们采用了多头自注意力机制和前馈神经网络的结构。这种结构使得模型可以并行处理序列数据,大大提高了训练和推理速度。
训练方法
Transformer-TTS的训练分为以下几个步骤:
-
数据预处理:
- 使用LJSpeech数据集,包含13,100对文本和语音样本。
- 将音频文件预处理为梅尔频谱图和线性频谱图。
- 对文本进行标准化和音素转换。
-
训练自回归注意力网络:
- 运行
train_transformer.py脚本。 - 输入为文本,输出为梅尔频谱图。
- 使用teacher forcing策略进行训练。
- 运行
-
训练后处理网络:
- 运行
train_postnet.py脚本。 - 输入为梅尔频谱图,输出为线性频谱图。
- 使用L1和L2损失函数。
- 运行
-
超参数调整:
- 学习率是一个重要参数,初始值设为0.001,采用Noam式预热和衰减策略。
- 梯度裁剪也很重要,设置裁剪阈值为1。
- 位置编码的alpha值会随训练过程动态调整。
训练过程中的损失曲线如下图所示:
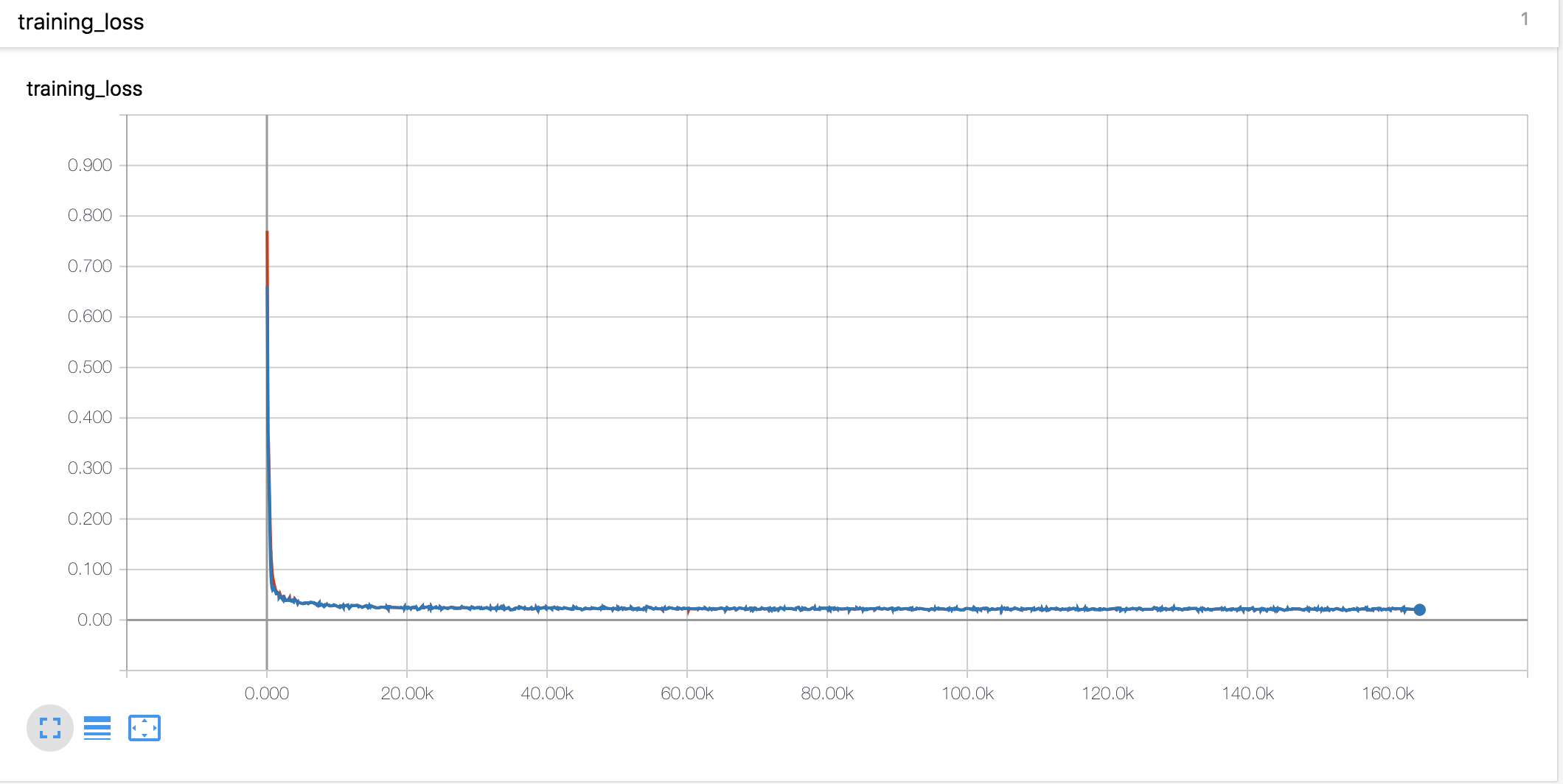
可以看到,模型的损失在训练初期快速下降,之后趋于平稳。整个训练过程大约需要16万步左右。
注意力可视化
Transformer-TTS的一个重要特征是多头注意力机制。通过可视化注意力权重,我们可以了解模型内部的工作原理。下面是编码器自注意力、解码器自注意力和编码器-解码器注意力的可视化结果:

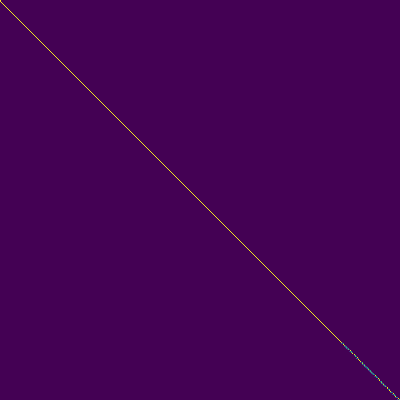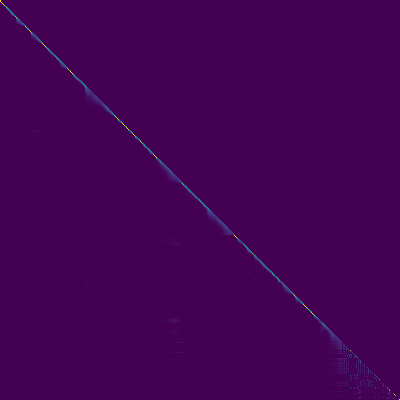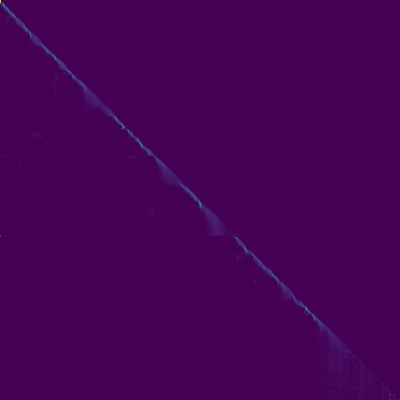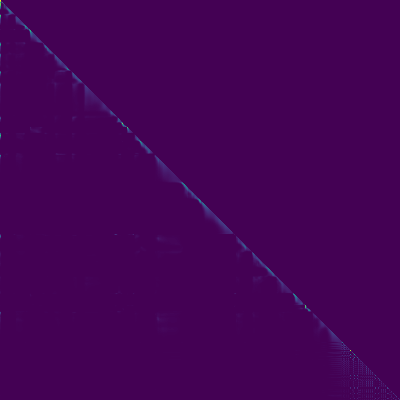

从这些图中我们可以观察到:
-
编码器自注意力:主要关注相邻的几个token,捕捉局部语言特征。
-
解码器自注意力:呈现出明显的对角线模式,表明当前时间步主要依赖于之前的几个时间步。
-
编码器-解码器注意力:也呈现对角线模式,说明解码过程中的每个时间步都主要关注对应的输入文本部分。
这些注意力模式表明,模型成功地学习到了文本和语音之间的对齐关系。
实验结果
Transformer-TTS在LJSpeech数据集上进行了训练和测试。以下是一些主要的实验结果:
-
训练速度:每步训练时间约为0.5秒,比Tacotron等模型快3-4倍。
-
频谱图对比:下图展示了模型预测的梅尔频谱图(上)和真实的梅尔频谱图(下)的对比:


可以看到,预测的频谱图与真实频谱图非常接近,说明模型能够准确地捕捉语音的频率特征。
-
长句子处理:模型在处理长句子时表现略差,这可能是因为Transformer的全局注意力机制在处理很长的序列时效果不佳。
-
控制能力:模型可以通过调整alpha参数来控制生成语音的速度和音高,增加了系统的灵活性。
实现细节
Transformer-TTS的实现主要基于PyTorch框架。以下是一些关键的实现细节:
-
位置编码:使用正弦和余弦函数生成位置编码,并引入可学习的alpha参数进行缩放。
-
多头注意力:实现了自注意力和交叉注意力机制,头数设置为4。
-
前馈网络:使用两层全连接网络,中间使用ReLU激活函数。
-
残差连接和层归一化:在每个子层后使用残差连接和层归一化,有助于训练更深的网络。
-
解码器预网络:在解码器输入前使用一个简单的前馈网络,有助于提高生成质量。
-
后处理网络:使用CBHG(1-D卷积bank + highway network + bi-directional GRU)结构,将梅尔频谱图转换为线性频谱图。
-
Griffin-Lim算法:用于将频谱图转换为波形,虽然质量不如WaveNet等神经网络声码器,但速度更快。
结论与展望
Transformer-TTS成功地将Transformer架构应用于语音合成任务,实现了快速高效的文本到语音转换。与传统的序列到序列模型相比,它具有训练速度快、并行度高、可控性强等优点。
然而,Transformer-TTS仍然存在一些局限性和可改进之处:
-
长句子处理:需要改进模型在处理长文本时的表现。
-
声码器:可以尝试集成更先进的神经网络声码器,如WaveNet或WaveRNN,以提高音质。
-
多说话人支持:目前模型仅支持单一说话人,未来可以扩展到多说话人场景。
-
情感控制:增加对语音情感和风格的精细控制。
-
计算效率:虽然比Tacotron快,但仍有优化空间,特别是在推理阶段。
总的来说,Transformer-TTS为神经网络语音合成领域带来了新的思路和方法。随着进一步的研究和改进,它有望在实际应用中发挥更大的作用,为更自然、更高效的人机语音交互提供支持。
参考资源
- Transformer-TTS GitHub仓库
- Neural Speech Synthesis with Transformer Network论文
- LJSpeech数据集
- Tacotron: Towards End-to-End Speech Synthesis
- Attention Is All You Need
通过深入了解Transformer-TTS,我们可以看到它如何巧妙地将Transformer的强大能力应用于语音合成任务。这不仅推动了TTS技术的发展,也为其他序列生成任务提供了新的思路。随着深度学习和自然语言处理技术的不断进步,我们可以期待在不久的将来,更加自然、流畅、富有表现力的语音合成系统将会出现。










