
WaveGrad简介
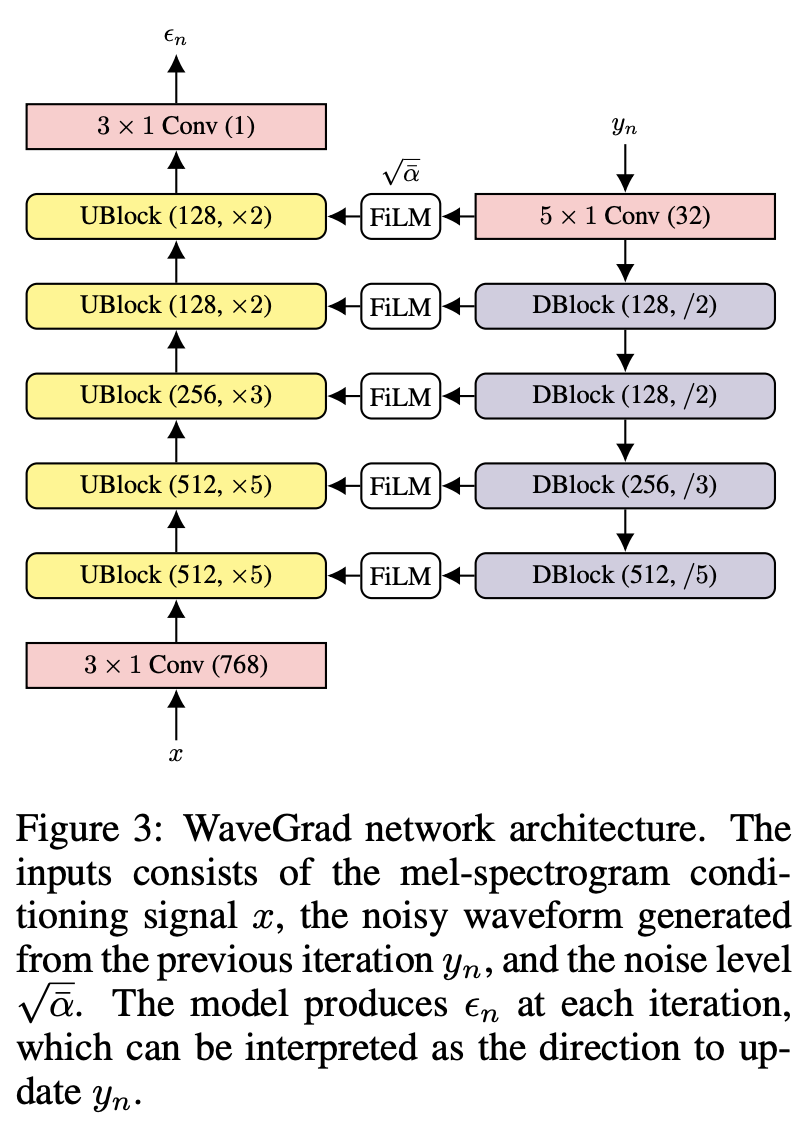
WaveGrad是由Google Brain团队设计的一种快速、高质量的神经网络声码器。它的核心思想是通过估计数据密度的梯度来生成波形,采用迭代细化的方式将对数尺度的梅尔频谱图转换为音频波形。WaveGrad具有以下特点:
- 非自回归模型,推理速度快
- 可以通过调整迭代次数来平衡推理速度和音频质量
- 能够生成高保真度的音频样本
- 训练简单,隐式优化变分下界
项目资源
📄 论文
💻 代码实现
🎧 音频样本
🧠 预训练模型
使用指南
安装
可以通过pip安装:
pip install wavegrad
或者从GitHub克隆源码:
git clone https://github.com/lmnt-com/wavegrad.git
cd wavegrad
pip install .
训练
在开始训练之前,需要准备训练数据集。数据集可以是任意目录结构,只要包含16位单声道的.wav文件即可(如LJSpeech、VCTK等数据集)。默认采样率为22kHz,如需修改可编辑params.py文件。
训练命令:
python -m wavegrad.preprocess /path/to/dir/containing/wavs
python -m wavegrad /path/to/model/dir /path/to/dir/containing/wavs
推理
基本用法:
from wavegrad.inference import predict as wavegrad_predict
model_dir = '/path/to/model/dir'
spectrogram = # 获取[N,C,W]格式的频谱图
audio, sample_rate = wavegrad_predict(spectrogram, model_dir)
进阶技巧
自定义噪声调度
WaveGrad默认使用1000次迭代来细化波形,这会导致推理速度慢于实时。实际上,WaveGrad可以通过仅6次迭代就能实现高质量、快于实时的合成,而无需重新训练模型。
要实现这种加速,需要为数据集搜索合适的"噪声调度"。项目提供了搜索脚本:
python -m wavegrad.noise_schedule /path/to/trained/model /path/to/preprocessed/validation/dataset
python -m wavegrad.inference /path/to/trained/model /path/to/spectrogram -n noise_schedule.npy -o output.wav
总结
WaveGrad作为一种创新的神经网络声码器,在保证音频质量的同时大幅提升了推理速度。本文介绍的学习资源可以帮助读者快速入门并深入探索WaveGrad模型。无论是语音合成研究人员还是实践工程师,都可以从中获得有价值的信息和工具。
🔗 更多资源:
希望这些资料能够帮助您深入了解和应用WaveGrad模型。如果您对语音合成感兴趣,WaveGrad无疑是一个值得关注和尝试的前沿技术。












