
WhisperSpeech简介
WhisperSpeech是一个由Collabora公司开发的开源文本转语音系统,它通过反转Whisper语音识别模型来实现高质量的语音合成。该项目旨在打造一个类似于Stable Diffusion在图像领域的强大而易于定制的语音合成工具。
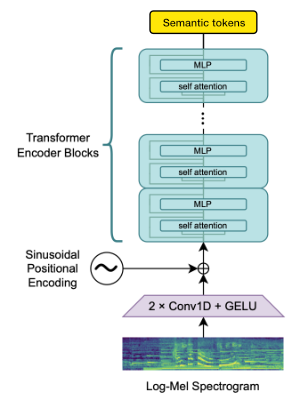
官方资源
- GitHub仓库: 包含源代码、文档和示例
- 项目网站: 提供项目概述和最新进展
- Google Colab演示: 在线试用WhisperSpeech的功能
- HuggingFace模型: 预训练模型下载
- HuggingFace数据集: 用于训练的转换数据集
教程与文档
- WhisperSpeech README: 详细介绍项目架构、进展和使用方法
- Inference示例Notebook: 演示如何使用预训练模型进行推理
- 长文本推理Notebook: 展示处理长文本的技巧
视频资料
- 大规模训练技巧分享: 介绍将WhisperSpeech模型扩展到80k+小时语音数据的经验
- WhisperSpeech深入讨论: 详细探讨项目的架构选择
社区资源
- LAION Discord服务器: 加入#audio-generation频道与开发者和用户交流
- 进展更新归档: 查看项目历史进展
扩展阅读
- AudioLM: Google的音频语言模型,WhisperSpeech架构的灵感来源之一
- SPEAR TTS: Google的另一个相关文本转语音项目
- MusicGen: Meta的音乐生成模型,与WhisperSpeech采用类似架构
WhisperSpeech作为一个开源项目,正在快速发展中。该项目不仅提供了高质量的语音合成能力,还支持多语言、声音克隆等高级功能。无论你是语音技术研究者、开发者还是对AI语音感兴趣的爱好者,都可以通过上述资源深入了解和参与这个激动人心的项目。随着社区的不断贡献,我们期待WhisperSpeech在未来为更多语言和应用场景带来革新性的语音合成解决方案。










