
XLNet:突破性的自然语言处理模型
近年来,预训练语言模型在自然语言处理领域取得了巨大成功。其中,BERT(Bidirectional Encoder Representations from Transformers)模型凭借其强大的双向上下文建模能力,在多项NLP任务上刷新了记录。然而,BERT仍然存在一些局限性。为了进一步推动NLP技术的发展,研究人员提出了一种全新的预训练模型——XLNet,它在多个基准测试中超越了BERT的表现,成为了新一代NLP模型的代表作。
XLNet的核心思想
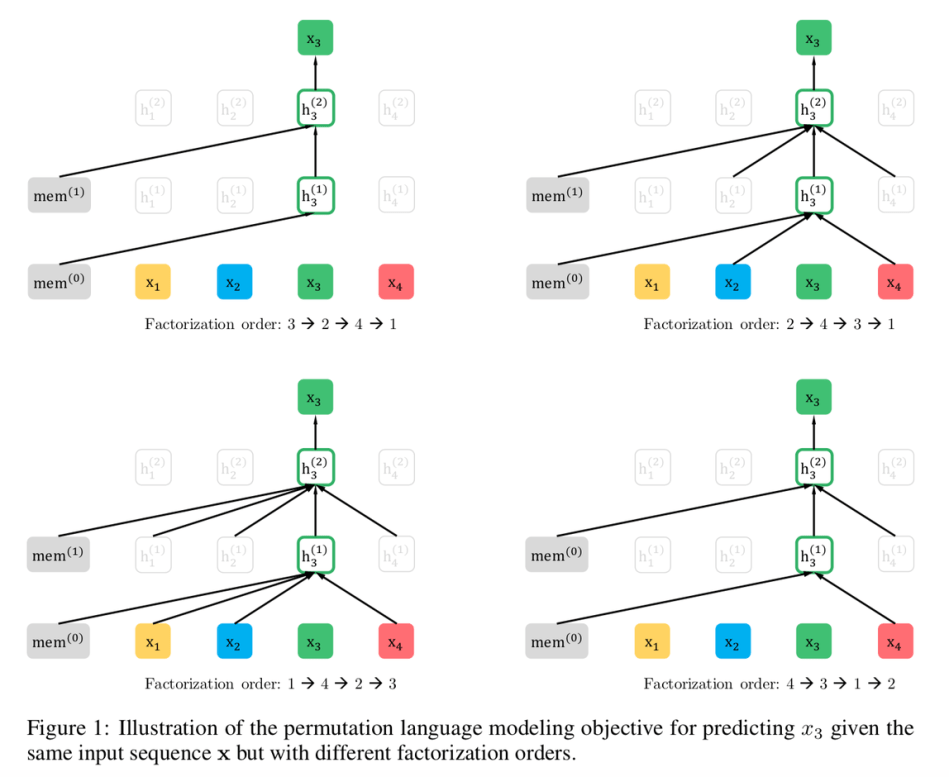
XLNet是一种基于自回归语言建模的无监督学习方法。与BERT等采用掩码语言模型(MLM)的方法不同,XLNet提出了一种新颖的排列语言建模(PLM)目标。具体来说,XLNet的主要创新点包括:
-
广义自回归预训练:XLNet通过最大化所有可能的因式分解顺序的期望对数似然,来学习双向上下文。这使得模型能够捕捉到更长距离的依赖关系。
-
整合Transformer-XL:XLNet采用Transformer-XL作为主干网络,继承了其在建模长文本方面的优势。这使得XLNet特别适合处理需要长期依赖的任务。
-
双流自注意力机制:为了解决PLM中的目标-内容歧义问题,XLNet设计了一种新的双流自注意力架构。
XLNet的技术优势
相比于BERT等先前模型,XLNet具有以下几个显著优势:
-
更好的长期依赖建模:通过整合Transformer-XL的相对位置编码和片段循环机制,XLNet能够更有效地处理长文本。
-
避免预训练-微调不一致:XLNet的PLM目标与BERT的MLM相比,在预训练和微调阶段保持了更好的一致性。
-
整合上下文双向信息:XLNet通过考虑所有可能的排列顺序,在不引入人工符号的情况下实现了双向上下文的建模。
-
更好的任务适应性:XLNet在问答、自然语言推理、情感分析等多种下游任务中展现出优异的迁移学习能力。
XLNet在实际应用中的表现
为了验证XLNet的有效性,研究人员在多个NLP基准测试集上进行了实验。结果表明,XLNet在20项任务中超越了BERT,并在18项任务中达到了当时的最佳水平。以下是一些具体的实验结果:
-
阅读理解任务:
- RACE数据集: XLNet-Large达到81.75%的准确率,比BERT-Large高出近10个百分点。
- SQuAD 2.0: XLNet-Large在EM(Exact Match)指标上达到86.12%,显著优于BERT的78.98%。
-
文本分类任务:
- IMDB情感分析: XLNet将错误率从4.51%降低到3.79%。
- Yelp评论分类: 在二分类和五分类任务中,XLNet都取得了更低的错误率。
-
GLUE基准测试:
- 在MNLI、QNLI、QQP等多个子任务中,XLNet-Large均优于BERT-Large。
- 特别是在RTE任务上,XLNet-Large(83.8%)比BERT-Large(70.4%)提高了13个百分点以上。
这些实验结果充分证明了XLNet在各类NLP任务中的卓越表现。
XLNet的实际应用
得益于其强大的性能,XLNet已经在多个领域得到了广泛应用:
-
智能问答系统:利用XLNet出色的阅读理解能力,可以构建更加智能的问答系统,为用户提供更准确的答案。
-
情感分析:XLNet在情感分类任务上的优异表现,使其成为构建高精度情感分析工具的理想选择。
-
文本摘要:借助XLNet对长文本的有效建模,可以开发出更加准确的自动文本摘要系统。
-
机器翻译:XLNet的双向上下文建模能力有助于提升机器翻译的质量,特别是在处理长句和复杂语境时。
-
对话系统:XLNet可以帮助改进聊天机器人的语言理解和生成能力,使对话更加自然流畅。
使用XLNet进行微调
对于想要在自己的任务中使用XLNet的开发者,以下是一个简单的PyTorch代码示例,展示了如何使用预训练的XLNet模型进行特征提取:
from transformers import XLNetTokenizer, XLNetModel
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = XLNetModel.from_pretrained('xlnet-base-cased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
这个例子展示了如何加载预训练的XLNet模型和分词器,并用它们来处理一个简单的文本输入。得到的last_hidden_states可以用于各种下游任务。
结语
XLNet作为一种新型的预训练语言模型,通过创新的排列语言建模目标和先进的网络架构,在多项NLP任务中取得了突破性进展。它不仅在学术界引起了广泛关注,也在工业界得到了实际应用。随着研究的深入和应用的拓展,我们可以期待XLNet及其衍生模型在未来为自然语言处理领域带来更多突破和创新。
通过不断探索和改进像XLNet这样的先进模型,我们正在逐步缩小机器和人类在语言理解和生成能力上的差距。未来,随着硬件性能的提升和算法的优化,我们有理由相信,更加智能和通用的自然语言处理系统将会成为现实。











