
Xorbits:开启数据科学和机器学习的新纪元
在当今数据驱动的时代,数据科学和机器学习已成为各行各业的核心竞争力。然而,随着数据规模的不断扩大和模型复杂度的持续提升,传统的单机开发环境已经难以满足日益增长的计算需求。为了应对这一挑战,Xorbits应运而生,为数据科学家和机器学习工程师提供了一个革命性的开源计算框架。
Xorbits的核心优势
Xorbits是一个功能强大且易于使用的分布式计算框架,专为大规模数据处理和机器学习任务而设计。它的主要优势包括:
-
无缝扩展: Xorbits允许用户轻松地将工作流从笔记本电脑扩展到大型集群,而无需对代码进行大幅修改。这意味着您可以在熟悉的开发环境中工作,同时享受分布式计算的强大性能。
-
高性能处理: 通过充分利用多核CPU和GPU,Xorbits可以显著加速计算过程。无论是在单机上处理大型数据集,还是在分布式环境中训练复杂模型,Xorbits都能提供卓越的性能。
-
兼容性强: Xorbits提供了与多种流行Python库(如pandas、NumPy、PyTorch和XGBoost等)兼容的API,使得现有代码的迁移变得简单直接。
-
内存优化: 对于超出pandas处理能力的大型数据集,Xorbits提供了高效的内存管理解决方案,让您能够轻松处理TB级别的数据。
-
闪电般的速度: 根据基准测试,Xorbits在速度和可扩展性方面均优于其他流行的pandas API框架。
Xorbits的工作原理
Xorbits的核心设计理念是通过简单的API调用,自动将用户的数据科学和机器学习工作负载分布到多个计算节点上。这一过程对用户来说是完全透明的,无需深入了解底层的分布式系统原理。
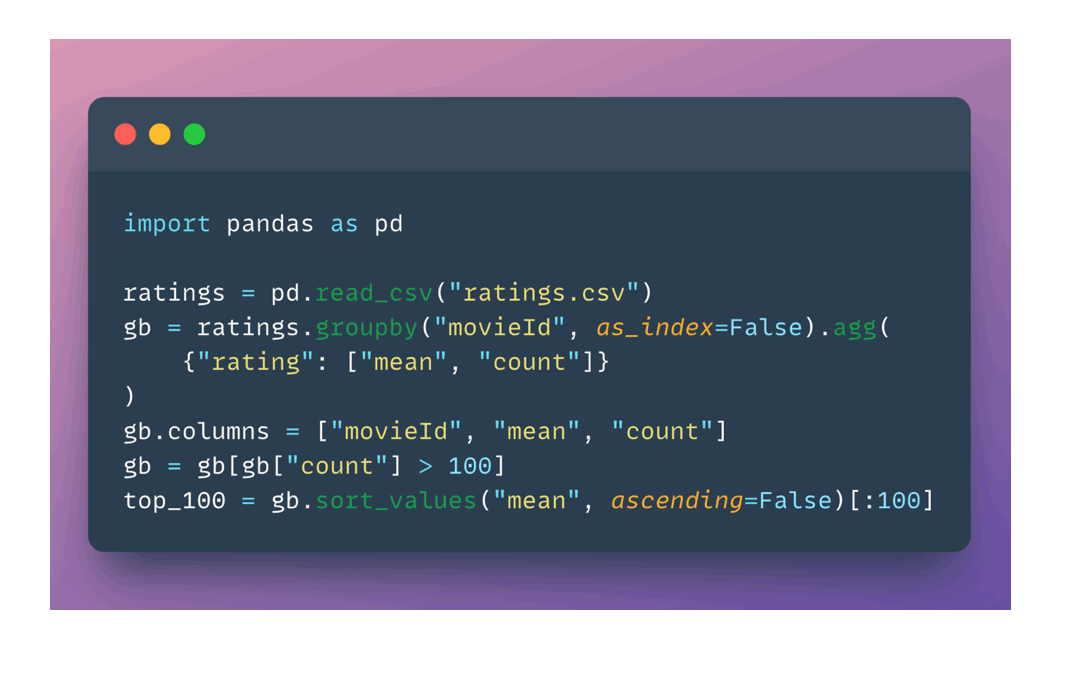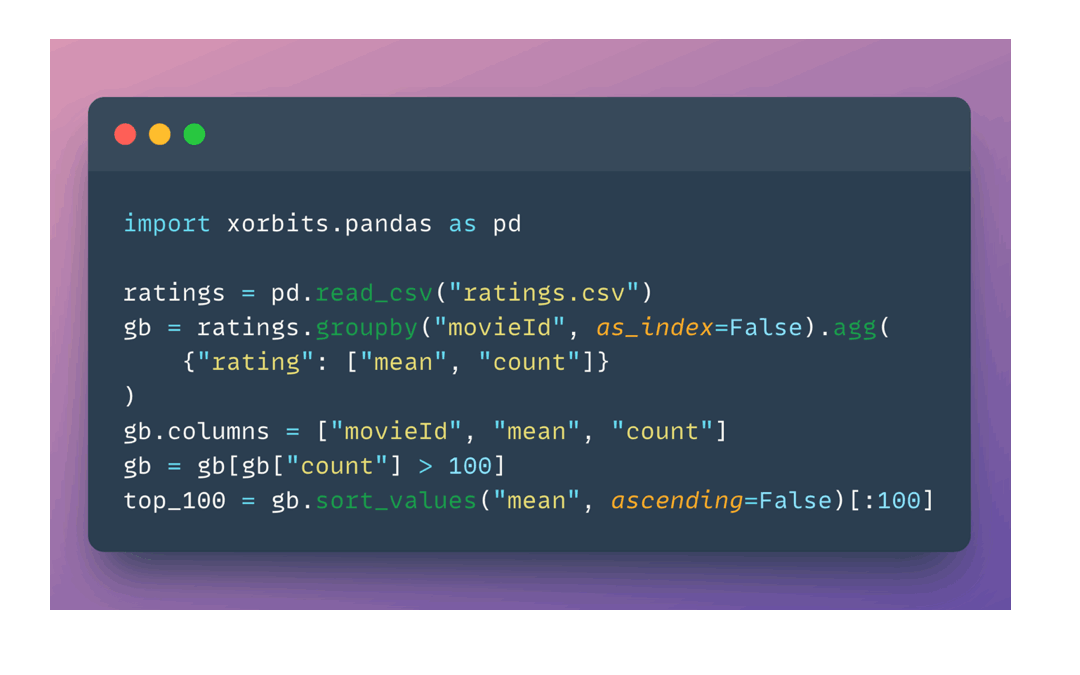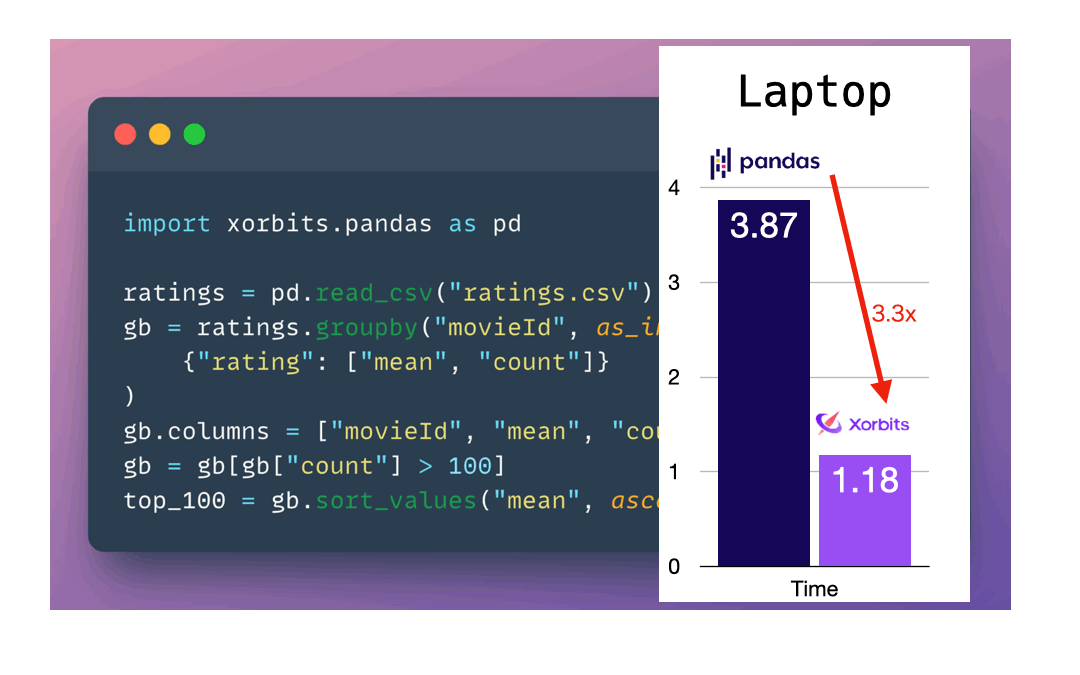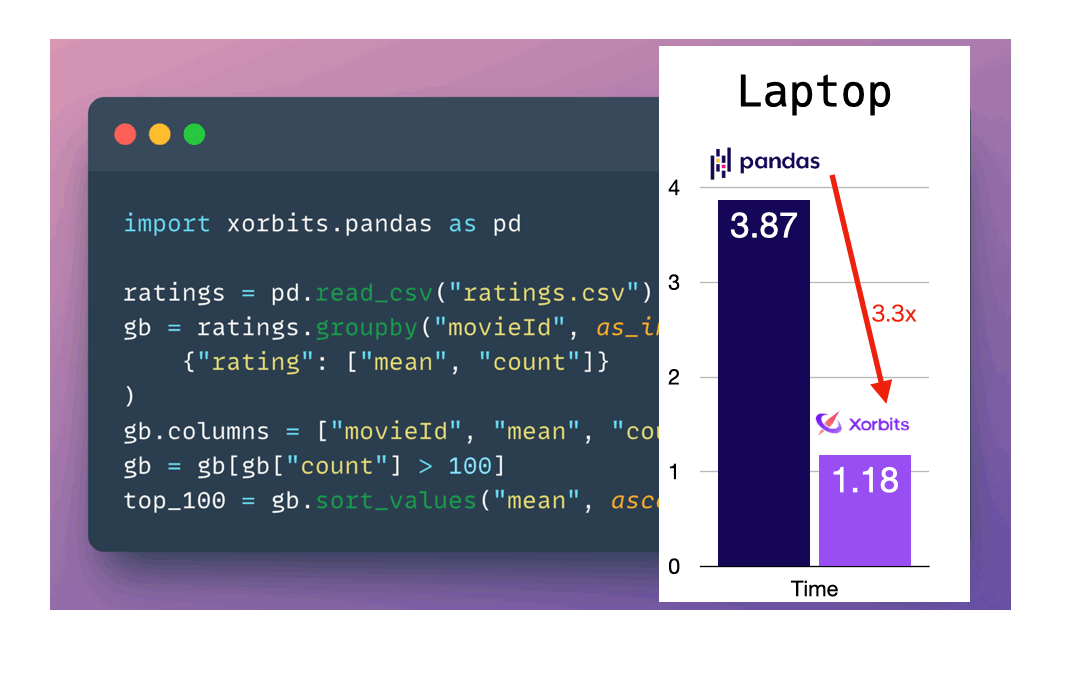
如上图所示,只需简单修改一行代码,就可以将pandas工作流无缝迁移到Xorbits上,享受显著的性能提升。
Xorbits的应用场景
Xorbits适用于广泛的数据科学和机器学习场景,包括但不限于:
-
大规模数据预处理: 对TB级别的结构化和非结构化数据进行清洗、转换和特征工程。
-
分布式机器学习: 在大型数据集上训练和调优复杂的机器学习模型,如深度学习网络、梯度提升树等。
-
实时数据分析: 利用Xorbits的高性能计算能力,对流数据进行实时处理和分析。
-
科学计算: 执行大规模的数值计算、矩阵运算和统计分析。
-
模型部署: 将训练好的大型模型部署到生产环境,支持高并发的推理请求。
开始使用Xorbits
要开始使用Xorbits,您只需通过pip安装即可:
pip install xorbits
安装完成后,您可以轻松地将现有的pandas或NumPy代码迁移到Xorbits:
import xorbits.pandas as pd
# 读取大型CSV文件
df = pd.read_csv("large_dataset.csv")
# 执行数据处理操作
result = df.groupby("category").agg({"sales": "sum", "profit": "mean"})
# 保存结果
result.to_csv("output.csv")
Xorbits的未来发展
Xorbits团队有着雄心勃勃的发展计划,包括:
- 从pandas原生存储转向Arrow原生存储,进一步优化内存使用和计算效率。
- 引入利用向量化和代码生成技术的原生引擎,加速计算过程。
- 不断扩展支持的库和算法,覆盖更广泛的数据科学和机器学习应用场景。
加入Xorbits社区
Xorbits是一个活跃的开源项目,欢迎各界开发者和数据科学家参与贡献。您可以通过以下方式加入Xorbits社区:
- GitHub Issues: 报告bug或提出新功能建议
- Slack: 与其他Xorbits用户和开发者交流
- StackOverflow: 寻求使用帮助
- Twitter: 关注最新动态和特性更新
结语
Xorbits正在重新定义数据科学和机器学习的工作流程。通过提供一个高性能、易用且可扩展的计算框架,Xorbits使得处理大规模数据和训练复杂模型变得前所未有的简单。无论您是数据科学家、机器学习工程师,还是对大规模数据处理感兴趣的开发者,Xorbits都将成为您工具箱中不可或缺的利器。立即尝试Xorbits,体验数据科学和机器学习的未来!









