
VoiceFixer 简介
VoiceFixer 是一个通用的语音修复工具,旨在恢复严重退化的人声语音。它可以在一个模型中处理噪声、混响、低分辨率(2kHz~44.1kHz)和削波(0.1-1.0阈值)等多种退化效果。
主要特点:
- 基于神经声码器构建的预训练 VoiceFixer 模型
- 预训练的 44.1kHz 通用说话人无关神经声码器
- 可处理多种语音退化问题
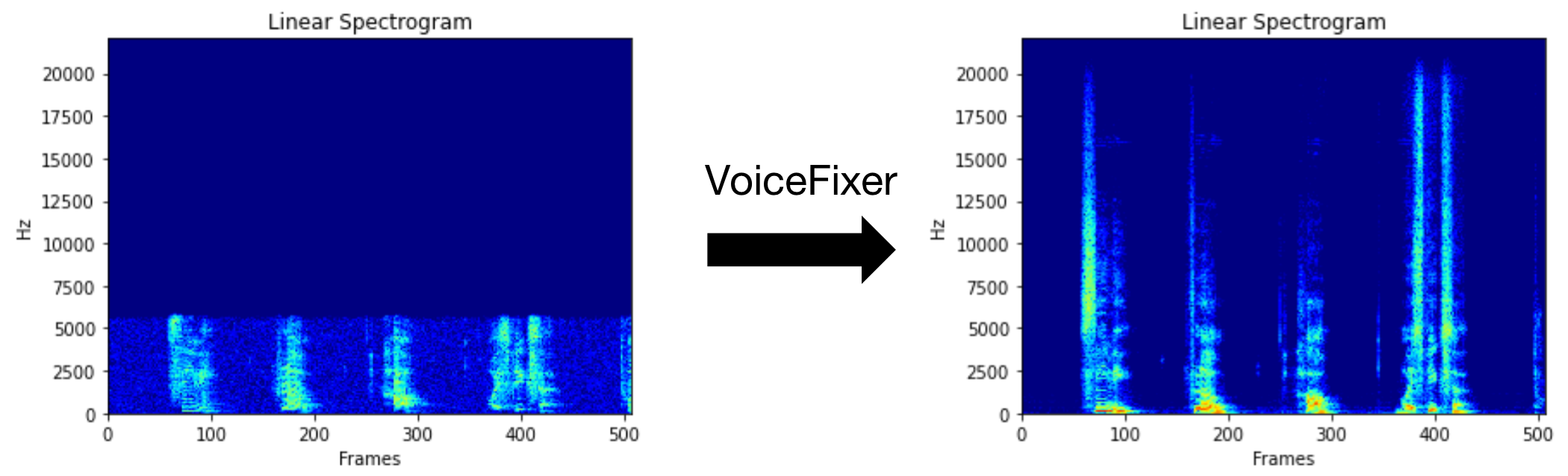
快速开始
安装
通过 pip 安装 VoiceFixer:
pip install git+https://github.com/haoheliu/voicefixer.git
使用示例
from voicefixer import VoiceFixer
# 初始化模型
voicefixer = VoiceFixer()
# 语音修复
voicefixer.restore(input="input.wav",
output="output.wav",
cuda=False,
mode=0) # 可以尝试 mode 0, 1, 2
学习资料
-
GitHub 仓库 - 包含源码、详细文档和使用说明
-
Demo 页面 - 可以直观体验 VoiceFixer 的效果
-
Colab notebook - 在线交互式学习
-
论文 - 深入了解技术原理
-
PyPI 页面 - 查看版本更新和安装说明
-
Hugging Face 模型 - 在线快速体验
进阶使用
- 命令行使用方法
- 桌面应用程序
- Docker 部署
- 自定义声码器
详细说明请参考 GitHub README。
VoiceFixer 为语音修复提供了一个强大而通用的解决方案。通过本文提供的学习资料,相信读者可以快速入门并开始使用这个优秀的工具。如果在使用过程中遇到问题,欢迎查阅官方文档或在 GitHub 上提出 issue。












