
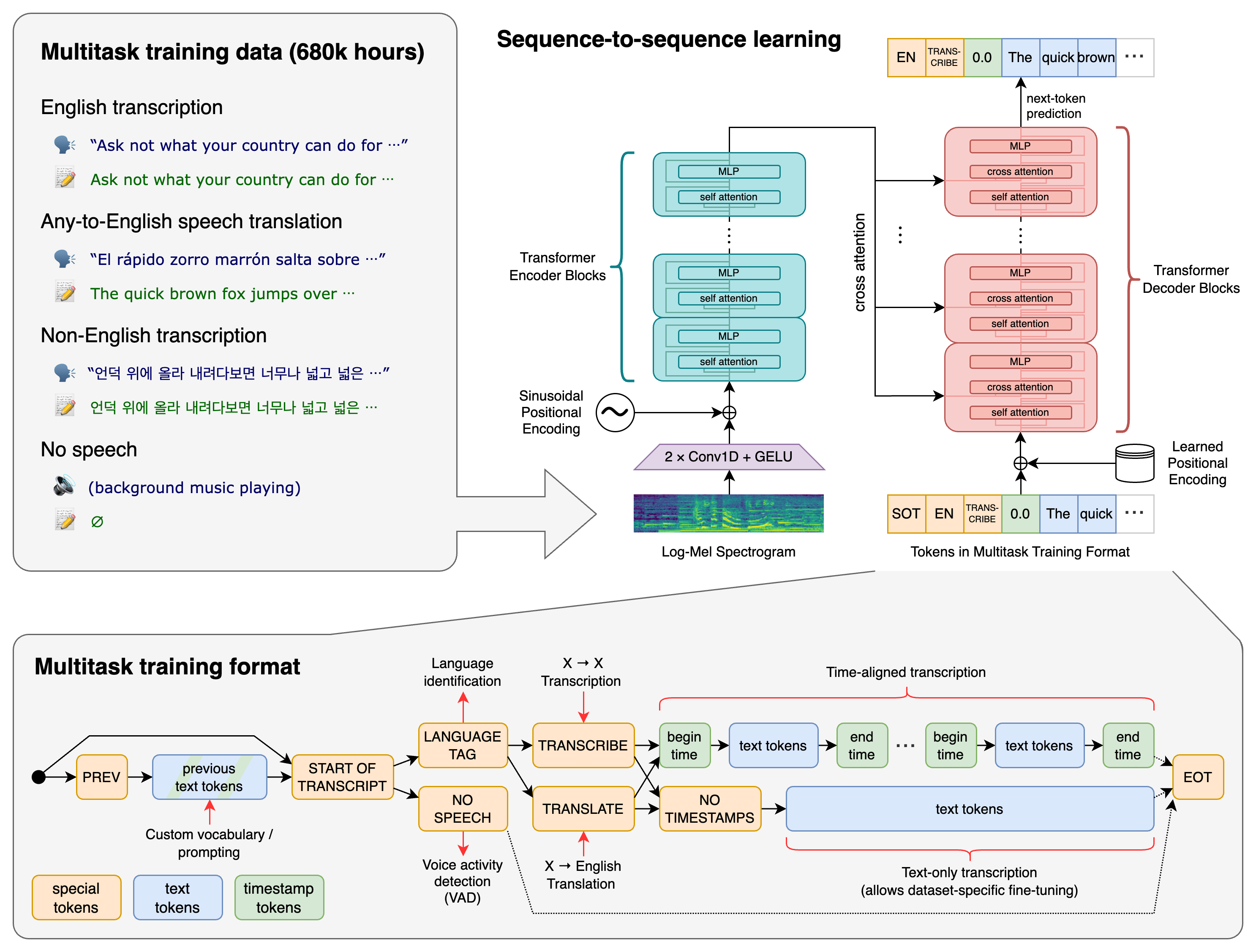
Whisper简介
Whisper是OpenAI开发的通用语音识别模型,具有以下特点:
- 支持多语言语音识别、语音翻译和语言识别
- 在大规模、多样化的音频数据集上训练
- 采用Transformer序列到序列模型架构
- 开源代码和模型权重,使用MIT许可证发布
安装和使用
安装
可以通过pip安装Whisper:
pip install -U openai-whisper
或者从GitHub安装最新版本:
pip install git+https://github.com/openai/whisper.git
命令行使用
使用medium模型转录音频文件:
whisper audio.mp3 --model medium
指定语言和翻译任务:
whisper japanese.wav --language Japanese --task translate
Python API使用
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
可用模型
Whisper提供了5种不同大小的模型,适用于不同的场景:
| 模型 | 参数量 | 内存需求 | 相对速度 |
|---|---|---|---|
| tiny | 39M | ~1GB | ~32x |
| base | 74M | ~1GB | ~16x |
| small | 244M | ~2GB | ~6x |
| medium | 769M | ~5GB | ~2x |
| large | 1550M | ~10GB | 1x |
其中tiny、base、small和medium模型还提供英语专用版本。
更多资源
Whisper是一个功能强大、易于使用的语音识别工具,希望这些资源能帮助你快速上手并充分利用它的能力。如果你在使用过程中有任何问题,欢迎查阅官方文档或在GitHub上提问。


















