


思维链中心:测量大语言模型的推理能力
 "一幅幻想图,展示了深蓝夜空中的一串星链,数字艺术,超高分辨率"。Midjourney V5制作
"一幅幻想图,展示了深蓝夜空中的一串星链,数字艺术,超高分辨率"。Midjourney V5制作
作者:傅尧、欧立图、陈明宇、万宇豪、彭昊、Tushar Khot、陈文虎
来自爱丁堡大学、华盛顿大学、艾伦人工智能研究所、滑铁卢大学
近期,大语言模型领域取得了许多进展。许多人声称,一个不到100亿参数的小模型可以达到与GPT-3.5相当的性能。真的吗?
在日常对话中,GPT-3.5和GPT-4之间的区别可能并不明显。差异主要体现在当任务复杂度达到一定阈值时 — GPT-4更可靠、更具创造性,能够处理更加微妙的指令。 — GPT-4发布博客
关键的区别在于模型是否能完成复杂任务,就像老话说的:"闲聊容易,让我看看你的推理能力。"这就是为什么我们汇编了一系列复杂推理任务,包括数学(GSM8K)、科学(MATH、TheoremQA)、符号(BBH)、知识(MMLU、C-Eval)、编程(HumanEval)、事实(SummEdits)和长文本(RepoBench、Qspr、QALT、BkSS),以衡量模型在具有挑战性任务上的表现。
更重要的��是,我们预见大语言模型将成为下一代计算平台,并孕育出基于大语言模型的新应用生态系统。届时,思维链提示工程将成为下一代系统调用和shell脚本。
思维链中心的可信度来自于精心挑选的数据集和模型,这些数据集和模型可以明确地帮助大语言模型的发展。思维链中心的结果和脚本正被大语言模型领域的领先工业和学术机构所使用和参考。我们将任务分为三类:主要、实验性和长文本。
- 主要:稳定且被大语言模型开发者持续参考的数据集。
- 实验性:有潜力测试未来大语言模型能力的数据集。
- 长文本:需要对超长文本进行推理的数据集,这是未来大语言模型的一个重要发展方向。
| 类别 | 数据集 | 描述 |
|---|---|---|
| 主要 | GSM8K | 小学级数学应用题 |
| 主要 | MATH | 竞赛级数学和科学问题 |
| 主要 | MMLU | 多学科知识 |
| 主要 | BBH | 具有挑战性的语言和符号推理 |
| 主要 | HumanEval | Python编程 |
| 主要 | C-Eval | 中文多学科知识 |
| 实验性 | TheoremQA | 定理证明 |
| 实验性 | SummEdits | 事实推理 |
| 长文本 | Qspr | 基于研究论文的问答 |
| 长文本 | QALT | 基于长文章和故事的多选题 |
| 长文本 | BkSS | 小说片段摘要的重新排序 |
[征集贡献]:诚邀社区成员:
- 发送PR以填补表格中缺失的数据
- 提出issue以建议/头脑风暴新的任务/基准,用�于衡量超长文本的推理能力
- 提出issue以建议/头脑风暴新的任务/基准,用于衡量复杂API调用和工具使用
- 提出issue以建议其他能明显区分模型性能的优秀任务/基准
- 提出issue以建议可添加到表格中的新模型
[2023年12月10日更新]:
- 添加Gemini、Yi-34B、DeepSeek 67B
- 更新长文本部分 — 我们将对这部分有更多更新
- Mistral 7B8E MoE模型结果预览
| 基准测试 | Mistral 7B Dense | Mistral 7Bx8E=50B | Yi-34B | DeepSeek-67B | LLaMA2 70B |
|---|---|---|---|---|---|
| Arc-c | 59.98 | 66.38 | 64.59 | 65.44 | - |
| HellaSwag | 83.31 | 86.61 | 85.69 | 87.10 | - |
| MMLU | 64.16 | 71.73 | 76.35 | 71.78 | 68.9 |
| TruthfulQA | 42.15 | 48.55 | 56.23 | 51.08 | 50.18 |
| Winogrande | 78.37 | 82.40 | 83.03 | 84.14 | - |
| GSM8K | 37.83 | 57.09 | 50.64 | 56.71 | 56.8 |
[2023年6月20日更新]:
- 将主要(稳定且被大语言模型开发者持续参考的数据集)和实验性(有潜力测试未来大语言模型能力的数据集)排行榜分开。
- 添加长文本部分(实验性)
[2023年6月9日更新]:为LLaMA和Falcon添加MMLU的评估脚本
[2023年6月1日更新]:添加SummEdits
[2023年5月27日更新]:添加TheoremQA,增加Vicuna、Alpaca、InstructCodeT5。
</details>排行榜 - 主要
| 模型 | 参数量 | 类型 | GSM8K | MATH | MMLU | BBH | HumanEval | C-Eval |
|---|---|---|---|---|---|---|---|---|
| Gemini Ultra | ? | 基础 | - | 53.2 | 83.7 | 83.6 | 74.4 | - |
| gpt-4 | ? | RLHF | 92.0 | 42.5 | 86.4 | - | 67.0 | 68.7* |
| claude-2 | ? | RLHF | 88 | - | 78.5 | - | 71.2 | - |
| Gemini Pro | ? | 基础 | - | 32.6 | 71.8 | 75.0 | 67.7 | - |
| claude-v1.3 | ? | RLHF | 81.8* | - | 75.6* | 67.3* | - | 54.2* |
| PaLM-2-Unicorn | ? | 基础 | 80.7 | 34.3 | 78.3 | 78.1 | - | - |
| Mistral MoE | 7Bx8E=46B | 基础 | 57.9 | - | 71.3 | - | - | - |
| DeepSeek | 67B | 基础 | 56.7 | 18.7 | 71.7 | 68.7 | 42.7 | 66.1 |
| Yi | 34B | 基础 | 50.6 | - | 76.3 | 54.3 | - | 81.4 |
| gpt-3.5-turbo | ? | RLHF | 74.9* | - | 67.3* | 70.1* | 48.1 | 54.4* |
| claude-instant | ? | RLHF | 70.8* | - | 61.3* | 66.9* | - | 45.9* |
| text-davinci-003 | ? | RLHF | - | - | 64.6 | 70.7 | - | - |
| code-davinci-002 | ? | 基础 | 66.6 | 19.1 | 64.5 | 73.7 | 47.0 | - |
| text-davinci-002 | ? | SIFT | 55.4 | - | 60.0 | 67.2 | - | - |
| Minerva | 540B | SIFT | 58.8 | 33.6 | - | - | - | - |
| Flan-PaLM | 540B | SIFT | - | - | 70.9 | 66.3 | - | - |
| Flan-U-PaLM | 540B | SIFT | - | - | 69.8 | 64.9 | - | - |
| PaLM | 540B | 基础 | 56.9 | 8.8 | 62.9 | 62.0 | 26.2 | - |
| LLaMA-2 | 70B | 基础 | 56.8 | - | 68.9 | 51.2 | 29.9 | - |
| LLaMA | 65B | 基础 | 50.9 | 10.6 | 63.4 | - | 23.7 | 38.8* |
| PaLM | 64B | 基础 | 52.4 | 4.4 | 49.0 | 42.3 | - | - |
| Falcon | 40B | 基础 | - | - | 49.0* | - | - | - |
| Vicuna | 33B | SIFT | - | - | 59.2 | - | - | - |
| LLaMA | 33B | 基础 | 35.6 | 7.1 | 57.8 | - | 21.7 | - |
| InstructCodeT5+ | 16B | SIFT | - | - | - | - | 35.0 | - |
| StarCoder | 15B | 基础 | 8.4 | 15.1 | 33.9 | - | 33.6 | - |
| Vicuna | 13B | SIFT | - | - | - | 52.1 | - | - |
| LLaMA | 13B | 基础 | 17.8 | 3.9 | 46.9 | - | 15.8 | - |
| Flan-T5 | 11B | SIFT | 16.1* | - | 48.6 | 41.4 | - | - |
| Alpaca | 7B | SIFT | - | - | - | - | - | - |
| LLaMA | 7B | 基础 | 11.0 | 2.9 | 35.1 | - | 10.5 | - |
| Flan-T5 | 3B | SIFT | 13.5* | - | 45.5 | 35.2 | - | - |
我们称这些数据集为"主要"数据集,因为它们在主要机构的大语言模型开发中相当稳定且被广泛使用。基础指预训练检查点。SIFT指经过有监督指令微调后的检查点。RLHF指经过人类反馈强化学习后的检查点。带星号*的数字来自我们自己的运行结果,其他则来自多个来源,我们会在下面解释。所有方法都以准确率衡量,数值越高越好。
排行榜 - 实验性:长上下文
| 模型 | 参数数量 | 上下文长度 | 类型 | Qspr | QALT | BkSS |
|---|---|---|---|---|---|---|
| 人类 | ? | ? | ? | 67.7 | 93.5 | ? |
| gpt-4 | ? | 8K | RLHF | 50.7 | 89.2 | 60.5 |
| claude-v1.3 | ? | 8K | RLHF | 52.3 | 84.8 | 47.4 |
| claude-v1.3 | ? | 4K | RLHF | 47.7 | 76.8 | 37.6 |
| PaLM-2-Unicorn | ? | - | 基础 | - | - | - |
| PaLM-2-bison | ? | - | RLHF | - | - | - |
| gpt-3.5-turbo | ? | 4K | RLHF | 49.3 | 66.6 | 49.8 |
| claude-instant | ? | - | RLHF | - | - | - |
| text-davinci-003 | ? | 4K | RLHF | 52.7 | 69.0 | 49.5 |
| text-davinci-002 | ? | - | SIFT | - | - | - |
| LLaMA | 65B | - | 基础 | - | - | - |
| Falcon | 40B | - | 基础 | - | - | - |
| Flan-UL2 | 20B | 8K | SIFT | 56.9 | 75.6 | 14.0 |
| LLaMA | 33B | - | 基础 | - | - | - |
| Vicuna | 13B | - | SIFT | - | - | - |
| LLaMA | 13B | - | 基础 | - | - | - |
| Flan-T5 | 11B | 8K | SIFT | 48.3 | 75.2 | 15.1 |
| Flan-T5 | 11B | 4K | SIFT | 46.5 | 70.8 | 16.4 |
| T0pp | 11B | 8K | SIFT | 25.0 | 21.4 | 0.0 |
| Alpaca | 7B | - | SIFT | - | - | - |
| LLaMA | 7B | - | 基础 | - | - | - |
| Flan-T5 | 3B | 8K | SIFT | 46.6 | 69.6 | 2.2 |
与其他重要评估有何不同?
- HeLM使用仅答案提示,我们使用思维链提示
- HeLM评估所有内容。我们只关注复杂推理,这是大语言模型能力的关键区别。
- Open LLM Leaderboard评估开源语言模型。我们考虑大多数领先的模型。
- 目前,Open LLM Leaderboard上LLaMA 65B的性能仅为48.8,远低于论文中报告的63.4。这对LLaMA和Falcon之间的比较产生了质疑。
- 在我们的复现中,使用MMLU官方提示+贪婪解码+fp16,我们得到了61.4的结果。我们的结果更倾向于原始LLaMA数字,并对Open LLM Leaderboard的结果提出质疑。
- 我们的评估脚本相当简单,大多数参数为默认值,没有复杂的提示工程。我们鼓励社区尝试我们的脚本并复现我们的结果。
- 根据Nathan Lambert的说法,HuggingFace目前正在重新设计Open LLM Leaderboard的后端,结果可能会发生变化(2023年6月10日)。
- Chatbot Arena评估聊天机器人模型,这更面向用户部署。我们的评估更面向开发者,我们不仅考虑聊天机器人,还考虑基础模型。
模型排名方式
- 如果我们知道模型规模,我们按规模排名。
- 如果我们不知道模型规模,我们按GSM8K排名,这是衡量思维链数学推理性能的经典基准。
- 这当然不是唯一的指标,但一个很好的解释是"模型在保持其他通用能力的同时,数学能力如何" - 这也非常困难。
- GPT-4已经在GSM8k训练集上预训练过,其他模型可能没有。因此对于GPT-4,它在GSM8k上的表现是分布内泛化,而对于其他模型则是分布外泛化。即便如此,FlanT5也在GSM8k上训练过,仍然表现出性能差异。
- 总的来说,由于多种因素(是否在相应的训练集上训练,是否在代码上训练,是否优化提示等),严格比较模型性能非常困难。请将我们的结果视为近似参考。
数字来源
- GPT-4来自其网站和Bubeck等人2023年3月。请注意,Bubeck使用的版本是GPT-4 Early,据说比GPT-4 Launch更强大(OpenAI为使GPT-4更安全付出了大量对齐成本)。
- *-davinci-00*和*PaLM来自Flan-PaLM论文附录。
- code-davinci-002是GPT-3.5系列的基础模型,但遗憾的是现在无法访问。
- LLaMA来自LLaMA论文。
- 我们已经使用官方MMLU提示和默认的HuggingFace Transformers
generate()函数复现了LLaMA在MMLU上的结果,我们的结果与官方数字非常匹配。更多详情请参见此处。
- 我们已经使用官方MMLU提示和默认的HuggingFace Transformers
- Falcon在MMLU上的结果来自我们自己的脚本此处。
- PaLM-2来自他们的技术报告。
- Claude来自我们自己的测试脚本,请参见下面关于如何运行它的说明。
- LLaMA模型、PaLM和StartCoder在HumanEval上的结果来自HuggingFace报告。Code-davinci-002在HumanEval上的表现来自CodeT5+论文
- C-Eval来自他们的网站
- TheoremQA来自他们的github
- SummEdits来自他们的github和论文
- 长上下文部分来自zero-scrolls论文和排行榜
- Vicuna在MMLU上的表现来自Chatbot Arena
当前结果
- GPT-4在GSM8K和MMLU上明显优于所有其他模型。
- 65B LLaMA与text/code-davinci-002非常接近,这意味着如果正确进行SFT和RLHF,我们很可能基于65B LLaMA复制出ChatGPT
- Claude是唯一一个可与GPT系列相媲美的模型家族。
- 在GSM8K上,gpt-3.5-turbo相比text-davinci-003有所改进。这证实了OpenAI 2023年1月30日发布说明中的"改进了数学能力"。
- 在MMLU上,gpt-3.5-turbo略优于text-davinci-003。但这种程度的差距并不显著。
- 还要记住,gpt-3.5-turbo的价格是text-davinci-003的十分之一。
- 同时要注意,GPT-4/3.5在GSM8K上的表现并非真正的少样本学习——在GPT-4报告中提到,他们将部分GSM8K训练集混入模型训练中。
- LLaMA在MMLU上的表现来自其论文,可能不是CoT而是AO。通常在MMLU上,AO略优于CoT。因此LLaMA在MMLU上的数据可能略有高估。
可视化
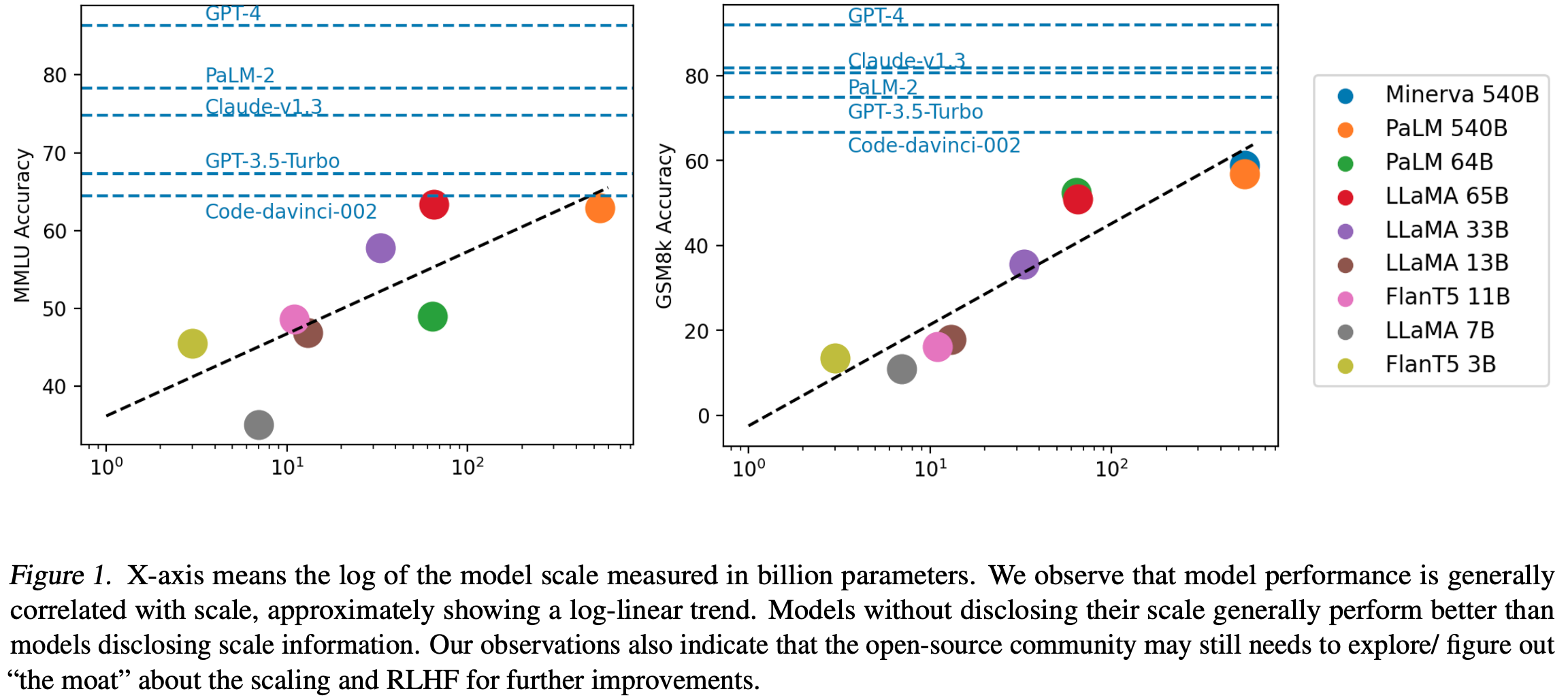
- 开源和闭源模型之间存在明显差距。
- 大多数顶级模型都经过RLHF。
- LLaMA 65B与code-davinci-002非常接近。
- 现有结果强烈表明,如果在LLaMA上正确进行RLHF,它可能接近ChatGPT-3.5。
关于任务的更多信息
- GSM8K:8千道小学数学题。——该数据集上的性能提升直接反映了与LLM日常交互时的数学能力
- MMLU:57个学科下的1.5万道问题,涵盖高中和大学知识
- MATH(困难!):7个类别内的1.2万道问题,非常困难的数学和自然科学题。所有当前模型都很吃力。
- BBH:23个子集内的6.5千道问题,符号和文本推理
- HumanEval:一个经典的手写数据集,包含164道Python问题,用于评估编码能力。
- C-Eval:一个涵盖52个学科的1.3万道中文多选题知识测试集合。
- TheoremQA(困难!):800对问答对,涵盖数学、电气与计算机科学、物理和金融领域的350多个定理。
- SummEdits:10个领域内的6.3千道事实一致性推理问题。
运行
MMLU
cd MMLU mkdir outputs API_KEY=<your_api_key> # GPT-3.5-Turbo python run_mmlu_gpt_3.5_turbo.py --api_key=${API_KEY} # Claude-v1.3 python run_mmlu_claude.py --api_key=${API_KEY} --engine=claude-v1.3 # LLaMA LLAMA_CKPT_DIR=<模型检查点路径> PARAM_SIZE=65 # 7, 13, 33, 65 MODEL_TYPE=llama # ["llama", "falcon"] python run_mmlu_open_source.py --ckpt_dir ${LLAMA_CKPT_DIR} --param_size ${PARAM_SIZE} --model_type ${MODEL_TYPE}
GSM8k
cd gsm8k mkdir outputs # 运行gpt-3.5 # codex_gsm8k_complex.ipynb -- code-davinci-002 + 复杂提示 # gpt3.5turbo_gsm8k_complex.ipynb -- gpt-3.5-turbo + 复杂提示 # 运行claude python run_gsm8k_claude.py\ --anthropic_key=${API_KEY}\ --prompt_file=lib_prompt/prompt_original.txt\ --engine=claude-v1.3\ --output_file=outputs/gsm8k_claude_v1.3_original_test.txt # 运行FlanT5 # flan_t5_11b_gsm8k.ipynb
BBH
cd BBH mkdir outputs # 然后运行jupyter notebook查看企鹅数据集示例 cd penguins # gpt3.5trubo_penguins_original.ipynb # 或者运行脚本处理所有数据集 API_KEY=<your_api_key> TASK=<all | multiple_choice | free_form> python run_bbh_gpt_3.5_turbo.py --api_key=${API_KEY} --task=${TASK} # 默认task=all python run_bbh_claude_v1.3.py --api_key=${API_KEY} --model_index=claude-v1.3 --task=${TASK} # 默认task=all
常见问题
- 模型性能的敏感度非常高。
- 不幸的是,这是LLM的本质。我们目前正在努力标准化提示(请参阅这里的初步进展),并将更新更多相关内容。
- 复杂度基础提示论文中使用的提示是什么?
- 请参阅
research/complexity_based_prompting/
- 请参阅
- 我想尝试一些开源模型
- 请参阅
gsm8k/flan_t5_11b_gsm8k.ipynb作为起点
- 请参阅
- 有些提示中包含错误答案
- 是的,但我们保持原样,因为它们在原始论文中使用
- 通常模型对提示扰动具有鲁棒性:即使提示中有时存在错误,只要提示的格式与相应任务有关,模型往往只关注格式,忽略提示错误,并做出自己的预测。
- 有关模型如何忽略提示中的错误的更多分析,请参阅https://arxiv.org/abs/2202.12837和https://arxiv.org/abs/2212.10001
我想了解更多关于构建用于推理任务的LLM的信息
我们之前的博客文章中详细讨论了一个路线图。
总的来说,构建强大推理能力模型的方法与通用LLM相同:预训练、微调、强化学习。以下列出一些应该考虑的非�常重要的论文:
预训练/继续训练
- Lewkowycz等人,2022年。Minerva:用语言模型解决定量推理问题
- Taylor等人,2022年。Galactica:用于科学的大型语言模型
微调
- Chung等人,2022年。扩展指令微调语言模型
- Li等人,2022年。用AlphaCode生成竞赛级代码
- Fu等人,2023年。专门化较小语言模型以实现多步推理
强化学习
- Uesato等人,2022年。通过过程和结果反馈解决数学应用题
- Le等人,2022年。CodeRL:通过预训练模型和深度强化学习掌握代码生成
- Lightman等人,2023年。让我们逐步验证
开发中
- CotHub标准提示库
- 待办事项
- 文献
- 详细结果
- 实验部分和长文本上下文
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案�,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能��高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐�工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号