
Video Diffusion Models: 突破性的视频生成技术
近年来,人工智能在图像生成领域取得了巨大进展,但高质量视频的生成仍然是一个具有挑战性的任务。最近,来自Google Research的研究人员提出了一种新的视频生成模型 - Video Diffusion Models,在视频生成领域取得了突破性进展。
模型架构与创新
Video Diffusion Models是基于扩散模型(Diffusion Models)的视频生成技术。它采用了一种自然的架构扩展,可以同时处理图像和视频数据:
-
使用分解的时空U-Net作为backbone,可以灵活处理不同长度的序列。
-
联合训练图像和视频数据,有效减少了mini-batch梯度的方差,加快了优化速度。
-
引入了新的条件采样技术,用于生成更长、更高分辨率的视频。
该模型可以进行无条件视频生成,也支持文本条件的视频生成。
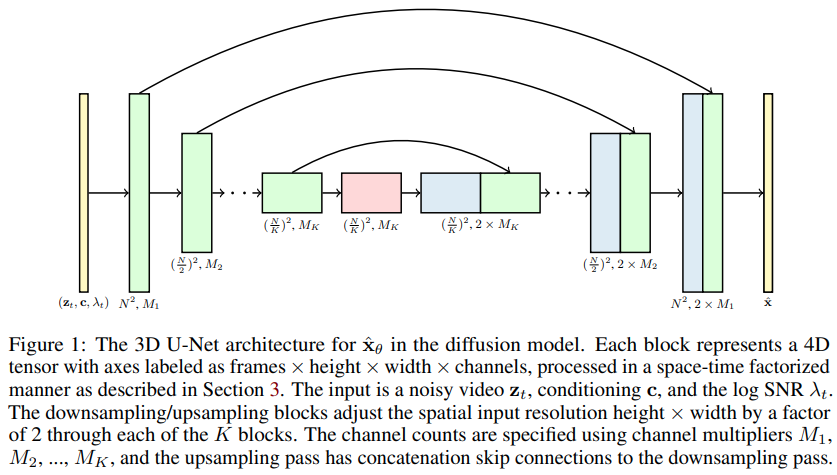
突破性成果
Video Diffusion Models在多个方面取得了突破性进展:
-
在UCF-101数据集上的无条件视频生成任务中,取得了当前最好的样本质量得分。
-
首次展示了大规模文本条件视频生成的结果,生成视频与文本描述高度相关。
-
相比之前的方法,生成的视频具有更好的时间连贯性和更高的视觉质量。
以下是一些生成样例:
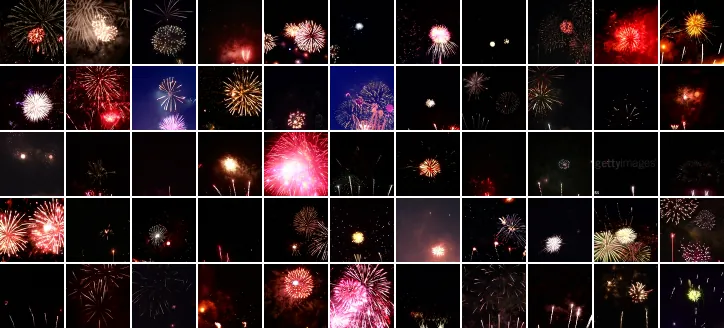
这些烟花并不存在,完全是AI生成的

技术细节
Video Diffusion Models的一些关键技术细节包括:
-
使用分解的时空注意力机制,可以在训练时同时关注当前帧。
-
采用类似BERT的相对位置编码,提高了时空建模能力。
-
引入了一种新的梯度条件采样方法,用于视频的空间和时间扩展。
-
使用分类器无关引导(Classifier-free guidance)来提高样本质量。
应用前景
Video Diffusion Models在多个领域具有广阔的应用前景:
-
电影和动画制作:可以根据文本描述生成视频片段,辅助创作。
-
广告制作:快速生成符合需求的广告视频素材。
-
教育培训:生成教学视频和模拟场景。
-
游戏开发:自动生成游戏场景和动画。
-
视频编辑:视频修复、扩展等任务。
开源实现
该项目的PyTorch实现已在GitHub开源,感兴趣的读者可以通过以下方式尝试:
pip install video-diffusion-pytorch
基本用法示例:
import torch
from video_diffusion_pytorch import Unet3D, GaussianDiffusion
model = Unet3D(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
diffusion = GaussianDiffusion(
model,
image_size = 32,
num_frames = 5,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch.randn(1, 3, 5, 32, 32) # (batch, channels, frames, height, width)
loss = diffusion(videos)
loss.backward()
# 采样生成视频
sampled_videos = diffusion.sample(batch_size = 4)
sampled_videos.shape # (4, 3, 5, 32, 32)
未来展望
尽管Video Diffusion Models取得了突破性进展,但视频生成领域仍有很多值得探索的方向:
-
进一步提高生成视频的分辨率和帧数。
-
改进视频的时间一致性和物理合理性。
-
探索更多的条件控制方式,如姿态引导等。
-
结合其他模态(如音频)进行多模态视频生成。
-
提高模型的训练和推理效率。
Video Diffusion Models为高质量视频生成开辟了新的道路,相信在不久的将来,我们会看到更多令人惊叹的AI视频生成技术涌现。随着这些技术的发展,它们将深刻改变视频内容的创作和消费方式,为创意产业带来新的机遇和挑战。


























