
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文ViTamin:在视觉语言时代设计可扩展的视觉模型
🔥 已得到timm和OpenCLIP的官方支持。感谢@rwightman!
一行代码调用ViTamin:
model = timm.create_model('vitamin_xlarge_384')
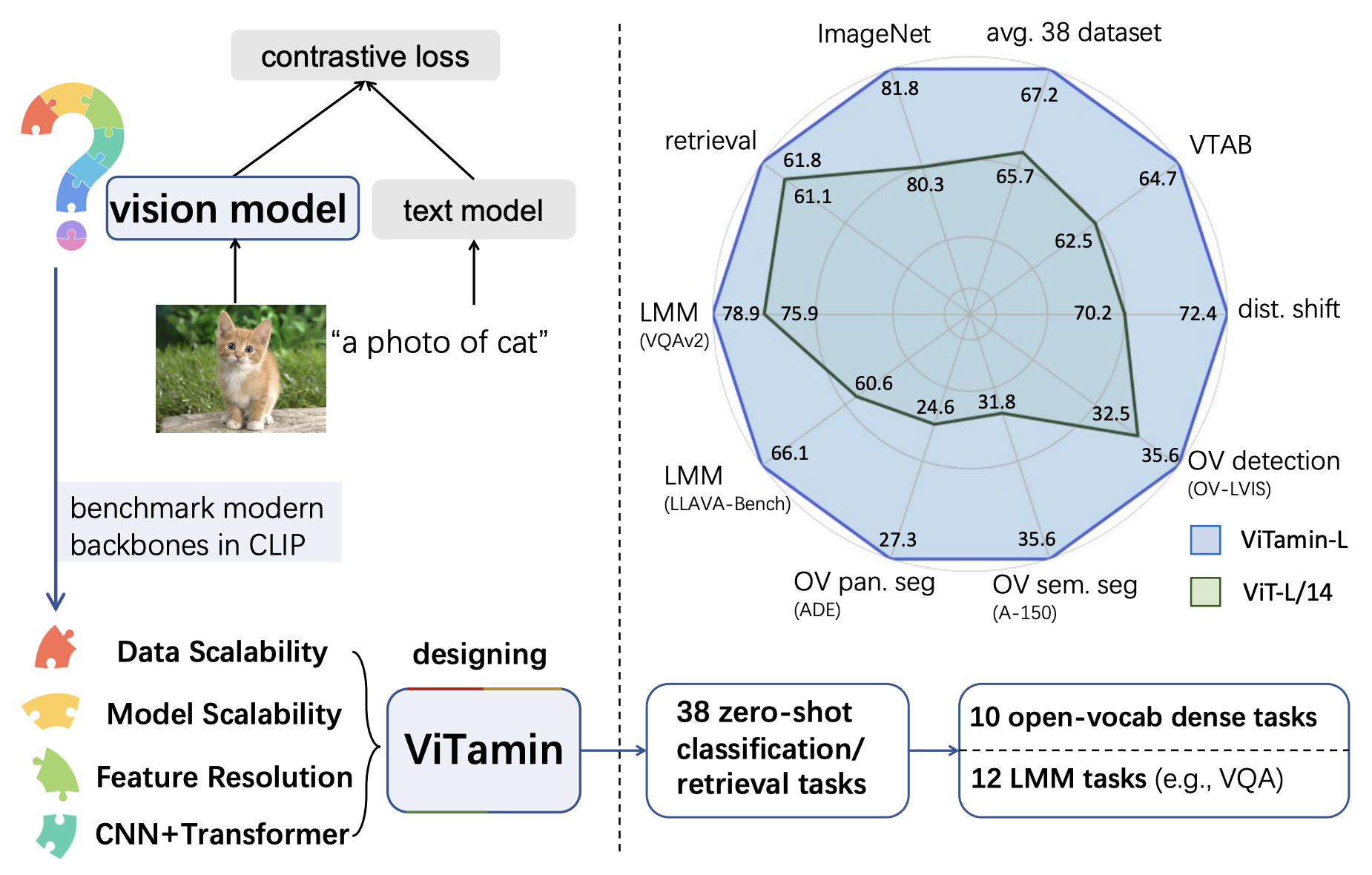
ViTamin-XL仅有436M参数,在公开的DataComp-1B数据集上训练,实现了令人印象深刻的**82.9%**零样本ImageNet准确率。
ViTamin-L在七个开放词汇分割基准测试中创下新的最高水平,并显著提升了大型多模态模型(如LLaVA)的能力。
🤗 ViTamin模型卡片的HuggingFace集合已发布!查看模型卡片!
快速入门
目前包括以下任务的代码和模型:
ViTamin预训练:查看./ViTamin/README.md快速入门,包含CLIP预训练/微调流程和零样本评估流程。
开放词汇检测和分割:查看用于开放词汇检测的ViTamin和用于开放词汇分割的ViTamin。
大型多模态模型:查看用于大型多模态模型的ViTamin。
我们还支持使用Hugging Face模型jienengchen/ViTamin-XL-384px的ViTamin。
import torch
import open_clip
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModel.from_pretrained(
'jienengchen/ViTamin-XL-384px',
trust_remote_code=True).to(device).eval()
image = Image.open('./image.png').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('jienengchen/ViTamin-XL-384px')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
tokenizer = open_clip.get_tokenizer('hf-hub:laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K')
text = tokenizer(["a photo of vitamin", "a dog", "a cat"]).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features, text_features, logit_scale = model(pixel_values, text)
text_probs = (100.0 * image_features @ text_features.to(torch.float).T).softmax(dim=-1)
print("Label probs:", text_probs)
在DataComp-1B上CLIP预训练的主要结果
我们将在Hugging Face上提供61个训练好的VLM(48个基准测试 + 13个最佳表现)供社区使用。敬请期待!
| 图像编码器 | 🤗 HuggingFace | 图像尺寸 | 区块数 | 文本编码器深度/宽度 | 已见样本数 (B) | 可训练参数数量 图像+文本 (M) | MACs 图像+文本 (G) | ImageNet准确率 | 38个数据集平均值 | ImageNet分布偏移 | VTAB | 检索 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViTamin-L | 链接 | 224 | 196 | 12/768 | 12.8 | 333.3+123.7 | 72.6+6.6 | 80.8 | 66.7 | 69.8 | 65.3 | 60.3 |
| ViTamin-L | 链接 | 256 | 256 | 12/768 | 12.8+0.2 | 333.4+123.7 | 94.8+6.6 | 81.2 | 67.0 | 71.1 | 65.3 | 61.2 |
| ViTamin-L | 链接 | 336 | 441 | 12/768 | 12.8+0.2 | 333.6+123.7 | 163.4+6.6 | 81.6 | 67.0 | 72.1 | 64.4 | 61.6 |
| ViTamin-L | 链接 | 384 | 576 | 12/768 | 12.8+0.2 | 333.7+123.7 | 213.4+6.6 | 81.8 | 67.2 | 72.4 | 64.7 | 61.8 |
| ViTamin-L2 | 链接 | 224 | 196 | 24/1024 | 12.8 | 333.6+354.0 | 72.6+23.3 | 80.9 | 66.4 | 70.6 | 63.4 | 61.5 |
| ViTamin-L2 | 链接 | 256 | 256 | 24/1024 | 12.8+0.5 | 333.6+354.0 | 94.8+23.3 | 81.5 | 67.4 | 71.9 | 64.1 | 63.1 |
| ViTamin-L2 | 链接 | 336 | 441 | 24/1024 | 12.8+0.5 | 333.8+354.0 | 163.4+23.3 | 81.8 | 67.8 | 73.0 | 64.5 | 63.6 |
| ViTamin-L2 | 链接 | 384 | 576 | 24/1024 | 12.8+0.5 | 334.0+354.0 | 213.4+23.3 | 82.1 | 68.1 | 73.4 | 64.8 | 63.7 |
| ViTamin-XL | 链接 | 256 | 256 | 27/1152 | 12.8+0.5 | 436.1+488.7 | 125.3+33.1 | 82.1 | 67.6 | 72.3 | 65.4 | 62.7 |
| ViTamin-XL | 链接 | 384 | 576 | 27/1152 | 12.8+0.5 | 436.1+488.7 | 281.9+33.1 | 82.6 | 68.1 | 73.6 | 65.6 | 63.8 |
| ViTamin-XL | 链接 | 256 | 256 | 27/1152 | 40 | 436.1+488.7 | 125.3+33.1 | 82.3 | 67.5 | 72.8 | 64.0 | 62.1 |
| ViTamin-XL | 链接 | 336 | 441 | 27/1152 | 40+1 | 436.1+488.7 | 215.9+33.1 | 82.7 | 68.0 | 73.9 | 64.1 | 62.6 |
| ViTamin-XL | 链接 | 384 | 576 | 27/1152 | 40+1 | 436.1+488.7 | 281.9+33.1 | 82.9 | 68.1 | 74.1 | 64.0 | 62.5 |
下游任务主要结果
开放词汇检测
| 图像编码器 | 检测器 | OV-COCO (AP50novel) | OV-LVIS (APr) |
|---|---|---|---|
| ViT-L/14 | Sliding F-ViT | 36.1 | 32.5 |
| ViTamin-L | Sliding F-ViT | 37.5 | 35.6 |
开放词汇分割
| 图像编码器 | 分割器 | ADE | Cityscapes | MV | A-150 | A-847 | PC-459 | PC-59 | PAS-21 |
|---|---|---|---|---|---|---|---|---|---|
| ViT-L/14 | Sliding FC-CLIP | 24.6 | 40.7 | 16.5 | 31.8 | 14.3 | 18.3 | 55.1 | 81.5 |
| ViTamin-L | Sliding FC-CLIP | 27.3 | 44.0 | 18.2 | 35.6 | 16.1 | 20.4 | 58.4 | 83.4 |
注:全景数据集(ADE、CityScapes、MV)使用PQ指标。语义数据集(A-150、A-847、PC-459、PC-59、PAS-21)使用mIoU指标。
大型多模态模型
| 图像编码器 | 图像尺寸 | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MME | MM-Bench | MM-B-CN | SEED | LLaVA-Wild | MM-Vet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViTamin-L | 336 | 78.4 | 61.6 | 51.1 | 66.9 | 58.7 | 84.6 | 1421 | 65.4 | 58.4 | 57.7 | 64.5 | 33.6 |
| ViTamin-L | 384 | 78.9 | 61.6 | 55.4 | 67.6 | 59.8 | 85.5 | 1447 | 64.5 | 58.3 | 57.9 | 66.1 | 33.6 |
引用ViTamin
@inproceedings{chen2024vitamin,
title={ViTamin:在视觉语言时代设计可扩展的视觉模型},
author={陈杰能 and 于启航 and 沈晓辉 and Yuille, Alan and 陈良杰},
booktitle={IEEE/CVF 计算机视觉与模式识别会议论文集},
year={2024}
}











