UniCATS-CTX-vec2wav: 一个统一的上下文感知文本转语音框架中的声学上下文感知声码器
 Ray
RayUniCATS-CTX-vec2wav:声学上下文感知声码器
UniCATS-CTX-vec2wav是一个创新的声码器系统,是UniCATS统一上下文感知文本转语音框架中的重要组成部分。它由X-LANCE团队开发,旨在利用声学上下文信息来生成高质量的语音输出。
项目概述
UniCATS-CTX-vec2wav是AAAI 2024论文《UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding》中提出的声码器模型的官方实现。该项目的主要目标是通过利用声学上下文信息来改进语音合成的质量和自然度。
CTX-vec2wav声码器与CTX-txt2vec声学模型配合使用,共同构成了UniCATS框架。CTX-txt2vec负责从输入文本预测语义标记,而CTX-vec2wav则将这些语义标记转换为波形,同时考虑声学上下文信息。
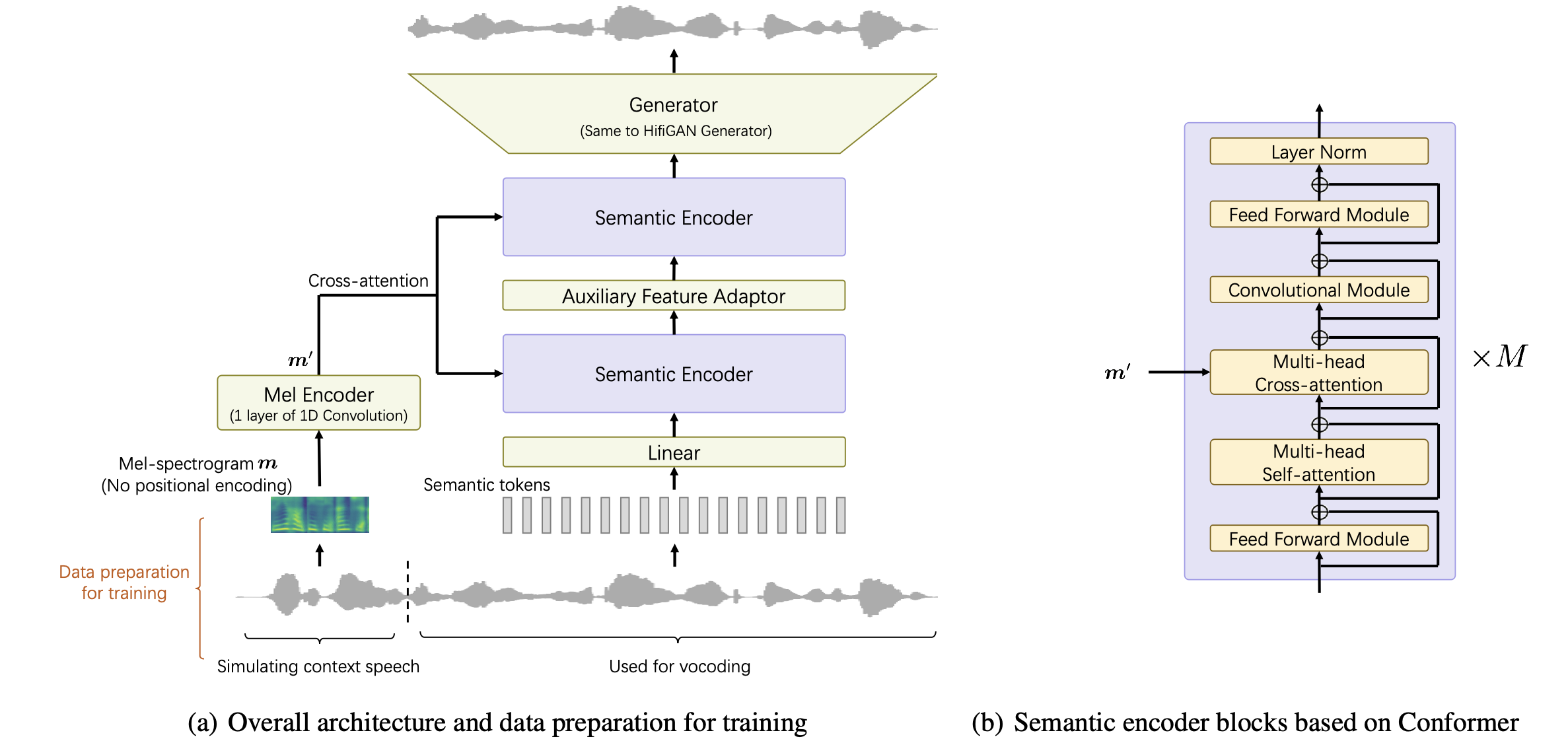
主要特性
-
声学上下文感知: CTX-vec2wav能够利用声学上下文信息来生成更自然、连贯的语音。
-
语音连续性与编辑: 该模型支持语音连续生成和编辑,可以无缝衔接上下文语音。
-
高质量语音重建: 在从语义标记重建语音方面,CTX-vec2wav的表现优于HifiGAN和AudioLM等模型。
-
灵活的采样率: 提供16kHz和24kHz两个版本的预训练模型,适应不同的应用场景。
-
多GPU训练支持: 自动处理多GPU训练,提高训练效率。
环境配置
CTX-vec2wav在Linux环境下的Python 3.9版本上进行了测试。推荐使用Conda创建虚拟环境:
conda create -n ctxv2w python=3.9 conda activate ctxv2w pip install -r requirements.txt source path.sh
推理过程
对于已经在data/目录中注册的语音,可以通过以下命令进行推理:
bash run.sh --stage 3 --stop_stage 3
您还可以创建子集并在其上执行推理:
subset_data_dir.sh data/eval_all 200 data/eval_subset bash run.sh --stage 3 --stop_stage 3 --eval_set "eval_subset"
训练过程
在开始训练之前,需要正确构建data和feats目录。训练命令如下:
bash run.sh --stage 2 --stop_stage 2
这将在exp/train_all_ctxv2w.v1目录下创建日志文件。如果设置了$CUDA_VISIBLE_DEVICES环境变量,脚本会自动处理多GPU训练。
预训练模型
项目提供了两个版本的预训练模型参数:
这两个版本的主要区别在于HifiGAN生成器中的上采样率不同。
研究影响
UniCATS-CTX-vec2wav在语音合成领域展现了promising的结果:
-
在语音重建任务中,它的表现优于HifiGAN和AudioLM等先进模型。
-
作为UniCATS框架的一部分,它在语音连续生成和编辑任务中达到了state-of-the-art的性能。
-
通过利用声学上下文信息,该模型能够生成更加自然、连贯的语音输出。
总结
UniCATS-CTX-vec2wav作为一个创新的声学上下文感知声码器,为语音合成领域带来了新的可能性。它不仅提高了语音质量,还增强了语音编辑和连续生成的能力。随着进一步的研究和应用,这项技术有望在各种语音相关应用中发挥重要作用,如语音助手、有声书籍生成等领域。
研究人员和开发者可以利用UniCATS-CTX-vec2wav来探索更加自然、富有表现力的语音合成方法,为用户提供更优质的语音交互体验。同时,该项目的开源性质也为整个语音合成社区提供了宝贵的资源,促进了相关技术的进步和创新。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率�纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号