VTimeLLM:赋予大语言模型把握视频时刻的能力
随着大语言模型(LLM)在文本理解方面展现出惊人的能力,研究人员开始探索将其扩展到视频领域。然而,现有的视频大语言模型往往只能提供整个视频的粗略描述,无法精确捕捉特定事件的开始和结束时间边界。为了解决这一问题,来自清华大学的研究团队提出了VTimeLLM,这是一种创新的视频大语言模型,专为细粒度视频时刻理解和时间边界推理而设计。
VTimeLLM的核心创新
VTimeLLM的核心创新在于其采用了边界感知的三阶段训练策略:
- 利用大规模图像-文本对进行特征对齐
- 使用包含多个事件的视频-文本数据,结合时间相关的单轮和多轮问答,增强对时间边界的感知
- 在高质量对话数据集上进行指令微调,进一步提升时间理解能力并与人类意图对齐
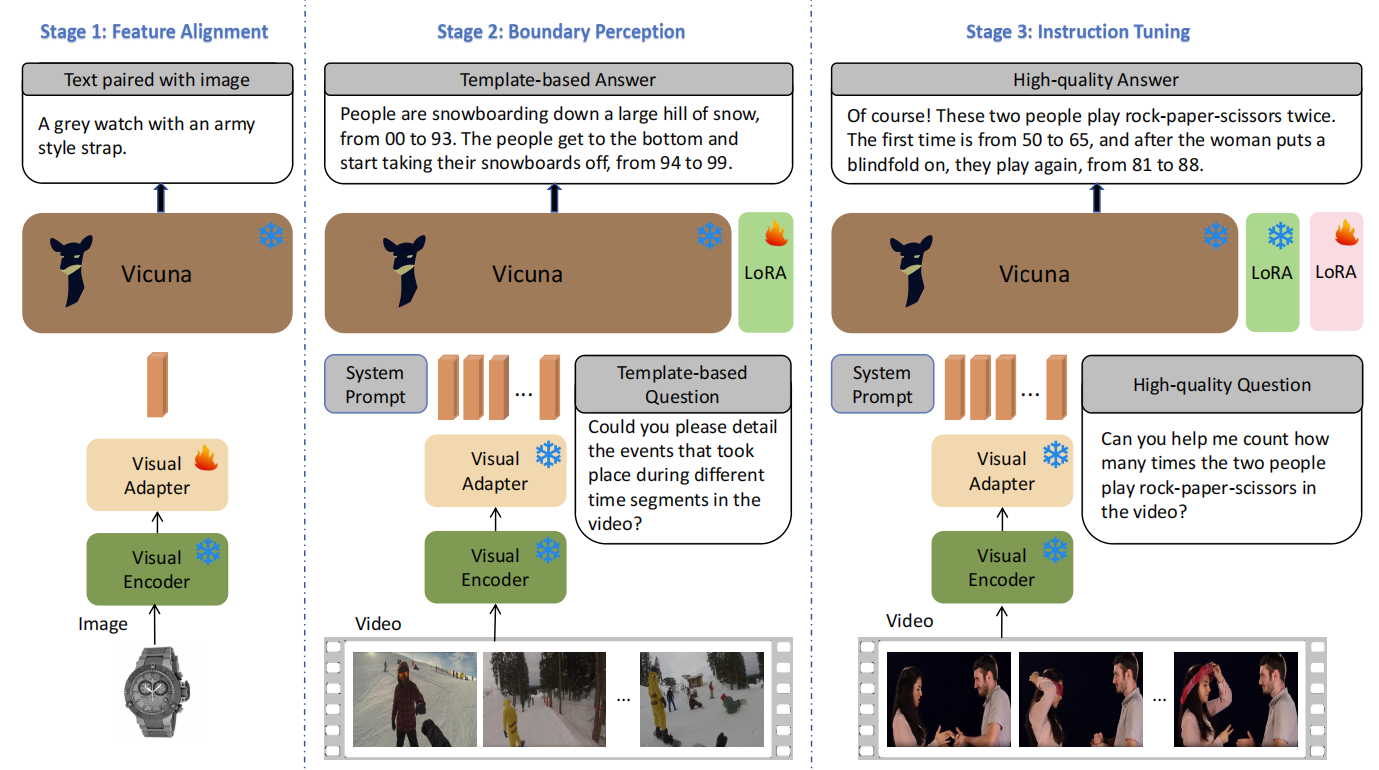
这种独特的训练策略使VTimeLLM能够更好地理解视频中的时间信息,从而在多项视频相关任务中取得显著的性能提升。
VTimeLLM的主要贡献
- 提出了首个边界感知的视频大语言模型VTimeLLM
- 设计了创新的边界感知三阶段训练策略
- 通过大量实验证明VTimeLLM在各种细粒度时间相关视频任务中显著优于现有视频大语言模型
VTimeLLM的性能评估
研究团队对VTimeLLM进行了全面的性能评估,涵盖了多个视频理解和推理任务:
-
视频理解与对话任务 VTimeLLM展现出强大的视频内容理解能力,能够准确回答关于视频细节的问题,并进行自然流畅的多轮对话。
-
创意任务 模型能够基于视频内容生成创意性的描述和故事,展现出良好的想象力和语言表达能力。
-
细粒度理解任务 VTimeLLM能够精确定位视频中的特定时间片段,并提供细致入微的描述,这对于视频检索和分析具有重要意义。
-
视频推理任务 模型展现出强大的推理能力,能够根据视频内容回答复杂的因果关系和逻辑推理问题。

VTimeLLM的应用前景
VTimeLLM的出现为视频内容理解和分析开辟了新的可能性。它可能在以下领域产生重大影响:
- 视频检索与推荐:通过精确理解视频内容和时间信息,提供更准确的检索结果和个性化推荐。
- 视频监控与安防:自动识别和定位视频中的异常事件,提高安全监控效率。
- 视频内容创作:为创作者提供智能辅助,如自动生成视频摘要、字幕和标签。
- 教育与培训:通过精确定位和解释视频中的关键时刻,提升在线学习体验。
- 医疗影像分析:辅助医生更好地理解和分析动态医学影像。
VTimeLLM的开源与未来发展
为了推动视频大语言模型的研究和应用,研究团队已在GitHub上开源了VTimeLLM的代码和模型。他们鼓励社区参与,共同探索和改进这一前沿技术。
未来,VTimeLLM的研究方向可能包括:
- 进一步提升模型的时间理解精度
- 扩展到更长时间跨度的视频理解
- 增强跨语言和跨文化的视频理解能力
- 探索与其他模态(如音频)的多模态融合
结语
VTimeLLM的出现标志着视频大语言模型研究的一个重要里程碑。它不仅在技术上取得了突破,更为视频内容的智能理解和应用开辟了广阔的前景。随着技术的不断进步和应用场景的拓展,我们有理由期待VTimeLLM及其衍生技术将在未来对社会产生深远的影响。
研究团队的开源精神也值得赞赏,这将加速相关技术的发展和应用。对于研究人员、开发者和行业从业者来说,VTimeLLM无疑是一个值得关注和深入探索的重要项目。









