



Mask DINO <img src="https://yellow-cdn.veclightyear.com/835a84d5/ae060e56-089a-4f67-8829-ab70505422b5.png" width="30">
![]()
![]()
![]()
![]()
![]()
本仓库是Mask DINO: 面向统一的基于Transformer的目标检测和分割框架(DINO发音为`daɪnoʊ',如恐龙)的官方实现。我们的代码基于detectron2。detrex版本同步开源。
:fire: 我们发布了一个强大的开放集目标检测和分割模型OpenSeeD,它基于MaskDINO,在开放集目标分割任务上取得了最佳结果。代码和检查点可在此处获取。
<details open> <summary> <font size=8><strong>新闻</strong></font> </summary>[2023/7] 我们发布了Semantic-SAM,这是一个通用图像分割模型,可以以任何所需的粒度对任何内容进行分割和识别。代码和检查点已可用!
[2023/2] Mask DINO已被CVPR 2023接收!
[2022/9] 我们发布了一个工具箱detrex,提供最先进的基于Transformer的检测算法。它包括性能更好的DINO,Mask DINO也将以detrex实现发布。欢迎使用!</br>
[2022/3]我们建立了一个仓库Awesome Detection Transformer,展示了关于用于检测和分割的transformer的论文。欢迎关注!
</details>特点
- 用于目标检测、全景分割、实例分割和语义分割的统一架构。
- 实现检测和分割之间的任务和数据协作。
- 在相同设置下达到最先进的性能。
- 支持主要的检测和分割数据集:COCO、ADE20K、Cityscapes。
代码更新
-
[2022/12/02] 我们的代码和检查点已可用!在相同设置下,Mask DINO在COCO上进一步实现了ResNet-50和SwinL分别达到<strong>51.7</strong>和<strong>59.0</strong>的边界框AP,优于DINO!
-
[2022/6] 我们提出了一个统一的检测和分割模型Mask DINO,在三个分割任务上都取得了最佳结果(COCO实例分割排行榜上54.7 AP,COCO全景分割排行榜上59.5 PQ,ADE20K语义分割排行榜上60.8 mIoU)!
-
发布代码和检查点
-
发布从DINO到MaskDINO的模型转换检查点器
-
发布基于submitit的GPU集群提交脚本,用于多节点训练
-
发布大型模型的EMA训练
-
发布更多大型模型
安装
参见安装说明。
入门指南
参见结果。
参见入门指南。
参见更多用法。
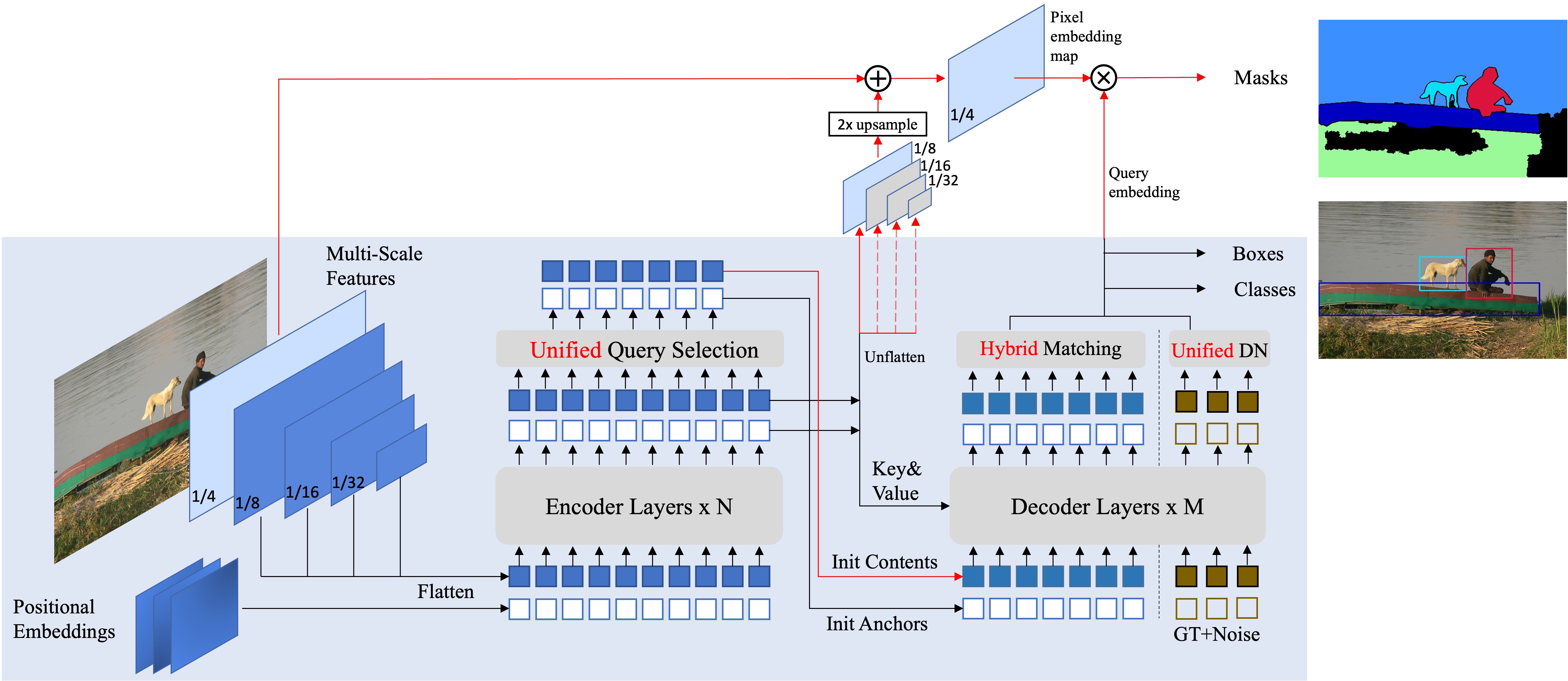
结果
在这部分中,我们展示了不使用额外检测数据或技巧的干净模型。
COCO实例分割和目标检测
我们遵循DINO,默认在编码器的前馈网络中使用隐藏维度2048。我们还在实例分割和检测中使用了论文中提出的增强掩码框初始化。为了更好地展示我们的模型,我们还在此表中列出了使用隐藏维度1024(hid 1024)和不使用增强掩码初始化(no mask enhance)的模型。
COCO全景分割
<table><tbody> <!-- 表格开始 --> <!-- 表头 --> <th valign="bottom">名称</th> <th valign="bottom">骨干网络</th> <th valign="bottom">训练轮数</th> <th valign="bottom">PQ</th> <th valign="bottom">掩码AP</th> <th valign="bottom">边界框AP</th> <th valign="bottom">mIoU</th> <th valign="bottom">下载</th> <tr><td align="left">MaskDINO | <a href="configs/coco/panoptic-segmentation/maskdino_R50_bs16_50ep_3s_dowsample1_2048.yaml">配置</a></td> <td align="center">R50</td> <td align="center">50</td> <td align="center">53.0</td> <td align="center">48.8</td> <td align="center">44.3</td> <td align="center">60.6</td> <td align="center"><a href="https://github.com/IDEA-Research/detrex-storage/releases/download/maskdino-v0.1.0/maskdino_r50_50ep_300q_hid2048_3sd1_panoptic_pq53.0.pth">模型</a></td> <tr><td align="left">MaskDINO | <a href="configs/coco/panoptic-segmentation/swin/maskdino_R50_bs16_50ep_4s_dowsample1_2048.yaml">配置</a></td> <td align="center">Swin-L (IN21k)</td> <td align="center">50</td> <td align="center">58.3</td> <td align="center">50.6</td> <td align="center">56.2</td> <td align="center">67.5</td> <td align="center"><a href="https://github.com/IDEA-Research/detrex-storage/releases/download/maskdino-v0.1.0/maskdino_swinl_50ep_300q_hid2048_3sd1_panoptic_58.3pq.pth">模型</a></td> </tr> <tr><td align="left">MaskDINO+O365数据+1.2倍大图像</td> <td align="center">Swin-L (IN21k)</td> <td align="center">20</td> <td align="center">59.4</td> <td align="center">53.0</td> <td align="center">57.7</td> <td align="center">67.3</td> <td align="center">即将发布</td> </tr> </tbody></table>语义分割
我们使用隐藏维度1024和100个查询进行语义分割。
您还可以在这里找到所有这些模型。
所有模型都是使用4个NVIDIA A100 GPU(基于ResNet-50的模型)或8个NVIDIA A100 GPU(基于Swin-L的模型)进行训练的。
我们将在未来发布更多预训练模型。
入门指南
在上面的表格中,"名称"列包含指向配置文件的链接config_path,相应的模型检查点可以从model中的链接下载。
如果您的数据集文件不在此仓库下,您需要先添加export DETECTRON2_DATASETS=/path/to/your/data或使用符号链接ln -s将数据集链接到此仓库中,然后再执行以下命令。
评估我们的预训练模型
- 您可以下载我们的预训练模型并使用以下命令评估它们。
例如,要复现我们的实例分割结果,您可以从表格中复制配置路径,将预训练检查点下载到python train_net.py --eval-only --num-gpus 8 --config-file config_path MODEL.WEIGHTS /path/to/checkpoint_file/path/to/checkpoint_file,然后运行
这将复现模型的结果。python train_net.py --eval-only --num-gpus 8 --config-file configs/coco/instance-segmentation/maskdino_R50_bs16_50ep_3s_dowsample1_2048.yaml MODEL.WEIGHTS /path/to/checkpoint_file
训练MaskDINO以复现结果
- 使用上述命令而不带
eval-only将训练模型。对于Swin骨干网络,您需要使用MODEL.WEIGHTS /path/to/pretrained_checkpoint指定预训练骨干网络的路径python train_net.py --num-gpus 8 --config-file config_path MODEL.WEIGHTS /path/to/checkpoint_file - 对于ResNet-50模型,在8个GPU上训练需要每个GPU约
15G内存,50个训练轮需要3天时间。 - 对于Swin-L模型,在8个GPU上训练需要每个GPU
60G内存。如果您的GPU内存不足,您也可以在两个节点上使用16个GPU进行分布式训练。 - 我们对所有模型使用总批量大小16。如果在1个GPU上训练,您需要自己确定学习率和批量大小
python train_net.py --num-gpus 1 --config-file config_path SOLVER.IMS_PER_BATCH SET_TO_SOME_REASONABLE_VALUE SOLVER.BASE_LR SET_TO_SOME_REASONABLE_VALUE
您也可以参考Detectron2入门指南获取完整用法。
更多用法
掩码增强的边界框初始化
我们提供两种方法将预测的掩码转换为框来初始化解码器框。您可以按如下设置:
MODEL.MaskDINO.INITIALIZE_BOX_TYPE: no不使用掩码增强的框初始化MODEL.MaskDINO.INITIALIZE_BOX_TYPE: mask2box一种快速转换方式MODEL.MaskDINO.INITIALIZE_BOX_TYPE: bitmask由detectron2提供的转换方法,速度较慢但转换更准确
这两种转换方式对最终性能影响不大,您可以选择任意一种。
此外,如果您已经在没有掩码增强框初始化的情况下训练了一个模型50个epoch,您可以插入这种方法,并简单地在最后几个epoch中微调模型(即从训练32K迭代的模型加载并进行微调)。这种方式也可以达到与从头开始训练相似的性能,但更加灵活。
模型组件
MaskDINO由三个组件组成:主干网络、像素解码器和Transformer解码器。 您可以轻松地用自己的实现替换这三个组件中的任何一个。
-
主干网络:在
maskdino/modeling/backbone下定义并注册您的主干网络��。您可以参考Swin Transformer作为示例。 -
像素解码器:像素解码器实际上是DINO和Deformable DETR中的多尺度编码器,我们遵循mask2former称之为像素解码器。它位于
maskdino/modeling/pixel_decoder中,您可以更改您的多尺度编码器。返回的值包括:mask_features是分辨率为原始图像1/4的每像素嵌入,通过融合主干网络1/4特征和多尺度编码器编码的1/8特征获得。这用于生成二元掩码。multi_scale_features,是Transformer解码器的多尺度输入。 对于具有4个尺度的ResNet-50模型,我们使用1/32、1/16和1/8分辨率,但您可以在这里使用任意分辨率,并按照DINO的做法将1/32进一步下采样以获得第4个尺度的1/64分辨率。对于使用SwinL的5尺度模型,我们额外使用1/4分辨率特征,就像DINO中那样。
-
transformer解码器:它主要遵循DINO解码器进行检测和分割任务。它定义在
maskdino/modeling/transformer_decoder中。
许可证
Mask DINO以Apache 2.0许可证发布。请查看LICENSE文件以获取更多信息。
版权所有 (c) IDEA。保留所有权利。
根据Apache许可证2.0版("许可证")授权;除非遵守许可证,否则不得使用这些文件。您可以在http://www.apache.org/licenses/LICENSE-2.0 获取许可证副本。
除非适用法律要求或书面同意,根据许可证分发的软件是基于"按原样"分发的,不附带任何明示或暗示的担保或条件。请参阅许可证以了解特定语言下的权限和限制。
<a name="CitingMaskDINO"></a>引用Mask DINO
如果您发现我们的工作对您的研究有帮助,请考虑引用以下BibTeX条目。
@misc{li2022mask, title={Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation}, author={Feng Li and Hao Zhang and Huaizhe xu and Shilong Liu and Lei Zhang and Lionel M. Ni and Heung-Yeung Shum}, year={2022}, eprint={2206.02777}, archivePrefix={arXiv}, primaryClass={cs.CV} }
如果您发现代码有用,也请考虑以下BibTeX条目。
@misc{zhang2022dino, title={DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection}, author={Hao Zhang and Feng Li and Shilong Liu and Lei Zhang and Hang Su and Jun Zhu and Lionel M. Ni and Heung-Yeung Shum}, year={2022}, eprint={2203.03605}, archivePrefix={arXiv}, primaryClass={cs.CV} } @inproceedings{li2022dn, title={Dn-detr: Accelerate detr training by introducing query denoising}, author={Li, Feng and Zhang, Hao and Liu, Shilong and Guo, Jian and Ni, Lionel M and Zhang, Lei}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={13619--13627}, year={2022} } @inproceedings{ liu2022dabdetr, title={{DAB}-{DETR}: Dynamic Anchor Boxes are Better Queries for {DETR}}, author={Shilong Liu and Feng Li and Hao Zhang and Xiao Yang and Xianbiao Qi and Hang Su and Jun Zhu and Lei Zhang}, booktitle={International Conference on Learning Representations}, year={2022}, url={https://openreview.net/forum?id=oMI9PjOb9Jl} }
致谢
非常感谢这些优秀的开源项目
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、��图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号