
📚 WARC-GPT简介
WARC-GPT是由哈佛大学法学院图书馆创新实验室(Library Innovation Lab)开发的开源工具,旨在利用人工智能技术探索Web存档集合。它允许用户创建自定义聊天机器人,使用一组Web存档文件作为知识库,让用户通过对话方式探索Web存档内容。

🌟 主要特性
- 为WARC文件提供检索增强生成(RAG)管道
- 高度可定制,可与多种LLM、提供商和嵌入模型交互
- REST API接口
- Web用户界面
- 嵌入可视化功能
🔧 安装与配置
安装步骤
-
克隆项目仓库:
git clone https://github.com/harvard-lil/warc-gpt.git -
安装依赖:
poetry env use 3.11 poetry install
配置说明
- 复制
.env.example文件为.env,并根据需要进行编辑 - WARC-GPT可以与OpenAI API和Ollama进行交互,至少需要配置其中一个
- 默认情况下,程序会尝试与
http://localhost:11434的Ollama API通信
📖 使用指南
摄取WARC文件
- 将WARC文件放入
./warc目录 - 运行以下命令提取文本并生成嵌入:
poetry run flask ingest
启动服务器
运行以下命令在端口5000启动WARC-GPT服务器:
poetry run flask run
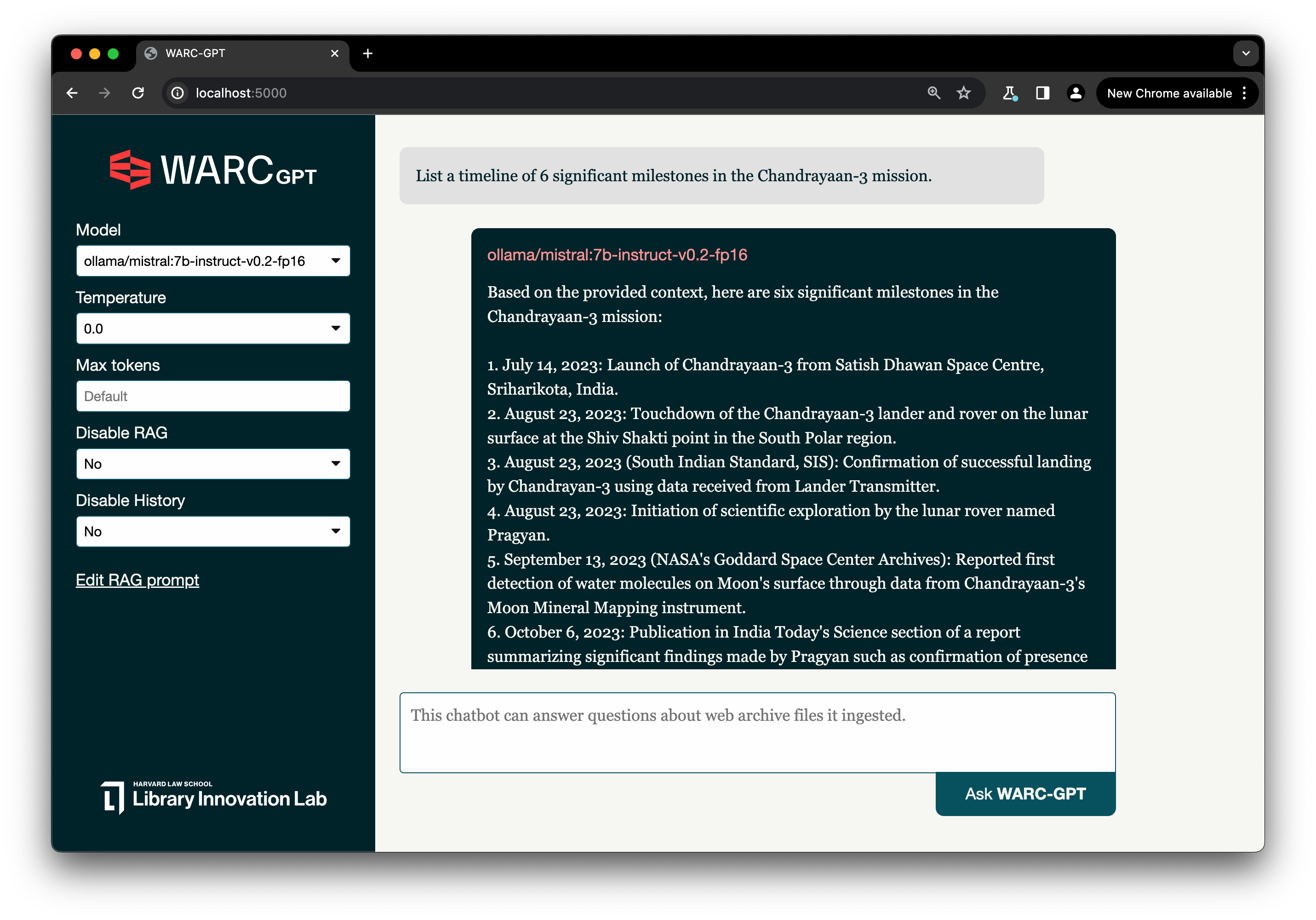
Web界面交互
访问http://localhost:5000使用Web界面与WARC-GPT交互。系统会尝试在知识库中找到相关摘录来回答问题。
API交互
WARC-GPT提供了以下API端点:
GET /api/models: 返回可用模型列表POST /api/search: 在向量存储中搜索相关内容POST /api/complete: 使用LLM生成文本补全
🔬 进阶功能
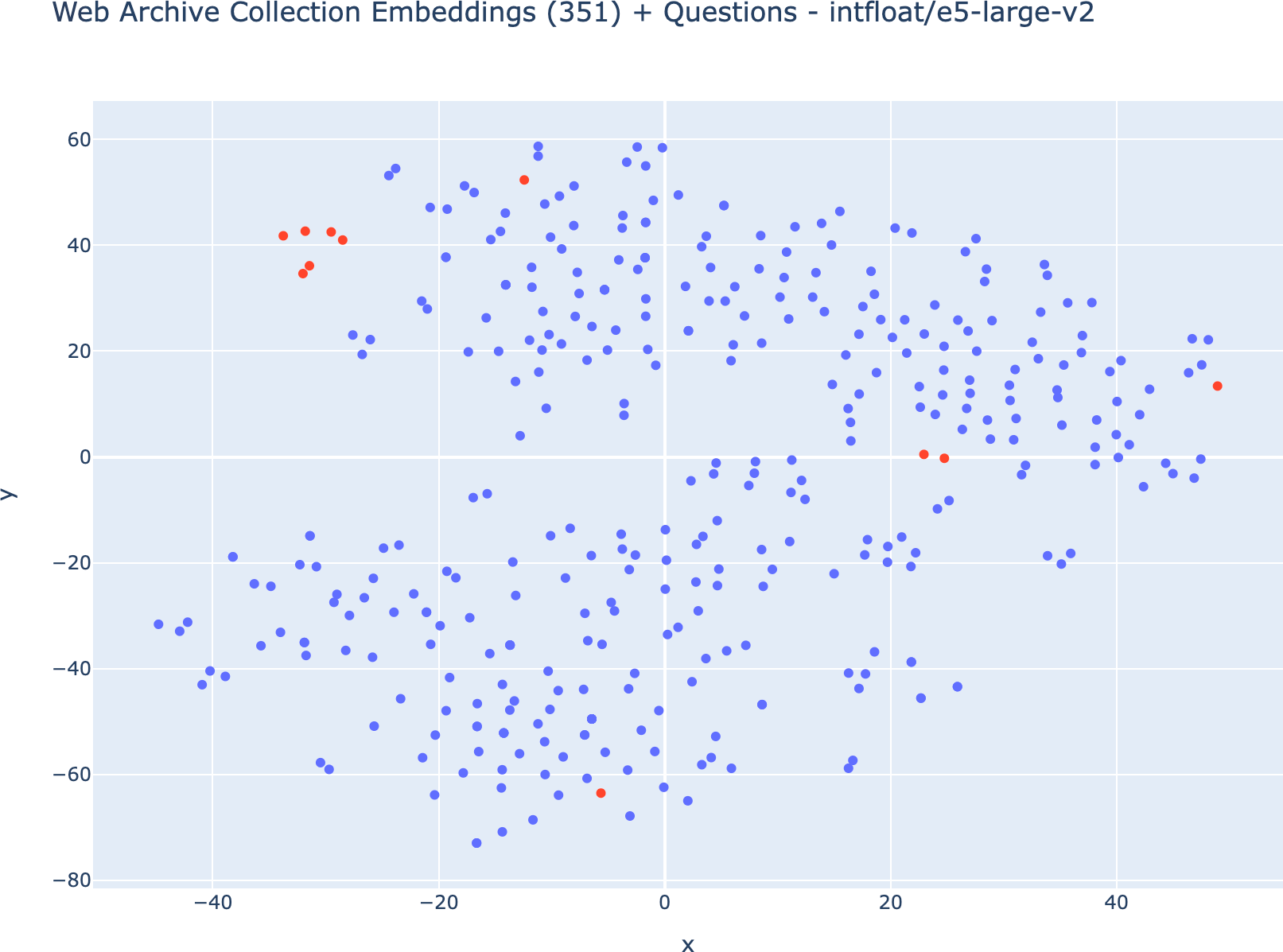
嵌入可视化
WARC-GPT允许生成基本的交互式T-SNE 2D散点图来可视化生成的向量存储:
poetry run flask visualize
📚 相关资源
🚀 未来方向
- 测试更大规模、真实世界的集合
- 探索多模态嵌入和文本生成
- 开发集合级别的摘要组件
WARC-GPT为探索Web存档和人工智能的交叉领域提供了一个强大而灵活的工具。我们鼓励Web存档社区成员尝试使用,并为这个持续进行的实验提供反馈和贡献。🌐🤖










