
Whisper-WebUI: 开源音频转录利器
在这个信息爆炸的时代,视频和音频内容日益丰富,但如何快速准确地将音频转化为文字一直是一个挑战。幸运的是,随着人工智能技术的发展,音频转录领域迎来了革命性的突破。今天我们要介绍的Whisper-WebUI,就是一款基于最新AI技术打造的开源音频转录工具,它不仅功能强大,而且使用简单,是音频处理爱好者和专业人士的不二之选。
强大功能一览
Whisper-WebUI是在OpenAI的Whisper模型基础上开发的图形用户界面,集成了多项强大功能:
-
多种音频源支持: 无论是本地音频文件、YouTube视频还是麦克风实时录音,Whisper-WebUI都能轻松处理。
-
多种字幕格式: 支持SRT、WebVTT等主流字幕格式,以及纯文本输出。
-
多语言支持: 借助Whisper模型的强大能力,可以识别并转录多种语言的音频。
-
翻译功能: 不仅可以将音频转录为原文,还能直接将非英语音频翻译成英文文本。
-
预处理和后处理: 集成了Silero VAD进行音频预处理,以及pyannote模型进行说话人分离。
-
灵活部署: 既可以本地运行,也支持Docker容器化部署,满足不同用户的需求。
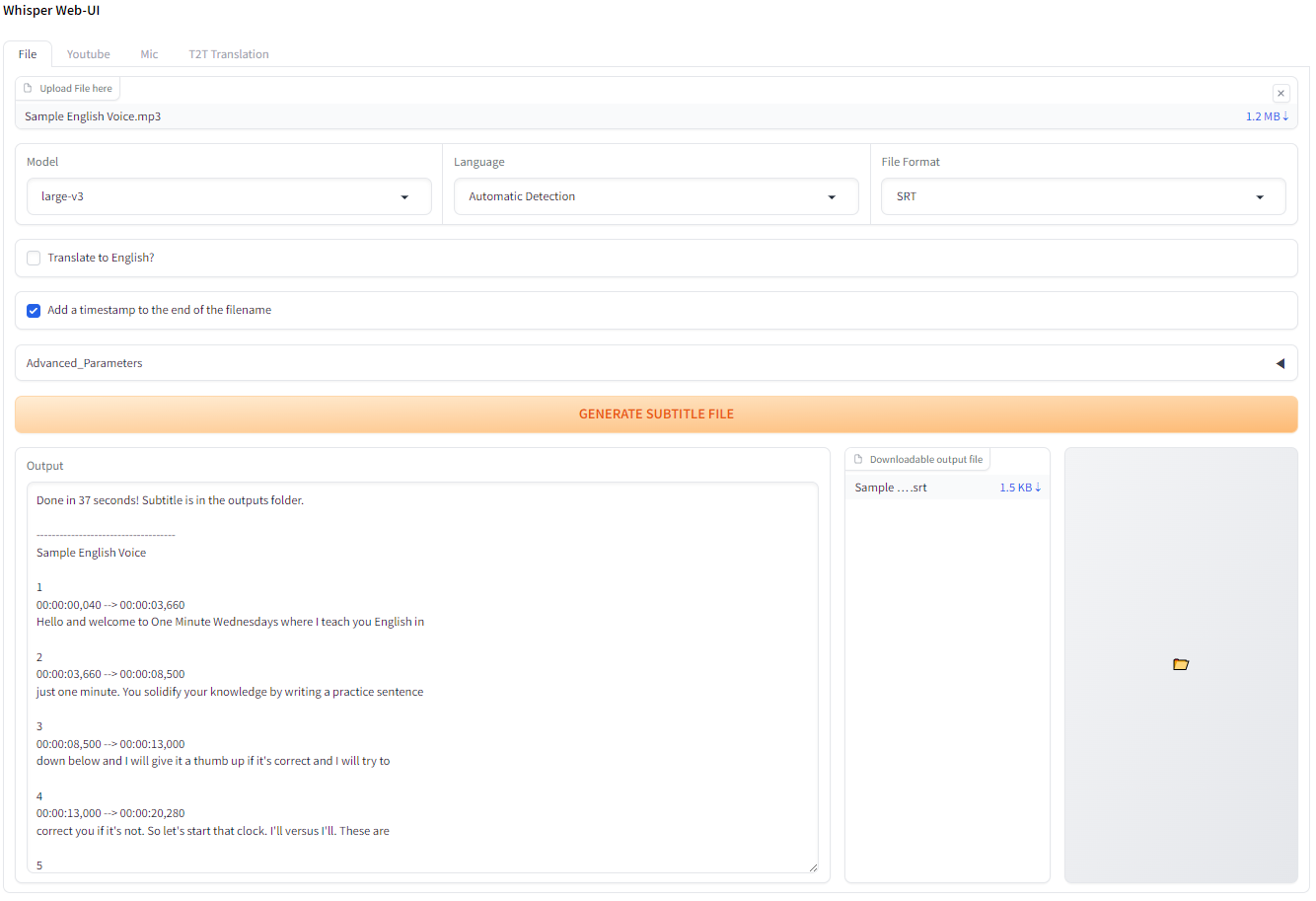
安装与使用
Whisper-WebUI的安装过程相对简单。首先,你需要确保系统中已安装Python (3.8-3.10版本)、Git和FFmpeg。然后,按照以下步骤进行:
- 从GitHub下载Whisper-WebUI的最新发布版本。
- 运行安装脚本(Windows下为
install.bat,Linux/Mac下为install.sh)。 - 启动WebUI(使用
start-webui.bat或start-webui.sh)。
对于喜欢使用Docker的用户,项目也提供了Docker支持:
git clone https://github.com/jhj0517/Whisper-WebUI.git
cd Whisper-WebUI
docker compose build
docker compose up
启动后,打开浏览器访问http://localhost:7860即可使用Web界面。
技术特性深度解析
Whisper-WebUI在技术实现上有许多值得称道的地方:
-
多种Whisper实现: 默认使用faster-whisper,但也支持原版whisper和insanely-fast-whisper,用户可根据需求选择。
-
VRAM优化: 采用faster-whisper实现,大幅降低了GPU内存占用,提高了转录速度。
-
并行处理: 支持多GPU并行处理,充分利用硬件资源。
-
自动化配置: 提供了auto_parallel选项,可自动检测并使用所有可用GPU。
-
灵活的模型选择: 支持tiny到large等多种规模的模型,用户可根据设备性能和精度需求进行选择。
未来展望
Whisper-WebUI的开发团队并未止步于此,他们计划在未来添加更多激动人心的功能:
- DeepL API翻译支持
- NLLB模型翻译集成
- 背景音乐分离预处理
- FastAPI脚本支持
- 实时麦克风转录
这些计划中的功能将进一步提升Whisper-WebUI的实用性和灵活性。
结语
Whisper-WebUI作为一款开源的音频转录工具,以其强大的功能、友好的界面和灵活的部署方式赢得了众多用户的青睐。无论你是需要处理大量音频的专业人士,还是偶尔需要转录的普通用户,Whisper-WebUI都能满足你的需求。
随着AI技术的不断进步,我们有理由相信,Whisper-WebUI将继续evolve,为用户带来更多惊喜。如果你对音频转录感兴趣,不妨亲自尝试一下这款强大的工具。相信它一定能成为你音频处理工作流程中不可或缺的一环。
无论你是开发者、内容创作者还是研究人员,Whisper-WebUI都值得你花时间去探索。让我们一起期待这个优秀项目的未来发展!









