
x-transformers: 融合多种创新的Transformer库
x-transformers是一个由Phil Wang (lucidrains)开发的开源Transformer库,它以简洁的实现集成了多种前沿的实验性特性,为自然语言处理研究和应用提供了强大而灵活的工具。
主要特性
x-transformers的主要特性包括:
- 完整的编码器-解码器架构支持
- 灵活的配置选项,可以轻松实现各种Transformer变体
- 集成了多种最新的注意力机制改进
- 支持多种位置编码方案
- 提供了多种归一化和激活函数选项
- 实现了一些创新的架构设计,如Macaron结构等
这些特性使x-transformers成为一个非常适合进行Transformer相关研究和实验的工具库。
安装和基本使用
x-transformers可以通过pip轻松安装:
pip install x-transformers
以下是一个基本的使用示例,展示了如何创建一个简单的编码器-解码器模型:
import torch
from x_transformers import XTransformer
model = XTransformer(
dim = 512,
enc_num_tokens = 256,
enc_depth = 6,
enc_heads = 8,
enc_max_seq_len = 1024,
dec_num_tokens = 256,
dec_depth = 6,
dec_heads = 8,
dec_max_seq_len = 1024
)
src = torch.randint(0, 256, (1, 1024))
tgt = torch.randint(0, 256, (1, 1024))
loss = model(src, tgt)
loss.backward()
这个例子创建了一个具有6层编码器和6层解码器的Transformer模型,每层有8个注意力头,模型维度为512。
创新特性详解
x-transformers实现了许多最新的Transformer改进技术,下面我们来详细介绍其中的一些重要特性:
1. Flash Attention
Flash Attention是一种内存效率更高的注意力计算方法,它通过分块计算和重计算技术,将注意力机制的内存复杂度从二次降低到线性,同时还能提高计算速度。在x-transformers中,只需设置attn_flash = True即可启用:
model = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 6,
heads = 8,
attn_flash = True # 启用Flash Attention
)
)
2. 持久记忆增强自注意力
这项技术在注意力层之前添加了可学习的记忆键值对,可以在不增加太多参数的情况下提高模型性能:
enc = Encoder(
dim = 512,
depth = 6,
heads = 8,
attn_num_mem_kv = 16 # 添加16个记忆键值对
)
3. 记忆Transformer
记忆Transformer引入了额外的"记忆令牌",这些令牌与输入令牌一起通过注意力层:
model = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
num_memory_tokens = 20, # 添加20个记忆令牌
attn_layers = Encoder(
dim = 512,
depth = 6,
heads = 8
)
)
4. RMS归一化
RMS (Root Mean Square) 归一化是一种简化的层归一化变体,在一些大型语言模型中被证明更有效:
model = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 6,
heads = 8,
use_rmsnorm = True # 使用RMS归一化
)
)
5. GLU变体
门控线性单元 (GLU) 变体在前馈网络中引入了门控机制,可以显著提高模型性能:
model = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 6,
heads = 8,
ff_glu = True # 在所有前馈层中使用GLU
)
)
6. Talking-Heads注意力
Talking-Heads注意力机制在注意力的softmax之前和之后混合不同头之间的信息:
model = TransformorWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 6,
heads = 8,
attn_talking_heads = True # 启用Talking-Heads注意力
)
)

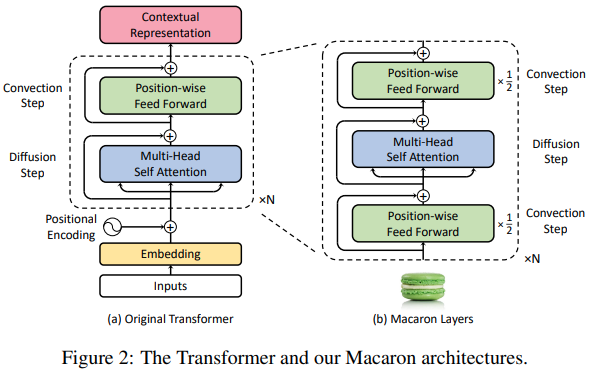
7. Macaron网络结构
Macaron结构将注意力层夹在两个前馈层之间,这种设计源于对Transformer的动力学系统解释:
model = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Encoder(
dim = 512,
depth = 6,
heads = 8,
macaron = True # 使用Macaron配置
)
)
高级应用
除了这些单独的特性,x-transformers还支持一些更复杂的应用场景:
-
图像分类: 可以轻松构建类似ViT (Vision Transformer) 的模型。
-
图像到文本生成: 支持构建包含视觉编码器和文本解码器的模型。
-
长序列处理: 通过Transformer-XL风格的循环机制,可以处理超出普通Transformer能力的长序列。
-
自定义层序列: 允许用户自定义注意力层和前馈层的排列顺序,实现如"三明治"Transformer等特殊结构。
结论
x-transformers为研究人员和开发者提供了一个强大而灵活的工具,使他们能够轻松实现和实验各种Transformer变体。通过集成多种前沿技术,x-transformers不仅可以用于研究目的,还可以在实际应用中构建高性能的模型。
随着自然语言处理和Transformer架构的不断发展,x-transformers也在持续更新和改进。对于那些希望深入研究Transformer或在其项目中使用最新Transformer技术的人来说,x-transformers无疑是一个值得关注的库。
通过提供这些丰富的功能和灵活的配置选项,x-transformers为推动Transformer技术的创新和应用做出了重要贡献。无论是进行学术研究还是开发实际应用,x-transformers都是一个极具价值的工具。










