
Verba: 智能检索增强生成的开源助手
在当今信息爆炸的时代,如何快速准确地从海量数据中检索并生成有价值的信息成为了一个巨大的挑战。为了解决这个问题,Weaviate公司开发了一款名为Verba的开源聊天机器人,它基于检索增强生成(RAG)技术,为用户提供了一种智能、高效的信息处理方式。
Verba简介
Verba是一款功能强大的个人助手,它利用检索增强生成(RAG)技术来查询和交互用户的数据。无论是本地部署还是云端部署,Verba都能帮助用户解决文档相关的问题,交叉引用多个数据点,或从现有知识库中获取洞察。Verba结合了最先进的RAG技术与Weaviate的上下文感知数据库,用户可以根据个人用例选择不同的RAG框架、数据类型、分块和检索技术以及LLM提供商。
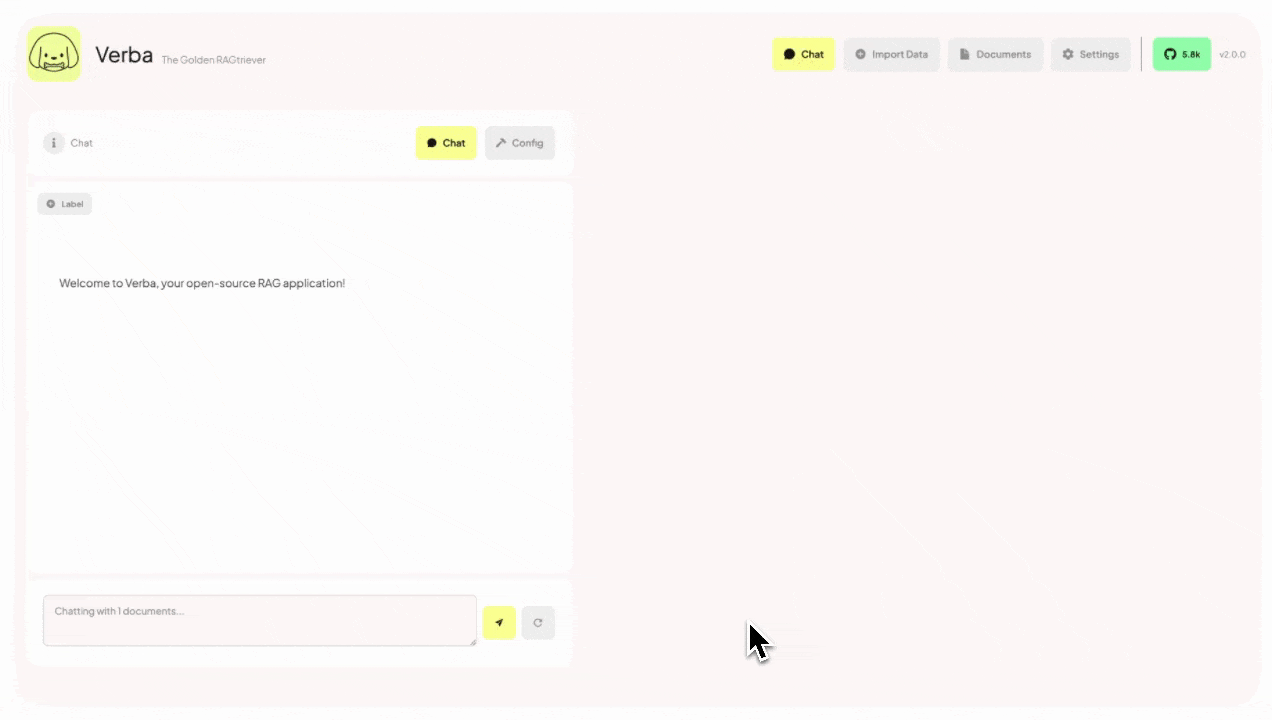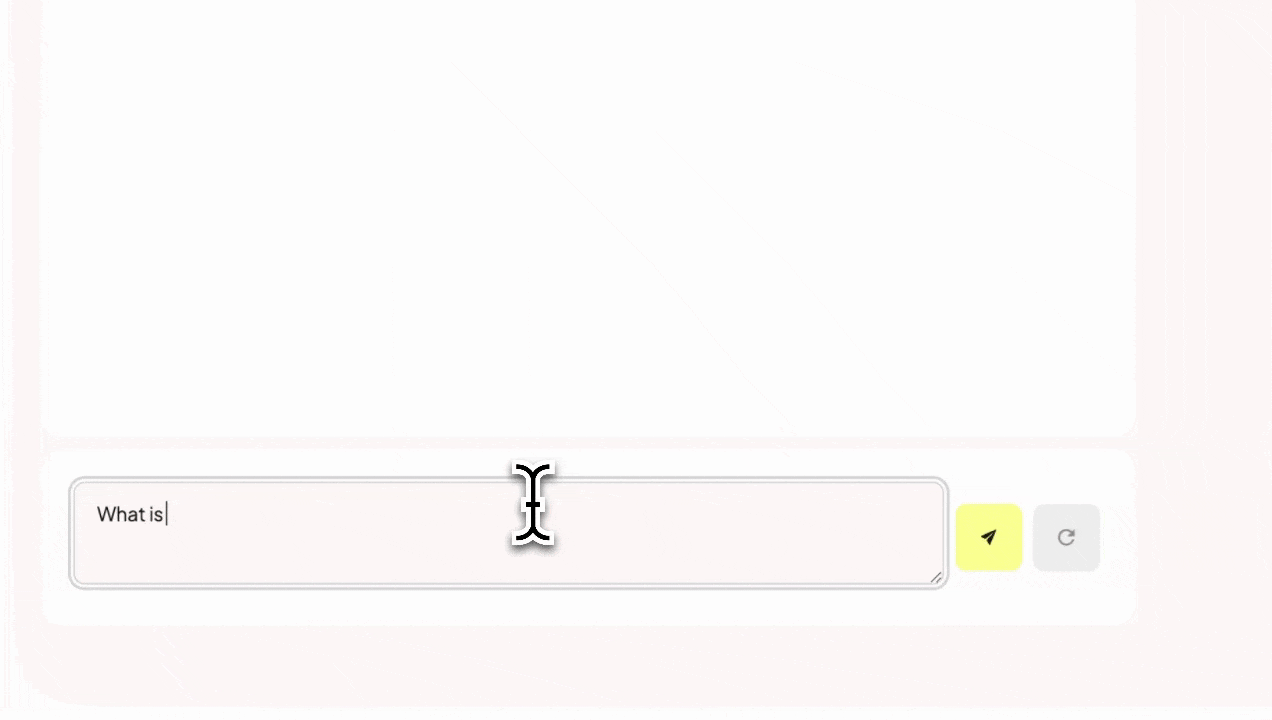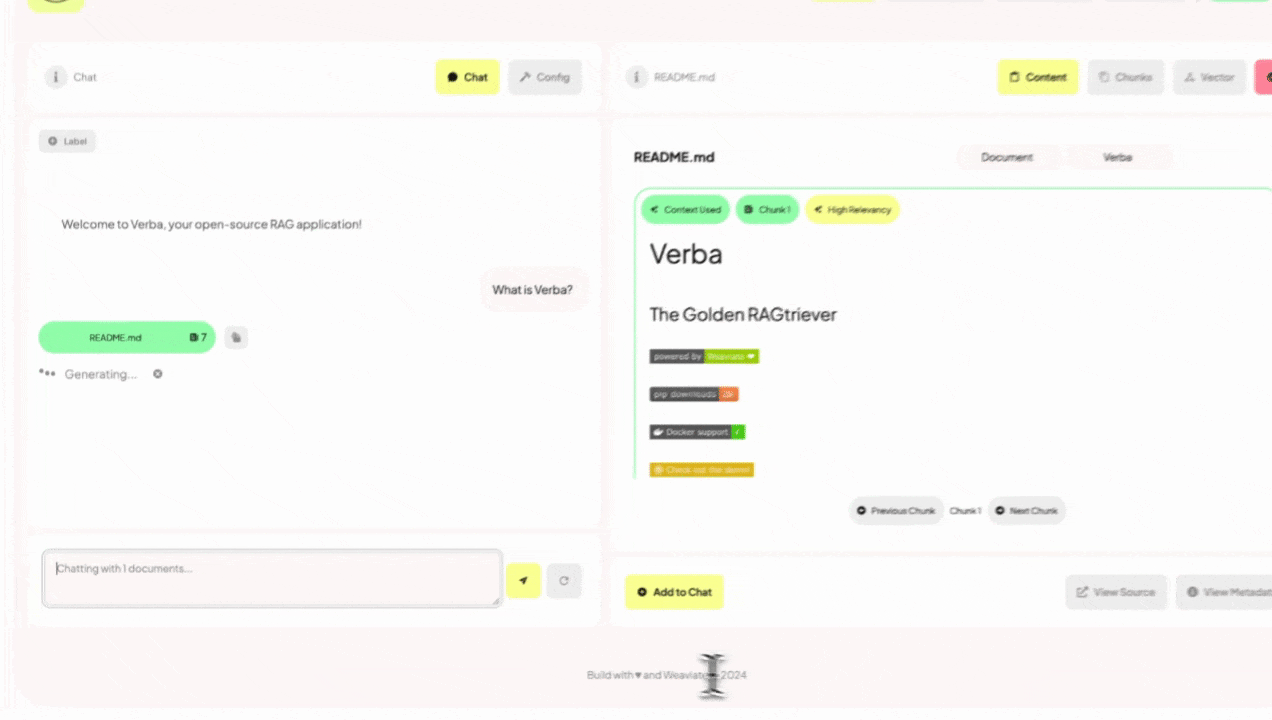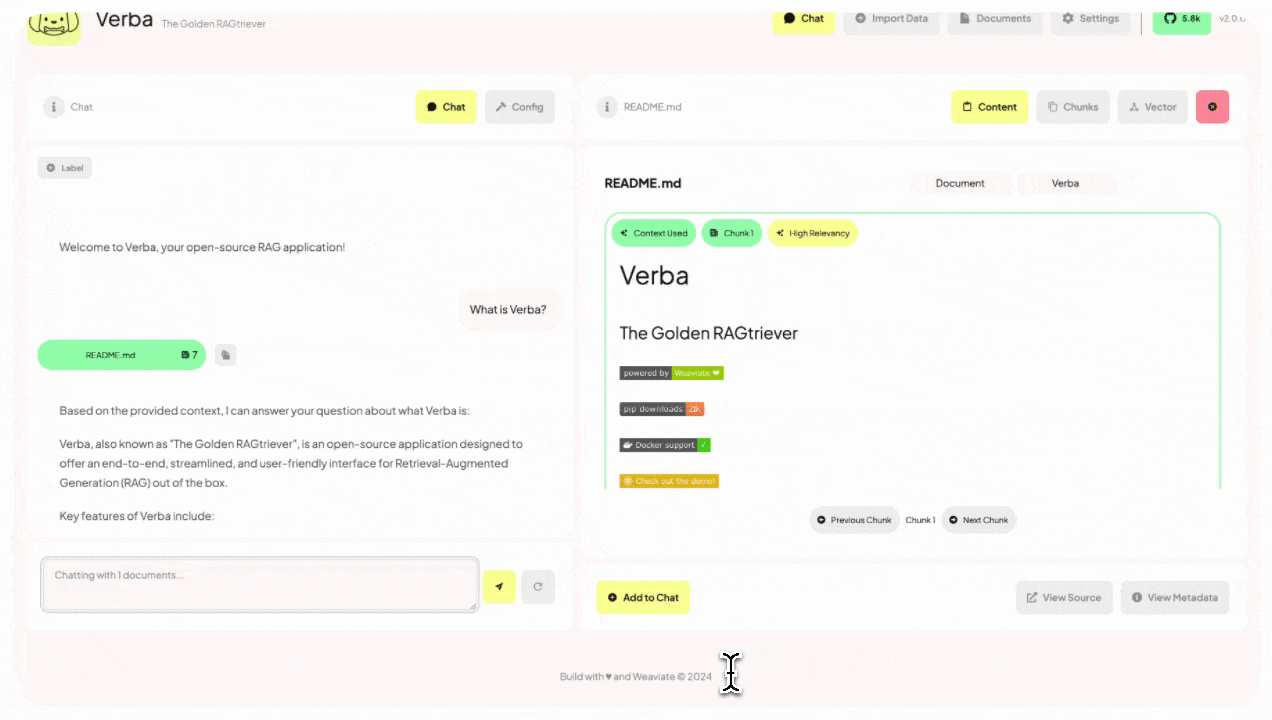
Verba的主要特性
Verba提供了丰富的功能,使其成为一个全面而强大的RAG聊天机器人解决方案:
-
多样化的模型支持: Verba支持多种模型,包括Ollama的本地模型、HuggingFace的本地嵌入模型,以及Cohere、Anthropic和OpenAI的云端模型。
-
广泛的嵌入支持: 除了上述模型外,Verba还支持Weaviate、SentenceTransformers和VoyageAI的嵌入模型。
-
多种数据源支持: Verba可以处理多种数据格式,包括PDF、CSV/XLSX、.DOCX文件,还可以从GitHub和GitLab导入文件,甚至可以通过Firecrawl抓取网页。
-
先进的RAG特性: Verba具备混合搜索、自动完成建议、过滤、可定制元数据、异步摄取等功能,未来还计划添加高级查询、重排序和RAG评估等特性。
-
多样化的分块技术: Verba支持多种文本分块技术,包括基于标记、句子、语义的分块,以及针对HTML、Markdown、代码和JSON文件的特殊分块方法。
-
灵活的部署选项: Verba支持通过Docker部署,前端完全可定制,还提供了3D向量查看器。
-
支持多种RAG库: 目前支持LangChain,未来计划支持Haystack和LlamaIndex。
Verba的工作原理
Verba的工作流程主要包括以下几个步骤:
-
数据导入: 用户可以通过"Import Data"功能添加各种格式的文件或URL。Verba支持多种数据源,包括本地文件、GitHub/GitLab仓库,以及网页爬取。
-
数据处理: Verba使用先进的分块技术将导入的数据分割成适合处理的小块。这些技术包括基于标记、句子和语义的分块,以及针对特定文件类型(如HTML、Markdown、代码文件)的专门分块方法。
-
向量化: 使用选定的嵌入模型将文本块转换为向量表示。Verba支持多种嵌入模型,包括来自Weaviate、Ollama、HuggingFace、Cohere、VoyageAI和OpenAI的模型。
-
索引和存储: 处理后的向量数据被存储在Weaviate的上下文感知数据库中,以便快速检索。
-
查询处理: 当用户提出问题时,Verba首先将问题转换为向量,然后在数据库中检索最相关的文本块。
-
生成回答: 使用选定的语言模型(如OpenAI的GPT模型或Anthropic的Claude模型)基于检索到的相关文本块生成回答。
-
结果展示: Verba将生成的回答连同相关的文本块一起呈现给用户,提供了答案的来源和上下文。
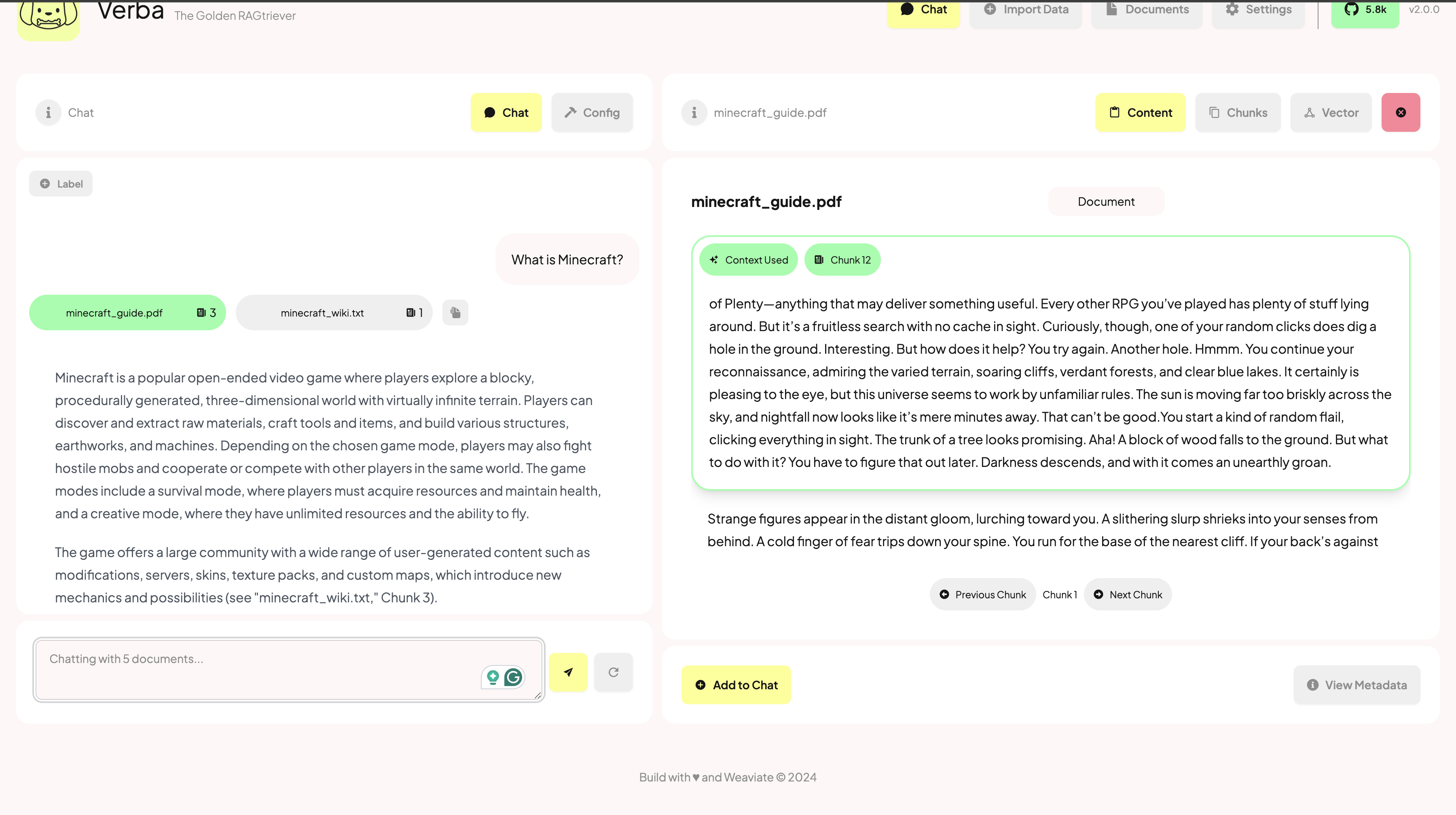
Verba的部署和使用
Verba提供了多种部署选项,以满足不同用户的需求:
-
通过pip安装: 这是最简单的方法,适合快速试用或小规模部署。
-
从源代码构建: 对于需要自定义或深入了解Verba的用户,可以选择从源代码构建。
-
使用Docker部署: 这种方法适合需要隔离环境或在多种平台上一致部署的情况。
无论选择哪种方式,用户都需要设置必要的API密钥,如Weaviate、OpenAI、Anthropic等服务的密钥。Verba支持通过.env文件或环境变量设置这些密钥。
使用Verba的基本步骤如下:
- 导入数据: 通过Verba的界面上传文件或添加URL。
- 配置RAG管道: 在"Config"标签页中选择合适的嵌入模型、语言模型和其他参数。
- 开始对话: 在聊天界面中提问,Verba会基于导入的数据生成答案。
Verba的优势和应用场景
Verba作为一个强大的RAG聊天机器人,具有以下优势:
-
开源和可定制: 作为开源项目,Verba允许用户根据自己的需求进行修改和扩展。
-
灵活的部署选项: 支持本地部署和云端部署,满足不同的安全和性能需求。
-
广泛的模型和数据源支持: 兼容多种流行的AI模型和数据格式,增强了适用性。
-
先进的RAG技术: 利用最新的检索增强生成技术,提高了信息检索和生成的质量。
-
用户友好的界面: 提供直观的Web界面,使非技术用户也能轻松使用。
Verba可以应用于多种场景,例如:
- 知识管理: 企业可以用Verba构建智能知识库,快速检索和生成内部文档的信息。
- 客户服务: 作为智能客服助手,Verba可以基于公司的产品手册和FAQ快速回答客户询问。
- 研究辅助: 研究人员可以用Verba快速分析和综合大量学术文献。
- 个人助理: 个人用户可以用Verba管理和查询自己的笔记、文档等个人信息。
Verba的未来发展
作为一个活跃的开源项目,Verba正在不断发展和改进。未来的发展方向包括:
- 支持多模态数据,如图像和音频。
- 添加更多高级RAG功能,如任务委派和结果重排序。
- 集成更多的RAG库,如Haystack和LlamaIndex。
- 改进评估工具,帮助用户优化RAG管道。
结语
Verba代表了RAG技术在实际应用中的一个重要里程碑。它不仅为开发者和研究人员提供了一个强大的工具,也为普通用户提供了一种智能、高效的信息处理方式。随着AI技术的不断发展,我们可以期待Verba在未来会变得更加强大和易用,为更广泛的应用场景提供解决方案。
无论你是企业用户、研究人员还是个人爱好者,Verba都为你提供了一个探索和利用RAG技术的绝佳平台。通过Verba,我们可以更好地驾驭信息海洋,从海量数据中提取有价值的洞察。让我们一起期待Verba的未来发展,见证AI技术如何继续改变我们与信息交互的方式。









