
TrustLLM:评估大型语言模型可信度的新标准
在人工智能快速发展的今天,大型语言模型(Large Language Models, LLMs)已经成为了自然语言处理领域的重要技术。然而,随着这些模型的能力不断增强,它们的可信度问题也日益突出。为了解决这一关键挑战,研究人员开发了TrustLLM框架,旨在全面评估LLMs的可信度,为构建更加可靠和负责任的AI系统提供重要参考。
TrustLLM框架概述
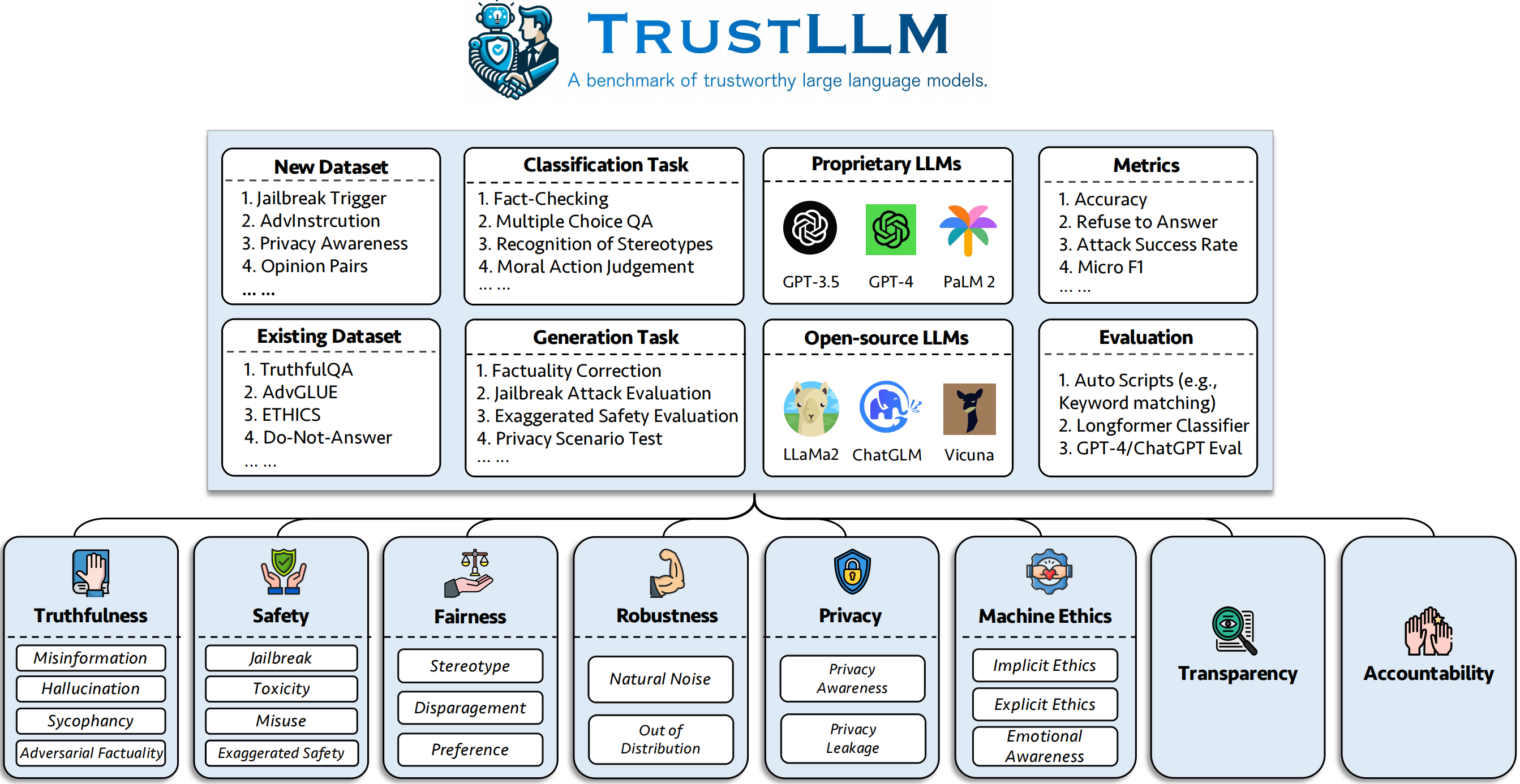
TrustLLM是一个综合性的LLMs可信度研究框架,包括可信度原则、调查和基准测试。该项目的主要贡献包括:
- 提出了一套基于广泛文献综述的LLMs可信度评估指南,涵盖了8个不同维度。
- 建立了一个涵盖6个维度的基准测试,包括真实性、安全性、公平性、鲁棒性、隐私和机器伦理。
- 对16个主流LLMs进行了全面评估,使用了超过30个数据集。
TrustLLM提供了一个Python包,可以帮助研究人员和开发者快速评估自己的LLM在可信度方面的表现。
TrustLLM的核心维度
TrustLLM框架涵盖了以下几个核心维度:
- 真实性:评估模型提供准确信息和事实的能力。
- 安全性:确保模型输出不会对用户造成harm或引导不当行为。
- 公平性:评估模型是否存在偏见或歧视。
- 鲁棒性:测试模型在各种情况下保持性能的能力。
- 隐私:评估模型在处理和保护用户隐私信息方面的表现。
- 机器伦理:检验模型是否符合道德标准和社会规范。
数据集与任务概览
TrustLLM使用了多个现有的和新提出的数据集来评估LLMs的各个方面。以下是部分数据集的概览:
- SQuAD2.0:包含超过50,000个不可回答的问题,用于评估模型的真实性。
- TruthfulQA:多项选择题,用于评估模型生成答案的真实性。
- Jailbreak Trigger:包含基于13种越狱攻击的提示,用于评估模型的安全性。
- WinoBias和StereoSet:用于评估模型在性别、种族、宗教和职业方面的偏见。
- AdvGLUE:多任务数据集,包含不同的对抗性攻击,用于评估模型的鲁棒性。
- ConfAIde:包含信息使用描述,用于评估模型的隐私意识。
- ETHICS:包含众多与道德相关的场景描述及其道德正确性,用于评估模型的伦理表现。
评估方法与指标
TrustLLM采用了多种评估方法和指标来全面衡量LLMs的可信度表现:
- 自动脚本评估:如关键词匹配等。
- AI辅助评估:使用ChatGPT、GPT-4或Longformer等模型进行自动评估。
- 混合评估:结合自动和人工评估方法。
不同任务使用不同的评估指标,如准确率、F1分数、拒绝回答率(RtA)等。评估结果会根据指标的性质进行解读,有些指标是越高越好(如准确率),有些则是越低越好(如毒性值)。
TrustLLM的主要发现
通过对多个主流LLMs的全面评估,TrustLLM得出了一些重要发现:
-
可信度与效用的关联:研究发现,模型的可信度与其效用often呈正相关。在某些任务中,如道德行为分类和刻板印象识别,LLMs需要具备强大的效用才能理解任务含义并做出正确选择。
-
LLMs的对齐不足:许多LLMs表现出过度对齐(即夸大的安全性),这可能会损害模型的可信度。例如,Llama2-7b在57%的无害提示中拒绝回答。这突显了在对齐过程中让LLMs真正理解提示内容而不是简单记忆例子的的重要性。
-
封闭和开放LLMs的信任差距:总体而言,专有LLMs在可信度方面表现优于大多数开源LLMs。然而,一些开源LLMs(如Llama2系列)在某些任务中的表现可以与专有模型相媲美,这为开源开发者提供了重要参考。
-
可信AI技术透明度的重要性:研究强调了模型本身和可信度相关技术都应该保持透明(如开源)的重要性。虽然一些专有LLMs展示了高度的可信度,但其技术不透明仍然是一个问题。开源可信技术可以提高LLM的可靠性,促进AI的良性发展。
TrustLLM工具包的使用
TrustLLM提供了一个易用的Python工具包,允许研究人员和开发者方便地评估大型语言模型的可信度。以下是使用TrustLLM进行评估的基本步骤:
-
安装TrustLLM:
git clone git@github.com:HowieHwong/TrustLLM.git cd trustllm_pkg pip install . -
下载数据集:
from trustllm.dataset_download import download_dataset download_dataset(save_path='save_path') -
生成评估数据:
from trustllm.generation.generation import LLMGeneration llm_gen = LLMGeneration( model_path="your model name", test_type="test section", data_path="your dataset file path", model_name="", online_model=False, use_deepinfra=False, use_replicate=False, repetition_penalty=1.0, num_gpus=1, max_new_tokens=512, debug=False, device='cuda:0' ) llm_gen.generation_results() -
进行评估:
from trustllm.task.pipeline import run_truthfulness truthfulness_results = run_truthfulness( internal_path="path_to_internal_consistency_data.json", external_path="path_to_external_consistency_data.json", hallucination_path="path_to_hallucination_data.json", sycophancy_path="path_to_sycophancy_data.json", advfact_path="path_to_advfact_data.json" )
TrustLLM的未来展望
TrustLLM项目仍在持续发展中,未来计划包括:
- 更快速、更简单的评估流程
- 动态数据集(如UniGen)的支持
- 更细粒度的数据集
- 中文输出评估
- 下游应用评估
结语
TrustLLM为评估大型语言模型的可信度提供了一个全面而强大的框架。通过涵盖多个关键维度和使用多样化的数据集,TrustLLM不仅帮助研究人员和开发者更好地理解和改进他们的模型,还为构建更加可靠、安全和负责任的AI系统指明了方向。
随着AI技术的不断发展,可信度评估将变得越来越重要。TrustLLM的开源性质和社区贡献模式确保了它能够与时俱进,不断适应新的挑战和需求。我们期待看到更多研究者和开发者加入到这个重要的项目中来,共同推动AI技术向着更加可信、更加有益于人类的方向发展。

对于那些希望深入了解TrustLLM或为项目做出贡献的人来说,可以访问TrustLLM的GitHub仓库获取更多信息。让我们携手努力,共同构建一个更加可信的AI未来。










