




DN-DETR:通过引入查询去噪加速DETR训练
本仓库是DN-DETR的官方实现。该论文被CVPR 2022接收(得分112,口头报告)。代码现已开放。 [CVPR论文链接] [扩展版论文链接] [中文解读]
新闻
[2022/12]:我们在arxiv上发布了DN-DETR的扩展版,这是论文链接!我们将去噪训练应用于基于CNN的模型Faster R-CNN、分割模型Mask2Former以及其他类DETR模型如Anchor DETR和DETR,以提高这些模型的性能。
[2022/12]:Mask DINO的代码已开放!Mask DINO在COCO数据集上使用ResNet-50和SwinL骨干网络(无额外检测数据)分别达到了51.7和59.0的框AP,在相同设置下超越了DINO!
[2022/11]:基于DN-DETR的DINO实现已在本仓库中发布。感谢@Vallum!这个优化版本在ResNet-50下能在36轮训练中达到50.8 ~ 51.0 AP。
[2022/9]:我们发布了一个工�具箱detrex,提供了许多最先进的基于Transformer的检测算法。其中包括性能更好的DN-DETR。欢迎使用!
[2022/6]:我们发布了一个统一的检测和分割模型Mask DINO,在三个分割任务上都取得了最佳结果(COCO实例分割榜单上54.5 AP,COCO全景分割榜单上59.4 PQ,以及ADE20K语义分割榜单上60.8 mIoU)!代码将在这里开放。
[2022/5]:我们的代码已开放!使用ResNet-50在COCO上达到了更好的性能49.5AP。
[2022/3]:我们创建了一个仓库Awesome Detection Transformer,展示了关于用于检测和分割的transformer的论文。欢迎关注!
[2022/3]:DN-DETR被选为CVPR2022的口头报告。
[2022/3]:我们发布了另一项工作DINO:DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection,首次将DETR类模型确立为榜单上的SOTA模型。同样基于DN。代码将在这里开放。
简介
- 我们提出了一种新颖的去噪训练方法,以加速DETR训练,并对DETR类方法收敛缓慢问题提供了深入理解。
- DN仅是一种训练方法,可插入许多DETR类模型甚至传统模型中以提升性能。
- DN-DETR在使用ResNet-50骨干网络进行12和50轮训练时,分别达到了43.4和48.6的AP。与相同设置下的基线模型相比,DN-DETR仅用**50%**的训练轮数就达到了可比的性能。
- 我们优化后的模型取得了更好的性能。DN-Deformable-DETR使用ResNet-50骨干网络达到了49.5的AP。
模型
我们在DAB-DETR的基础上添加了去噪部分以加速训练收敛。这只增加了最少的计算量,并在推理时会被移除。
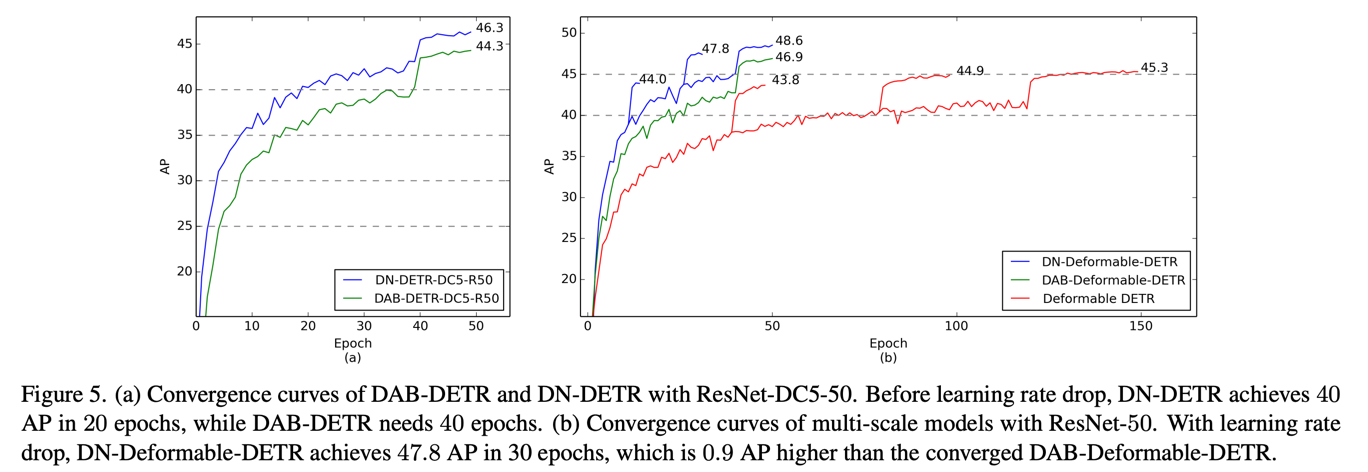
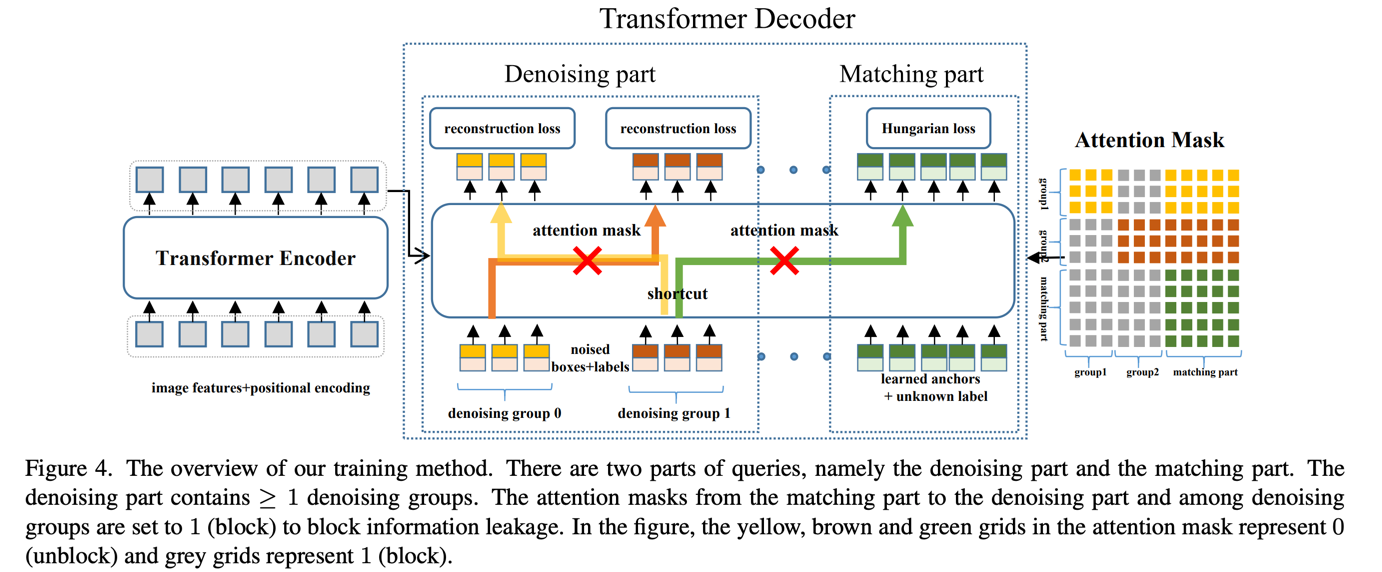 我们进行了广泛的实验来验证我们的去噪训练的有效性,例如收敛曲线比较。您可以参考我们的论文获取更多实验结果。
我们进行了广泛的实验来验证我们的去噪训练的有效性,例如收敛曲线比较。您可以参考我们的论文获取更多实验结果。
模型库
我们提供了DAB-DETR、DAB-Deformable-DETR(仅可变形编码器)和DAB-Deformable-DETR下的模型(参见DAB-DETR的代码和论文了解更多详情)。
您也可以参考我们的
[百度网盘模型库](提取码niet)。
50轮训练设置
<table> <thead> <tr style="text-align: right;"> <th></th> <th>名称</th> <th>骨干网络</th> <th>边界框AP</th> <th>日志/配置/检查点</th> <th>在<a href="https://arxiv.org/pdf/2203.01305.pdf">我们的论文</a>中的位置</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>DN-DETR-R50</td> <td>R50</td> <td>44.4<sup><a id="sup3c" herf="#sup1">1</a></sup></td> <td><a href="https://drive.google.com/drive/folders/1kuwScU8PhN61qQOl5bbiPhKAYbzDHsWs?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1TqvnjsbAjARZp1i8cB2w8A?pwd=niet">百度网盘</a> </td> <td>表1</td> </tr> <tr> <th>2</th> <td>DN-DETR-R50-DC5</td> <td>R50</td> <td>46.3</td> <td><a href="https://drive.google.com/drive/folders/1jr8BdDdMu8esABXdU3lNY7fpWVxAJtWa?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1lWrLUkxNfrncRTM-zmpbeA?pwd=niet">百度网盘</a> </td> <td>表1</td> </tr> <tr> <th>5</th> <td>DN-DAB-可变形-DETR<br>(仅可变形编码器)<sup><a id="sup3c" herf="#sup3">3</a></sup></td> <td>R50</td> <td>48.6</td> <td><a href="https://drive.google.com/drive/folders/1TLIuvMw6F9lBv77gWQ3Qcn5tdfG7kqdU?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1emOumSadTJbCcoqxhKnllQ?pwd=niet">百度网盘</a> </td> <td>表3</td> </tr> <tr> <th>6</th> <td>DN-DAB-可变形-DETR-R50-v2<sup><a id="sup4c" herf="#sup4">4</a></sup></td> <td>R50</td> <td>49.5(24轮训练为48.4)</td> <td><a href="https://drive.google.com/drive/folders/1pIllR0VfSIqX8TmQy0PFNiPdp87j-78j?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1ugoXlpr3x72qcXPKQ669sA?pwd=niet">百度网盘</a> </td> <td>优化实现,在编码器和解码器中都使用可变形注意力。更多详情请参见<a href="https://github.com/IDEA-opensource/DAB-DETR">DAB-DETR</a>。</td> </tr> </tbody> </table> ### 12轮训练设置 <table> <thead> <tr style="text-align: right;"> <th></th> <th>名称</th> <th>骨干网络</th> <th>边界框AP</th> <th>日志/配置/检查点</th> <th>在<a href="https://arxiv.org/pdf/2203.01305.pdf">我们的论文</a>中的位置</th> </tr> </thead> <tbody> <tr> <th>1</th> <td>DN-DAB-DETR-R50-DC5(3模式)<sup><a id="sup2c" herf="#sup1">2</a></sup></td> <td>R50</td> <td>41.7</td> <td><a href="https://drive.google.com/drive/folders/1jWSIWTWgoiIvyA7w2xIkdk-B1pS2atPA?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1fgCIGpMf0cgO6ToIb0xFuA?pwd=niet">百度网盘</a> </td> <td>表2</td> </tr> <tr> <th>4</th> <td>DN-DAB-DETR-R101-DC5(3模式)<sup><a id="sup2c" herf="#sup1">2</a></sup></td> <td>R101</td> <td>42.8</td> <td><a href="https://drive.google.com/drive/folders/1elPn06gs8mNxR3jtE53zi4cK5qLGH0AV?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1fgCIGpMf0cgO6ToIb0xFuA?pwd=niet">百度网盘</a> </td> <td>表2</td> </tr> <tr> <th>5</th> <td>DN-DAB-Deformable-DETR<br>(仅可变形编码器)<sup><a id="sup3c" herf="#sup3">3</a></sup></td> <td>R50</td> <td>43.4</td> <td><a href="https://drive.google.com/drive/folders/1T-qiHrvDF38PyqLhMU3QFC_n-ZkVgMJh?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1XygS_bjhe8Gg9tFhs9Z6uQ?pwd=niet">百度网盘</a> </td> <td>表2</td> </tr> <tr> <th>5</th> <td>DN-DAB-Deformable-DETR<br>(仅可变形编码器)<sup><a id="sup3c" herf="#sup3">3</a></sup></td> <td>R101</td> <td>44.1</td> <td><a href="https://drive.google.com/drive/folders/1V8CH7AMf9HGUYNNgEYaGK_2g2T2LNNWD?usp=sharing">谷歌云盘</a> / <a href="https://pan.baidu.com/s/1Q_C7FMXAlyPcWkIhbf5M6g?pwd=niet">百度网盘</a> </td> <td>表2</td> </tr> </tbody> </table>注意:
- <sup><a id="sup1" herf="#sup1c">1</a></sup>:由于我们优化了代码,结果相比论文中报告的有所提升(从
44.1到44.4)。我们没有重新运行其他模型,所以<font color=red>你可能会获得比我们论文中报告的更好的性能。</font> - <sup><a id="sup2" herf="#sup2c">2</a></sup>:标记为(3模式)的模型使用多种模式嵌入进行训练(更多详情请参考Anchor DETR或DAB-DETR)。
- <sup><a id="sup3" herf="#sup3c">3</a></sup>:此模型基于DAB-Deformable-DETR(仅可变形编码器),是DAB-DETR的多尺度版本。由于仅在编码器中使用可变形注意力,需要16个GPU进行训练。
- <sup><a id="sup4" herf="#sup4c">4</a></sup>:此模型基于DAB-Deformable-DETR,是一个优化的可变形DETR实现。更多详情请参见<a href="https://github.com/IDEA-opensource/DAB-DETR">DAB-DETR</a>。
<font color=red>我们鼓励你使用这个可变形版本</font>,因为它在编码器和解码器中都使用了可变形注意力,更加轻量级(即可以用4/8个A100 GPU训练)并且收敛更快(即在24轮内达到
48.4,与50轮的DAB-Deformable-DETR相当)。
使用方法
如何在你自己的模型中使用去噪训练
我们的代码大部分遵循DAB-DETR,并添加了用于去噪训练的额外组件,这些组件封装在dn_components.py文件中。主要包括3个函数:prepare_for_dn、dn_post_proces(前两个用于在检测前向函数中处理去噪部分)和compute_dn_loss(用于计算去噪损失)。你可以导入这些函数并将它们添加到你自己的检测模型中。 如果你想在自己的检测模型中使用它,你也可以比较DN-DETR和DAB-DETR,看看这些函数是如何添加的。
我们也鼓励你将其应用到其他类DETR模型甚至传统检测模型中,并在这个仓库中更新结果。
安装
我们使用DAB-DETR项目作为我们的代码基础,因此我们的DN-DETR不需要额外的依赖。对于DN-Deformable-DETR,你需要手动编译可变形注意力算子。
我们在python=3.7.3,pytorch=1.9.0,cuda=11.1环境下测试了我们的模型。其他版本可能也适用。
- 克隆此仓库
git clone https://github.com/IDEA-Research/DN-DETR.git cd DN-DETR
- 安装Pytorch和torchvision
按照https://pytorch.org/get-started/locally/的说明进行操作。
# 示例: conda install -c pytorch pytorch torchvision
- 安装其他所需包
pip install -r requirements.txt
- 编译CUDA算子
cd models/dn_dab_deformable_detr/ops python setup.py build install # 单元测试(应该看到所有检查都为True) python test.py cd ../../..
数据
请下载COCO 2017数据集并按以下方式组织:
COCODIR/
├── train2017/
├── val2017/
└── annotations/
├── instances_train2017.json
└── instances_val2017.json
运行
我们以标准的DN-DETR-R50和DN-Deformable-DETR-R50为例进行训练和评估。
评估我们预训练的模型
从此链接下载我们的DN-DETR-R50模型检查点,并执行以下命令。
你可以预期最终AP约为44.4。
对于我们的DN-DAB-Deformable-DETR_Deformable_Encoder_Only(在此下载)。预期的最终AP为48.6。
对于我们的DN-DAB-Deformable-DETR(在此下载),预期的最终AP为49.5。
# 对于dn_detr:44.1 AP;优化结果为44.4AP python main.py -m dn_dab_detr \ --output_dir logs/dn_DABDETR/R50 \ --batch_size 1 \ --coco_path /path/to/your/COCODIR \ # 替换为你的COCO路径 --resume /path/to/our/checkpoint \ # 替换为你的检查点路径 --use_dn \ --eval # 对于dn_deformable_detr:49.5 AP python main.py -m dn_deformable_detr \ --output_dir logs/dab_deformable_detr/R50 \ --batch_size 1 \ --coco_path /path/to/your/COCODIR \ # 替换为你的COCO路径 --resume /path/to/our/checkpoint \ # 替换为你的检查点路径 --transformer_activation relu \ --use_dn \ --eval # 对于dn_deformable_detr_deformable_encoder_only:48.6 AP python main.py -m dn_dab_deformable_detr_deformable_encoder_only --output_dir logs/dab_deformable_detr/R50 \ --batch_size 1 \ --coco_path /path/to/your/COCODIR \ # 替换为你的COCO路径 --resume /path/to/our/checkpoint \ # 替换为你的检查点路径 --transformer_activation relu \ --num_patterns 3 \ # 使用3个模式嵌入 --use_dn \ --eval
训练你自己的模型
同样,你也可以在单个进程上训练我们的模型:
# 对于dn_detr python main.py -m dn_dab_detr \ --output_dir logs/dn_DABDETR/R50 \ --batch_size 1 \ --epochs 50 \ --lr_drop 40 \ --coco_path /path/to/your/COCODIR # 替换为你的COCO路径 --use_dn
分布式运行
然而,由于训练耗时较长,我们建议在多设备上训练模型。
如果你计划在使用Slurm的集群上训练模型,这里是一个训练命令示例:
# 对于dn_detr:44.4 AP python run_with_submitit.py \ --timeout 3000 \ --job_name DNDETR \ --coco_path /path/to/your/COCODIR \ -m dn_dab_detr \ --job_dir logs/dn_DABDETR/R50_%j \ --batch_size 2 \ --ngpus 8 \ --nodes 1 \ --epochs 50 \ --lr_drop 40 \ --use_dn # 对于dn_dab_deformable_detr:49.5 AP python run_with_submitit.py \ --timeout 3000 \ --job_name dn_dab_deformable_detr \ --coco_path /path/to/your/COCODIR \ -m dab_deformable_detr \ --transformer_activation relu \ --job_dir logs/dn_dab_deformable_detr/R50_%j \ --batch_size 2 \ --ngpus 8 \ --nodes 1 \ --epochs 50 \ --lr_drop 40 \ --use_dn # 对于dn_dab_deformable_detr_deformable_encoder_only:48.6 AP python run_with_submitit.py \ --timeout 3000 \ --job_name dn_dab_deformable_detr_deformable_encoder_only \ --coco_path /path/to/your/COCODIR \ -m dn_dab_deformable_detr_deformable_encoder_only \ --transformer_activation relu \ --job_dir logs/dn_dab_deformable_detr/R50_%j \ --num_patterns 3 \ --batch_size 1 \ --ngpus 8 \ --nodes 2 \ --epochs 50 \ --lr_drop 40 \ --use_dn
如果你想训练我们的DC版本或多模式版本,添加
--dilation # 对于DC版本 --num_patterns 3 # 对于3个模式
但是,这需要额外的训练资源和内存,即使用16个GPU。
最终的AP应该与我们的相似或更好,因为我们优化后的结果比论文中报告的性能更好(例如,我们报告DN-DETR为44.1,但我们的新结果可以达到44.4。
如果你得到更好的结果,不要感到惊讶!)。
我们的训练设置与DAB-DETR相同,但添加了一个参数--use_dn,你也可以参考DAB-DETR。
注意:
- 结果对批量大小敏感。我们默认使用16(每个GPU 2张图像 x 8个GPU)。
或者在单个节点上使用多进程运行:
# 对于dn_dab_detr:44.4 AP python -m torch.distributed.launch --nproc_per_node=8 \ main.py -m dn_dab_detr \ --output_dir logs/dn_DABDETR/R50 \ --batch_size 2 \ --epochs 50 \ --lr_drop 40 \ --coco_path /path/to/your/COCODIR \ --use_dn # 对于dn_deformable_detr: 49.5 AP python -m torch.distributed.launch --nproc_per_node=8 \ main.py -m dn_dab_deformable_detr \ --output_dir logs/dn_dab_deformable_detr/R50 \ --batch_size 2 \ --epochs 50 \ --lr_drop 40 \ --transformer_activation relu \ --coco_path /path/to/your/COCODIR \ --use_dn
相关链接
我们的工作基于DAB-DETR。我们还发布了另一个基于DN-DETR和DAB-DETR的SOAT检测模型DINO。
-
DINO: 使用改进的去噪锚框的端到端目标检测DETR。 Hao Zhang*, Feng Li*, Shilong Liu*, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, Heung-Yeung Shum。 arxiv 2022。 [论文] [代码]。
-
DAB-DETR: 动态锚框是DETR更好的查询。 Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, Lei Zhang。 国际学习表示会议(ICLR)2022。 [论文] [代码]。
许可证
DN-DETR在Apache 2.0许可下发布。更多信息请参见LICENSE文件。
版权所有 (c) IDEA。保留所有权利。
根据Apache许可证2.0版("许可证")获得许可;除非符合许可证,否则您不得使用这些文件。您可以在http://www.apache.org/licenses/LICENSE-2.0 获取许可证副本。
除非适用法律要求或书面同意,根据许可证分发的软件是基于"按原样"分发的,不附带任何明示或暗示的担保或条件。请参阅许可证以了解许可证下的特定语言和限制。
引用
如果您发现我们的工作对您的研究有帮助,请考虑引用以下BibTeX条目。
@inproceedings{li2022dn,
title={Dn-detr: 通过引入查询去噪加速detr训练},
author={Li, Feng and Zhang, Hao and Liu, Shilong and Guo, Jian and Ni, Lionel M and Zhang, Lei},
booktitle={计算机视觉与模式识别IEEE/CVF会议论文集},
pages={13619--13627},
year={2022}
}
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI�集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号