
项目简介
Voice-Cloning-App是一个开源的语音克隆应用,基于Python和Pytorch开发,可以轻松地合成人声。该项目由BenAAndrew在GitHub上开源,目前已获得1.4k+的star。
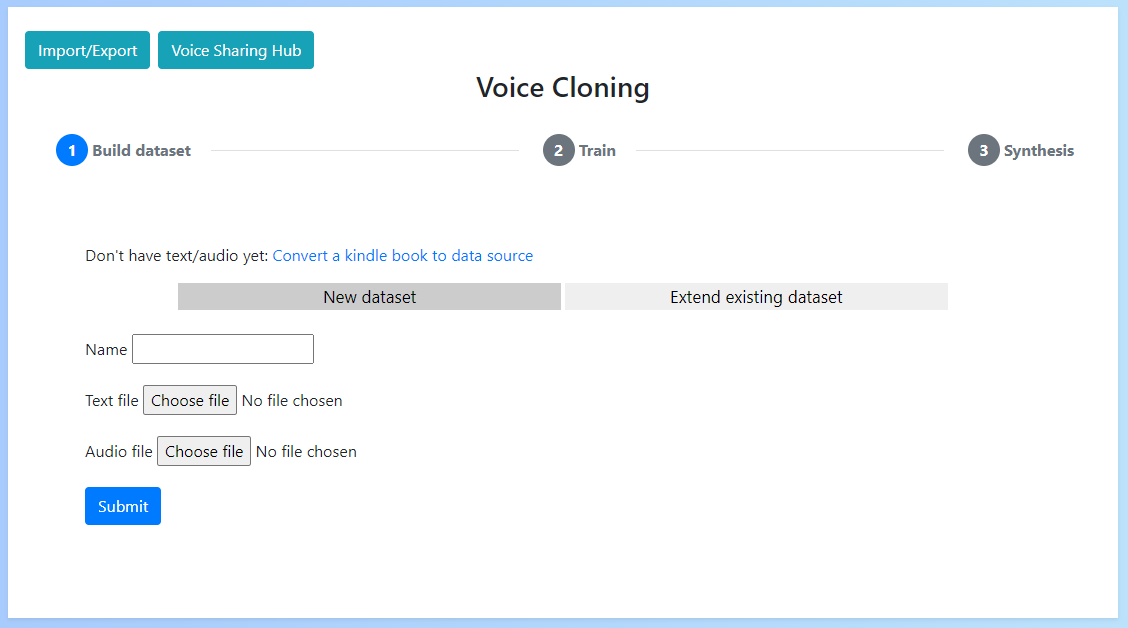
主要特性包括:
- 自动数据集生成(支持字幕和有声读物)
- 多语言支持
- 本地和远程训练
- 简易的训练开始/停止
- 数据导入/导出
- 多GPU支持
安装指南
要开始使用Voice-Cloning-App,首先需要安装必要的环境。详细的安装步骤可以参考项目的安装文档。
系统要求:
- Windows 10或Ubuntu 20.04+操作系统
- 5GB+磁盘空间
- NVIDIA GPU,至少4GB显存(可选)
使用教程
-
数据集构建
构建高质量的语音数据集是成功训练语音克隆模型的关键。Voice-Cloning-App提供了自动化的数据集生成工具,详细说明请查看数据集构建文档。
-
模型训练
完成数据集准备后,就可以开始训练语音克隆模型了。项目支持本地训练和远程训练,具体操作方法请参考训练文档。
-
语音合成
模型训练完成后,就可以使用它来合成新的语音了。关于如何使用训练好的模型进行语音合成,请查看合成文档。
其他学习资源
-
视频教程 - 作者制作的详细视频指南,覆盖了项目使用的各个方面。
-
远程训练 Notebook - 如果你没有本地GPU资源,可以使用这个Colab notebook在云端训练模型。
-
Discord 社区 - 加入项目的Discord服务器,与其他用户交流经验,获取帮助。
-
Voice Sharing Hub - 一个分享和探索其他人训练的语音模型的平台。
-
常见问题解答 - 汇总了用户常见的问题和解答。
相关项目
- Tacotron2 - Voice-Cloning-App使用了改进版的Tacotron2作为基础模型。
- DSAlign - 用于音频和文本对齐的工具。
- Silero - 用于语音识别的预训练模型。
- DeepSpeech - Mozilla开源的语音识别引擎。
- hifi-gan - 高保真的神经声码器。
Voice-Cloning-App 是一个功能强大且易于使用的语音克隆工具,无论你是语音合成领域的研究者、开发者,还是对语音技术感兴趣的爱好者,都可以从这个项目中获益。希望本文汇总的学习资料能够帮助你快速入门并深入探索语音克隆的奥秘。如果在使用过程中遇到任何问题,欢迎查阅项目文档或在GitHub上提出issue。祝你在语音克隆的旅程中收获满满! 🎤🔊










