
UltraChat: 提升对话模型性能的关键数据集
在人工智能技术快速发展的今天,像ChatGPT这样的大型语言模型(LLM)展现出了强大的对话能力,引发了广泛关注。然而,如何进一步提升开源对话模型的性能,一直是学术界和工业界共同关注的话题。近期,清华大学自然语言处理实验室(THUNLP)推出的UltraChat数据集及其衍生模型UltraLM,在这一领域取得了重要突破。
UltraChat数据集的特点与优势
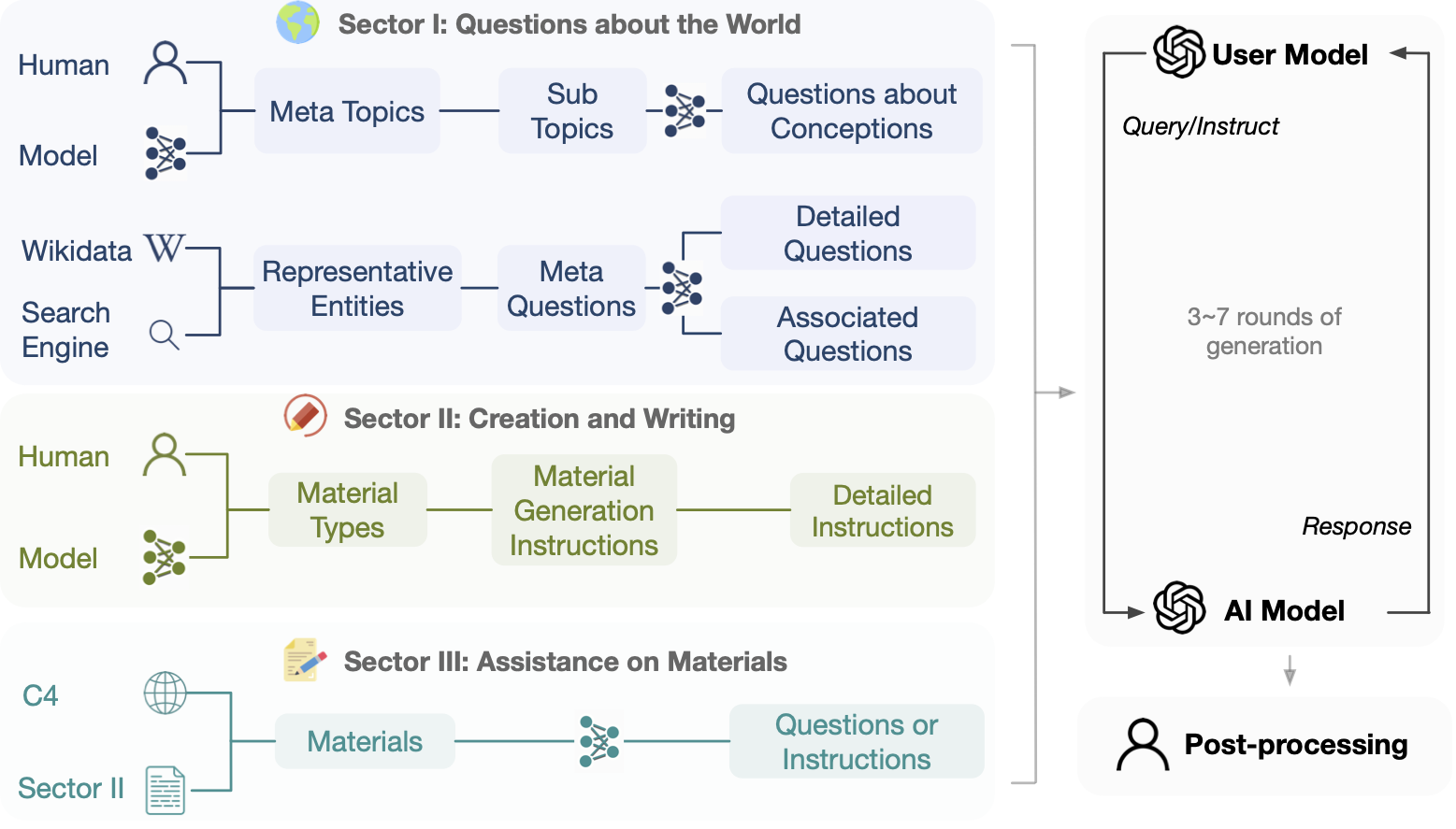
UltraChat是一个包含150万条高质量多轮对话的大规模数据集。它具有以下几个显著特点:
-
规模庞大: 150万条多轮对话,覆盖面广泛。
-
多样性强: 涵盖世界知识、创作写作、现有材料处理等多个领域。
-
高质量: 采用系统化设计,确保对话质量。
-
多轮交互: 每条对话包含3-7轮交互,更接近真实场景。
-
无人工参与: 完全由AI模型生成,避免了人工标注的局限性。
UltraChat的创新之处在于其数据生成方法。研究团队采用了一套复杂的框架,利用多个LLM模型交互生成对话数据。这种方法不仅提高了效率,还保证了数据的多样性和质量。
UltraChat的应用:UltraLM模型
基于UltraChat数据集,研究团队训练了UltraLM模型。这个模型在多项评测中表现优异:
-
在AlpacaEval评测中,UltraLM-13B在开源模型中排名第一,在所有模型中排名第四。
-
在Evol-instruct评测中,UltraLM表现优于多个知名开源模型。
-
在研究团队自行设计的评测集上,UltraLM同样展现出了优秀的性能。
这些结果充分证明了UltraChat数据集在提升对话模型性能方面的巨大潜力。
UltraChat的开源与影响
THUNLP团队秉持开源精神,将UltraChat数据集完全开放给研究社区使用。这一举措无疑将推动对话AI技术的进一步发展。研究人员可以通过以下方式获取和使用UltraChat:
-
在Hugging Face上直接下载数据集。
-
使用项目提供的训练代码来复现UltraLM模型。
-
探索UltraChat的GitHub仓库获取更多信息和资源。
UltraChat的未来展望
尽管UltraChat已经取得了显著成果,但对话AI领域仍有巨大的发展空间。未来,我们可以期待:
-
数据集的进一步扩充和优化,覆盖更多专业领域。
-
结合最新的模型架构,开发性能更强的对话模型。
-
探索将UltraChat应用于特定领域的对话系统,如教育、医疗等。
-
研究如何提高对话模型的可解释性和可控性。
结语
UltraChat的出现标志着对话AI研究进入了一个新阶段。它不仅为研究人员提供了宝贵的数据资源,也为开发更强大、更智能的对话系统铺平了道路。随着技术的不断进步,我们有理由相信,未来的对话AI将更加贴近人类的交互需求,为各行各业带来革命性的变革。









