YData Profiling简介
YData Profiling是一个功能强大的Python库,旨在简化和增强数据探索体验,特别适合统计学家和数据科学家的需求。它的主要目标是提供一行代码就能完成探索性数据分析(EDA)的解决方案,类似于pandas的df.describe()函数的便利性,但提供了更加全面的DataFrame分析,并且可以轻松导出为HTML和JSON等不同格式。
YData Profiling的前身是pandas-profiling,在2023年2月更名为YData Profiling。这次更名不仅仅是名称的变化,还带来了重要的新功能 - 从4.0.0版本开始支持Spark,使其能够处理更大规模的数据集。
主要特性
YData Profiling提供了丰富的功能,使数据分析变得简单高效:
-
类型推断: 自动检测列的数据类型,包括分类、数值、日期等。
-
警告提示: 汇总潜在的数据质量问题,如缺失数据、不准确性、偏度等。
-
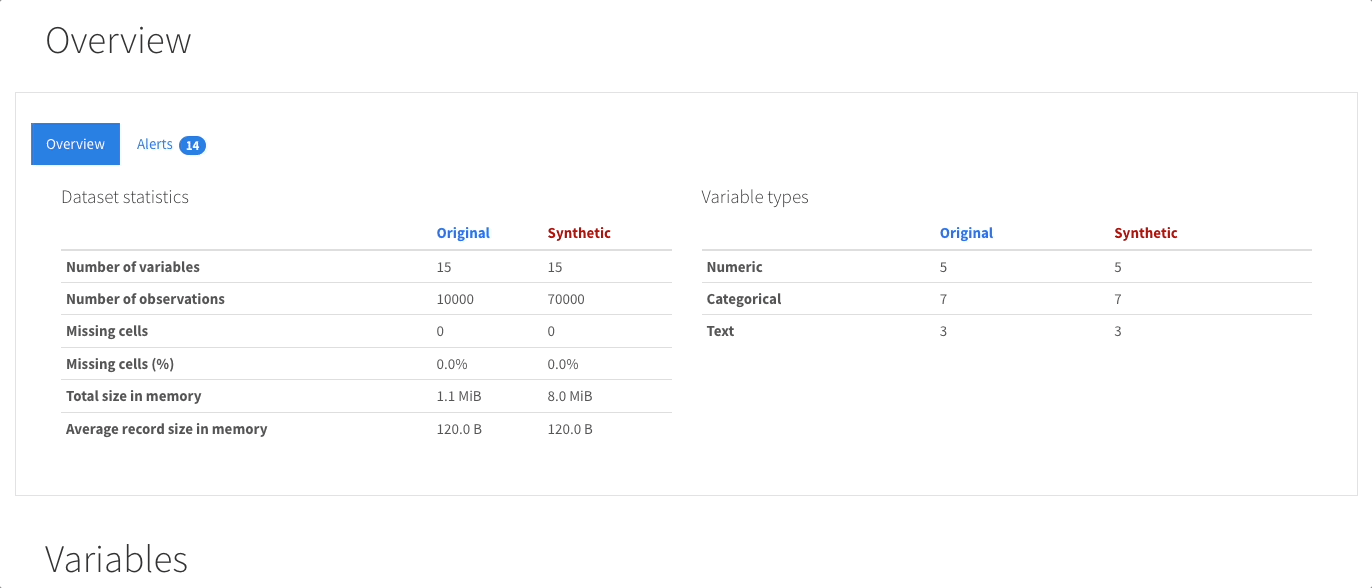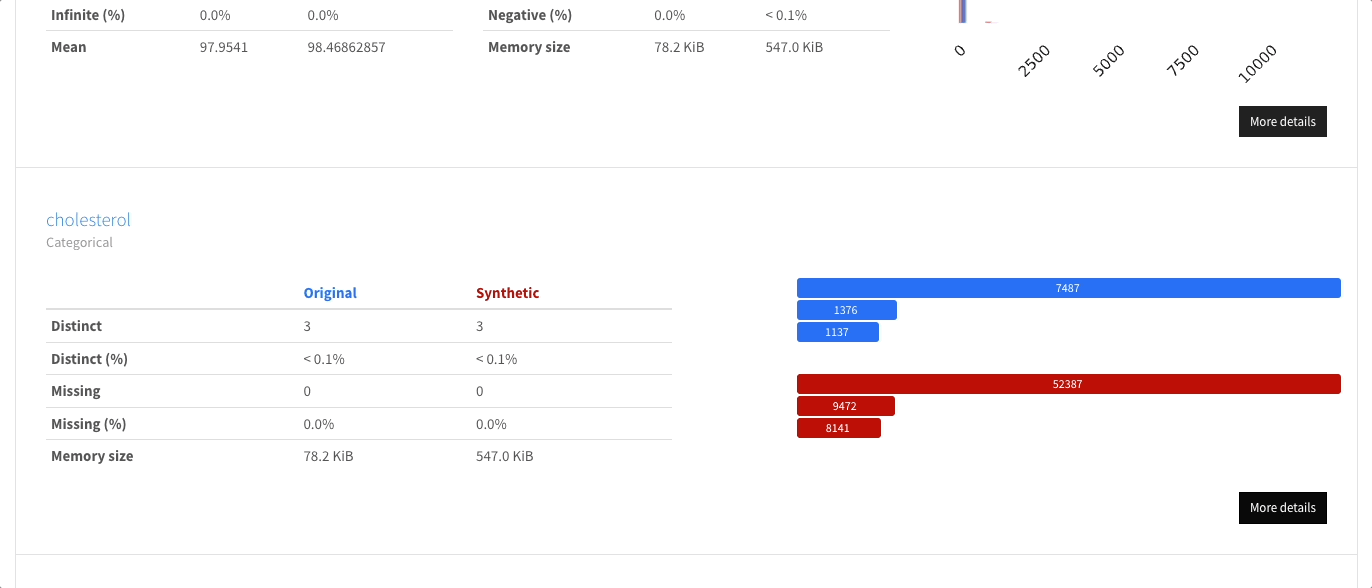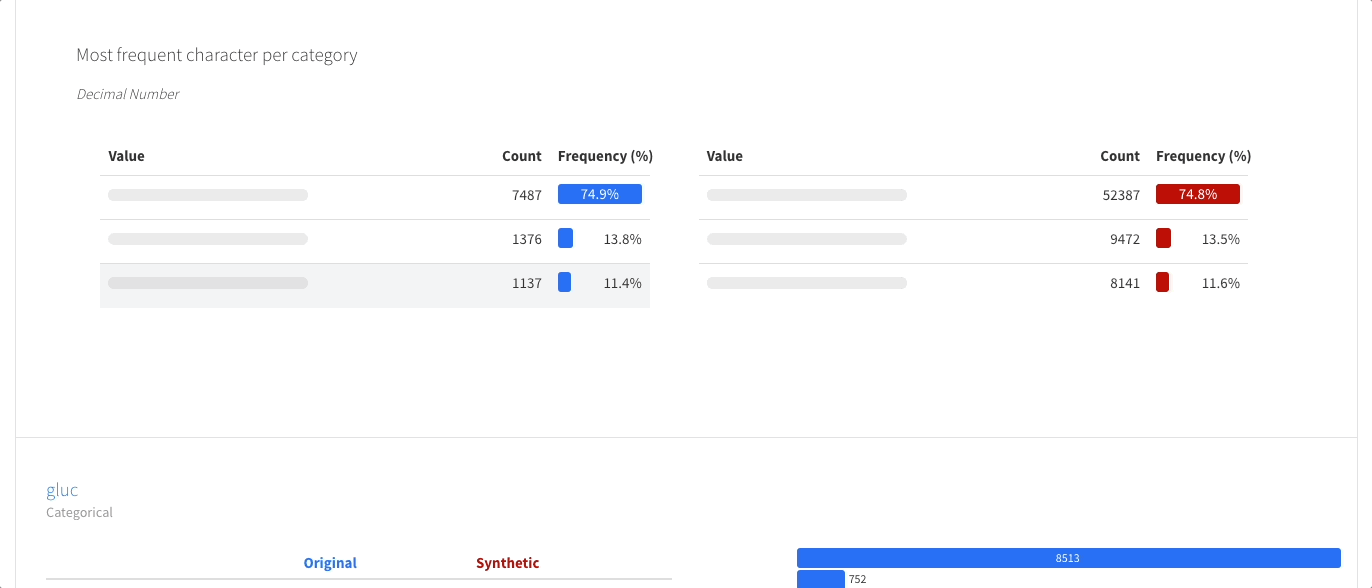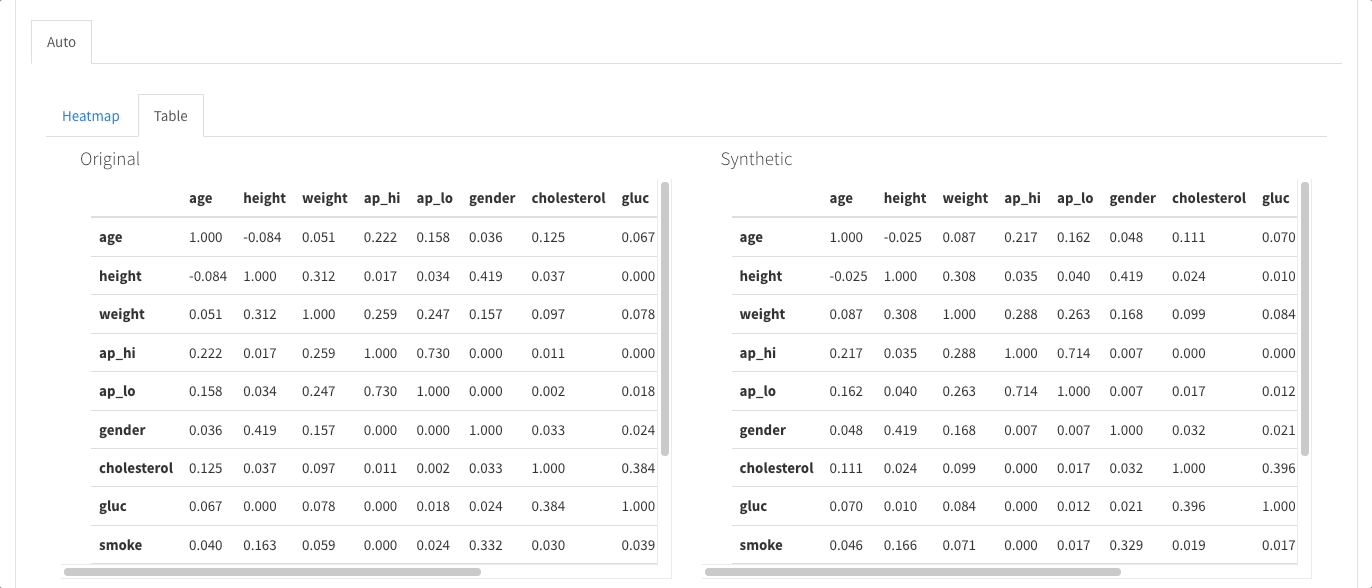
单变量分析: 提供描述性统计和信息丰富的可视化,如分布直方图。
-
多变量分析: 包括相关性、缺失数据的详细分析、重复行,以及变量对之间交互的可视化支持。
-
时间序列分析: 提供与时间相关数据的统计信息,包括自相关和季节性洞察。
-
文本和文件分析: 包括文本类别检测和文件/图像分析,实现全面探索。
-
数据集比较: 通过一行代码即可快速生成数据集比较的完整报告。
-
大规模数据处理: 支持Spark DataFrames,能够处理大规模数据集。
-
灵活的输出格式: 分析结果可以导出为HTML报告,便于在Jupyter Notebook中嵌入或作为独立文件共享。
快速开始
要开始使用YData Profiling,首先需要安装库:
pip install ydata-profiling
或者使用conda:
conda install -c conda-forge ydata-profiling
安装完成后,使用YData Profiling生成报告非常简单:
import pandas as pd
from ydata_profiling import ProfileReport
# 读取数据
df = pd.read_csv("your_data.csv")
# 生成报告
profile = ProfileReport(df, title="Profiling Report")
# 在Jupyter Notebook中显示报告
profile.to_notebook_iframe()
# 或保存为HTML文件
profile.to_file("your_report.html")
应用场景
YData Profiling可以应用于多种数据分析场景:
-
快速数据概览: 在开始深入分析之前,快速了解数据集的整体情况。
-
数据质量评估: 自动识别缺失值、异常值和数据分布问题。
-
特征工程准备: 通过了解变量之间的关系,为特征工程提供洞察。
-
时间序列数据分析: 专门的时间序列模式可以揭示数据的时间相关特性。
-
数据集比较: 轻松比较不同版本的数据集,识别变化和差异。
-
大规模数据分析: 利用Spark支持,处理超出传统pandas能力范围的大型数据集。
-
报告生成: 生成专业的数据分析报告,便于与团队成员和利益相关者共享。
高级使用
YData Profiling还提供了一些高级功能,以满足更复杂的分析需求:
- 自定义配置: 可以通过参数调整报告的内容和外观,例如:
profile = ProfileReport(df, minimal=True, explorative=True)
- 数据集比较: 比较两个数据集并生成差异报告:
train_report = ProfileReport(train_df, title="Training Data")
test_report = ProfileReport(test_df, title="Test Data")
comparison_report = train_report.compare(test_report)
- 时间序列分析: 对时间序列数据进行专门的分析:
profile = ProfileReport(df, tsmode=True, sortby="date_column")
- 大规模数据处理: 使用Spark支持处理大型数据集:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark_df = spark.read.csv("large_dataset.csv", header=True, inferSchema=True)
profile = ProfileReport(spark_df, explorative=True)
结语
YData Profiling为数据科学家和分析师提供了一个强大而简单的工具,大大简化了探索性数据分析的过程。通过自动生成全面的数据报告,它不仅节省了大量时间,还能帮助发现可能被忽视的数据特征和问题。无论是处理小型数据集还是大规模数据,YData Profiling都能提供valuable insights,使数据分析工作更加高效和深入。
随着数据规模的不断增长和分析需求的日益复杂,YData Profiling将继续发展,为数据专业人士提供更多强大的功能。它的开源性质也意味着社区可以参与其发展,不断改进和扩展其功能。对于任何希望提高数据分析效率的人来说,YData Profiling都是一个值得尝试的工具。