
VoiceFlow-TTS:革新文本转语音技术
在人工智能和语音技术飞速发展的今天,高效且高质量的文本转语音(Text-to-Speech, TTS)系统一直是研究热点。近日,X-LANCE团队开发的VoiceFlow-TTS系统在这一领域取得了重大突破。该项目已在GitHub上开源,并将在ICASSP 2024国际会议上正式发表。
创新技术:矫正流匹配
VoiceFlow-TTS的核心创新在于采用了"矫正流匹配"(Rectified Flow Matching)技术。这一方法巧妙地平衡了传统TTS系统在语音质量和生成速度之间的权衡。通过优化流程和算法,VoiceFlow-TTS能够在保证高质量语音输出的同时,显著提升推理速度。
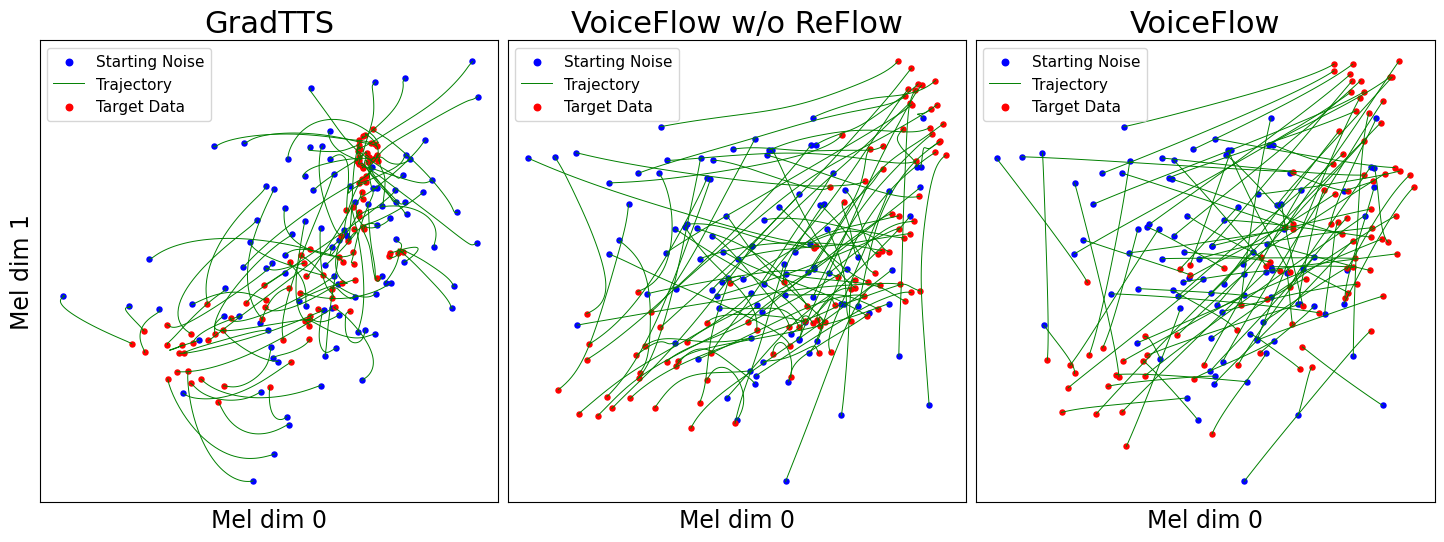
上图展示了VoiceFlow-TTS的工作流程,直观地呈现了系统如何通过优化轨迹实现高效语音合成。
系统特点与优势
-
高效性: 相比传统方法,VoiceFlow-TTS在推理速度上有显著提升,为实时应用提供了可能。
-
质量保证: 尽管追求效率,系统并未牺牲语音质量,输出的语音依然保持自然流畅。
-
灵活性: 系统支持多种语音特征调整,如说话人、语速等,满足不同应用场景需求。
-
开源共享: 项目在GitHub上完全开源,有利于学术交流和技术创新。
环境配置与使用
VoiceFlow-TTS基于Python 3.9开发,主要在Linux环境下测试。用户可以通过以下步骤快速搭建环境:
conda create -n vflow python==3.9
conda activate vflow
pip install -r requirements.txt
source path.sh
cd model/monotonic_align
python setup.py build_ext --inplace
系统采用Kaldi风格的数据组织方式,详细的数据准备和使用说明可在项目README中找到。
训练与推理
VoiceFlow-TTS提供了完整的训练和推理流程。用户可以通过配置YAML文件来自定义训练参数,如下所示:
python train.py -c configs/${your_yaml} -m ${model_name}
推理过程同样简单直接:
python inference_dataset.py -c configs/${your_yaml} -m ${model_name} --EMA \
--solver euler -t 10
这种设计使得研究人员和开发者能够轻松地进行实验和部署。
未来展望与应用前景
VoiceFlow-TTS的出现为TTS技术的发展开辟了新的方向。其高效性使得它在多个领域都有广阔的应用前景:
- 实时语音助手: 更快的响应速度意味着更自然的人机交互体验。
- 语音导航系统: 在需要实时反馈的场景中,VoiceFlow-TTS可以提供更及时的语音指引。
- 多语言学习工具: 快速生成高质量的多语言语音,辅助语言学习。
- 无障碍技术: 为视障人士提供更流畅的文本朗读服务。
开源社区与持续改进
作为一个开源项目,VoiceFlow-TTS欢迎来自全球开发者的贡献。项目维护者积极响应issues和pull requests,确保系统能够不断优化和进步。同时,项目还提供了详细的文档和示例,降低了新用户的学习门槛。
结语
VoiceFlow-TTS的出现标志着TTS技术进入了一个新的阶段。它不仅推动了学术研究的前沿,也为实际应用提供了强有力的工具。随着更多研究者和开发者的加入,我们有理由相信,VoiceFlow-TTS将在未来继续引领TTS技术的发展,为人工智能和语音交互领域带来更多创新和突破。
对于那些对TTS技术感兴趣的研究者、开发者或企业,VoiceFlow-TTS无疑是一个值得关注和尝试的项目。通过访问GitHub仓库,你可以深入了解这一创新技术,并为其发展贡献自己的力量。










