
InternLM-Math
开源双语数学推理大模型
InternLM-Math是一个开源的双语数学推理大模型,在形式化和非形式化数学推理方面表现优异。它集成了数学问题求解、证明、验证和增强等功能。该模型在MiniF2F、MATH和GSM8K等基准测试中展现出领先性能,并支持使用Lean语言进行可验证的数学推理。InternLM-Math还可作为奖励模型和数学问题增强助手,为数学研究和应用提供有力支持。




InternLM-Math
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/b24bd4bb-d828-4ee5-979c-73dd7a8450c3.svg" width="200"/> <div> </div> <div align="center"> <b><font size="5">InternLM-Math</font></b> <sup> <a href="https://internlm.intern-ai.org.cn/"> <i><font size="4">热门</font></i> </a> </sup> <div> </div> </div>
最先进的双语开源数学推理大语言模型。 一个解题器,证明器,验证器,增强器。
📑 论文 💻 Github 🤗 演示 🤗 检查点  <img src="https://yellow-cdn.veclightyear.com/835a84d5/433c7be9-f3d9-435e-b1aa-1b67c5a5202b.png" width="20px" /> ModelScope
<img src="https://yellow-cdn.veclightyear.com/835a84d5/433c7be9-f3d9-435e-b1aa-1b67c5a5202b.png" width="20px" /> ModelScope
新闻
- [2024.07.25] 我们发布了Lean-Github和InternLM2-Step-Prover,包含从100多个Lean 4仓库编译的29K个定理,以及在Lean-Github和Lean-Workbook上微调的7B模型,在MiniF2F-test (54.5%)、ProofNet (18.1%)和Putnam (5个问题)上取得了最先进的性能。🤗数据集 🤗模型 📑 论文 📖 README
- [2024.06.06] 我们发布了Lean-Workbook,包含57K个用Lean 4形式化的数学问题,其中5K个带有搜索证明,用于自动形式化和自动定理证明。🤗数据集 📑 论文
- [2024.05.24] 我们发布了更新版本InternLM2-Math-Plus,有4种规模,包括1.8B、7B、20B和8x22B,在非形式化数学推理性能(思维链和代码解释器)和形式化数学推理性能(LEAN 4翻译和LEAN 4定理证明)方面都取得了显著提升。
- [2024.02.10] 我们添加了技术报告和引用参考。
- [2024.01.31] 我们添加了MiniF2F结果和评估代码!
- [2024.01.29] 我们添加了来自ModelScope的检查点。更新了关于多数投票和代码解释器的结果。技术报告即将发布!
- [2024.01.26] 我们添加了来自OpenXLab的检查点,方便中国用户下载!
InternLM2-Math-Plus
检查点
| 模型 | 模型类型 | Transformers(HF) | ModelScope | 发布日期 |
|---|---|---|---|---|
| InternLM2-Math-Plus-1.8B | 对话 | 🤗internlm/internlm2-math-plus-1_8b | Shanghai_AI_Laboratory/internlm2-math-plus-1_8b | 2024-05-27 |
| InternLM2-Math-Plus-7B | 对话 | 🤗internlm/internlm2-math-plus-7b | Shanghai_AI_Laboratory/internlm2-math-plus-7b | 2024-05-27 |
| InternLM2-Math-Plus-20B | 对话 | 🤗internlm/internlm2-math-plus-20b | Shanghai_AI_Laboratory/internlm2-math-plus-20b | 2024-05-27 |
| InternLM2-Math-Plus-Mixtral8x22B | 对话 | 🤗internlm/internlm2-math-plus-mixtral8x22b | Shanghai_AI_Laboratory/internlm2-math-plus-mixtral8x22b | 2024-05-27 |
形式化数学推理
我们在形式化数学推理基准MiniF2F-test上评估了InternLM2-Math-Plus的性能。评估设置与Llemma在LEAN 4上相同。
如何复现我们在MiniF2F上的性能。
| 模型 | MiniF2F-test |
|---|---|
| ReProver | 26.5 |
| LLMStep | 27.9 |
| GPT-F | 36.6 |
| HTPS | 41.0 |
| Llemma-7B | 26.2 |
| Llemma-34B | 25.8 |
| InternLM2-Math-7B-Base | 30.3 |
| InternLM2-Math-20B-Base | 29.5 |
| InternLM2-Math-Plus-1.8B | 38.9 |
| InternLM2-Math-Plus-7B | 43.4 |
| InternLM2-Math-Plus-20B | 42.6 |
| InternLM2-Math-Plus-Mixtral8x22B | 37.3 |
非形式化数学推理
我们在非形式化数学推理基准MATH和GSM8K上评估了InternLM2-Math-Plus的性能。在最小规模设置下,InternLM2-Math-Plus-1.8B优于MiniCPM-2B。InternLM2-Math-Plus-7B优于Deepseek-Math-7B-RL,后者是当前最先进的开源数学推理模型。InternLM2-Math-Plus-Mixtral8x22B在MATH(使用Python)上达到68.5分,在GSM8K上达到91.8分。
关于工具调用推理和评估,请参见agent部分。 | 模型 | MATH | MATH-Python | GSM8K | | -------------------------------- | -------- | ----------- | -------- | | MiniCPM-2B | 10.2 | - | 53.8 | | InternLM2-Math-Plus-1.8B | 37.0 | 41.5 | 58.8 | | InternLM2-Math-7B | 34.6 | 50.9 | 78.1 | | Deepseek-Math-7B-RL | 51.7 | 58.8 | 88.2 | | InternLM2-Math-Plus-7B | 53.0 | 59.7 | 85.8 | | InternLM2-Math-20B | 37.7 | 54.3 | 82.6 | | InternLM2-Math-Plus-20B | 53.8 | 61.8 | 87.7 | | Mixtral8x22B-Instruct-v0.1 | 41.8 | - | 78.6 | | Eurux-8x22B-NCA | 49.0 | - | - | | InternLM2-Math-Plus-Mixtral8x22B | 58.1 | 68.5 | 91.8 |
我们还在MathBench-A上评估了模型。InternLM2-Math-Plus-Mixtral8x22B的表现与Claude 3 Opus相当。
| 模型 | 算术 | 小学 | 初中 | 高中 | 大学 | 平均 |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 77.7 | 87.7 | 76.3 | 59.0 | 54.0 | 70.9 |
| Claude 3 Opus | 85.7 | 85.0 | 58.0 | 42.7 | 43.7 | 63.0 |
| Qwen-Max-0428 | 72.3 | 86.3 | 65.0 | 45.0 | 27.3 | 59.2 |
| Qwen-1.5-110B | 70.3 | 82.3 | 64.0 | 47.3 | 28.0 | 58.4 |
| Deepseek-V2 | 82.7 | 89.3 | 59.0 | 39.3 | 29.3 | 59.9 |
| Llama-3-70B-Instruct | 70.3 | 86.0 | 53.0 | 38.7 | 34.7 | 56.5 |
| InternLM2-Math-Plus-Mixtral8x22B | 77.5 | 82.0 | 63.6 | 50.3 | 36.8 | 62.0 |
| InternLM2-Math-20B | 58.7 | 70.0 | 43.7 | 24.7 | 12.7 | 42.0 |
| InternLM2-Math-Plus-20B | 65.8 | 79.7 | 59.5 | 47.6 | 24.8 | 55.5 |
| Llama3-8B-Instruct | 54.7 | 71.0 | 25.0 | 19.0 | 14.0 | 36.7 |
| InternLM2-Math-7B | 53.7 | 67.0 | 41.3 | 18.3 | 8.0 | 37.7 |
| Deepseek-Math-7B-RL | 68.0 | 83.3 | 44.3 | 33.0 | 23.0 | 50.3 |
| InternLM2-Math-Plus-7B | 61.4 | 78.3 | 52.5 | 40.5 | 21.7 | 50.9 |
| MiniCPM-2B | 49.3 | 51.7 | 18.0 | 8.7 | 3.7 | 26.3 |
| InternLM2-Math-Plus-1.8B | 43.0 | 43.3 | 25.4 | 18.9 | 4.7 | 27.1 |
简介 (InternLM2-Math)
- 性能优于ChatGPT的7B和20B中英文数学语言模型。 InternLM2-Math是在InternLM2-Base的基础上,通过约1000亿高质量数学相关token的持续预训练和约200万双语数学监督数据的SFT而得到的。我们应用了最小哈希和精确数字匹配来消除可能的测试集泄露。
- 添加Lean作为支持语言,用于数学问题求解和数学定理证明。 我们正在探索将Lean 3与InternLM-Math结合,以实现可验证的数学推理。InternLM-Math可以为简单的数学推理任务(如GSM8K)生成Lean代码,或根据Lean状态提供可能的证明策略。
- 也可以视为奖励模型,支持结果/过程/Lean奖励模型。 我们使用各种类型的奖励建模数据来监督InternLM2-Math,使其能够验证思维链过程。我们还添加了将思维链过程转换为Lean 3代码的能力。
- 数学语言模型增强助手和代码解释器。InternLM2-Math可以帮助增强数学推理问题并使用代码解释器解决它们,使您能够更快地生成合成数据!
模型
InternLM2-Math-Base-7B和InternLM2-Math-Base-20B是预训练检查点。InternLM2-Math-7B和InternLM2-Math-20B是SFT检查点。
| 模型 | 模型类型 | Transformers(HF) | OpenXLab | ModelScope | 发布日期 |
|---|---|---|---|---|---|
| InternLM2-Math-Base-7B | 基础 | 🤗internlm/internlm2-math-base-7b | | <img src="https://yellow-cdn.veclightyear.com/835a84d5/433c7be9-f3d9-435e-b1aa-1b67c5a5202b.png" width="20px" /> internlm2-math-base-7b | 2024-01-23 |
| InternLM2-Math-Base-20B | 基础 | 🤗internlm/internlm2-math-base-20b | | <img src="https://yellow-cdn.veclightyear.com/835a84d5/433c7be9-f3d9-435e-b1aa-1b67c5a5202b.png" width="20px" /> internlm2-math-base-20b | 2024-01-23 |
| InternLM2-Math-7B | 对话 | 🤗internlm/internlm2-math-7b | | <img src="https://yellow-cdn.veclightyear.com/835a84d5/433c7be9-f3d9-435e-b1aa-1b67c5a5202b.png" width="20px" /> internlm2-math-7b | 2024-01-23 |
| InternLM2-Math-20B | 对话 | 🤗internlm/internlm2-math-20b | | <img src="https://yellow-cdn.veclightyear.com/835a84d5/433c7be9-f3d9-435e-b1aa-1b67c5a5202b.png" width="20px" /> internlm2-math-20b | 2024-01-23 |
性能
预训练性能
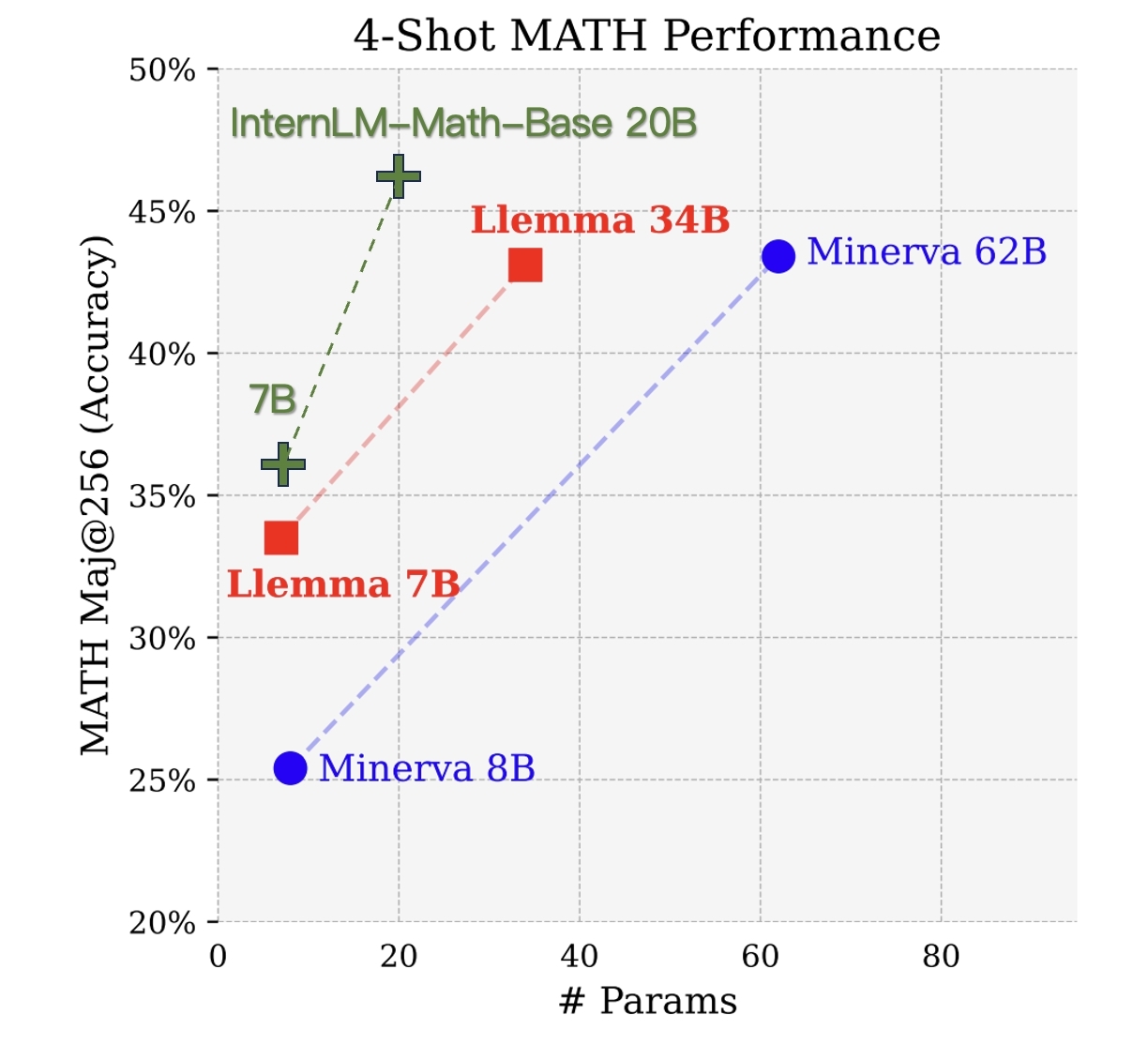
我们基于贪婪解码和少样本COT评估预训练检查点。预训练的详细信息将在技术报告中介绍。
| 基准 | GSM8K MAJ@1 | GSM8K MAJ@100 | MATH MAJ@1 | MATH MAJ@256 |
|---|---|---|---|---|
| Llama2-7B | 14.6 | - | 2.5 | - |
| Llemma-7B | 36.4 | 54.0 | 18.0 | 33.5 |
| InternLM2-Base-7B | 36.5 | - | 8.6 | - |
| InternLM2-Math-Base-7B | 49.2 | 75.7 | 21.5 | 35.6 |
| Minerva-8B | 16.2 | 28.4 | 14.1 | 25.4 |
| InternLM2-Base-20B | 54.6 | - | 13.7 | - |
| InternLM2-Math-Base-20B | 63.7 | 84.8 | 27.3 | 46.2 |
| Llemma-34B | 51.5 | 69.3 | 25.0 | 43.1 |
| Minerva-62B | 52.4 | 68.5 | 27.6 | 43.4 |
| Minerva-540B | 58.8 | 78.5 | 33.6 | 50.3 |
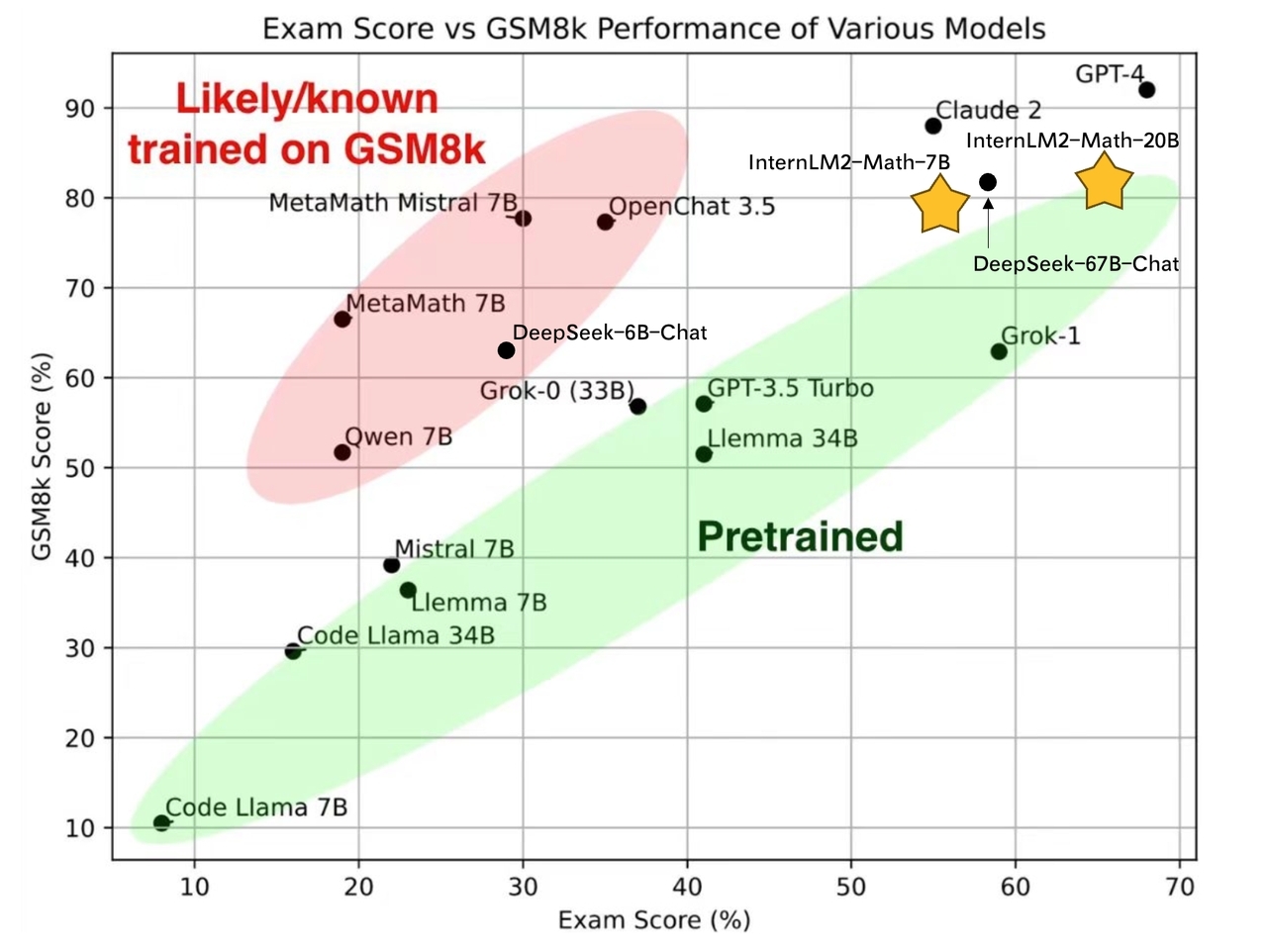
我们使用少样本方法在MiniF2F上评估预训练检查点。请参阅eval/pretrain/minif2f进行评估。
| 基准 | MiniF2F-test |
|---|---|
| ReProver | 26.5 |
| LLMStep | 27.9 |
| Code-Llama-7B | 26.2 |
| Code-Llama-34B | 25.8 |
| Llemma-7B | 26.2 |
| Llemma-34B | 25.8 |
| InternLM2-Math-7B-Base | 30.3 |
| InternLM2-Math-20B-Base | 29.5 |
SFT 性能
所有性能基于贪婪解码和思维链。我们注意到匈牙利问题的性能在不同检查点之间�差异较大,而其他性能则非常稳定。这可能是由于匈牙利问题的数量问题。
| 模型 | 模型类型 | GSM8K | MATH | 匈牙利 |
|---|---|---|---|---|
| Qwen-7B-Chat | 通用 | 51.7 | 11.6 | - |
| DeepSeek-7B-Chat | 通用 | 63.0 | 15.8 | 28.5 |
| InternLM2-Chat-7B | 通用 | 70.7 | 23.0 | - |
| ChatGLM3-6B | 通用 | 53.8 | 20.4 | 32 |
| MetaMath-Mistral-7B | 数学 | 77.7 | 28.2 | 29 |
| MetaMath-Llemma-7B | 数学 | 69.2 | 30.0 | - |
| InternLM2-Math-7B | 数学 | 78.1 | 34.6 | 55 |
| InternLM2-Chat-20B | 通用 | 79.6 | 31.9 | - |
| MetaMath-Llemma-34B | 数学 | 75.8 | 34.8 | - |
| InternLM2-Math-20B | 数学 | 82.6 | 37.7 | 66 |
| Qwen-72B | 通用 | 78.9 | 35.2 | 52 |
| DeepSeek-67B | 通用 | 84.1 | 32.6 | 58 |
| ChatGPT (GPT-3.5) | 通用 | 80.8 | 34.1 | 41 |
| GPT4 (首个版本) | 通用 | 92.0 | 42.5 | 68 |
代码解释器性能
所有性能基于与Python的交互。
| 模型 | GSM8K | MATH |
|---|---|---|
| DeepSeek-Coder-Instruct-7B | 62.8 | 28.6 |
| DeepSeek-Coder-Instruct-1.5-7B | 72.6 | 34.1 |
| ToRA-7B | 72.6 | 44.6 |
| MathCODER-CL-7B | 67.8 | 30.2 |
| InternLM2-Chat-7B | 77.9 | 45.1 |
| InternLM2-Math-7B | 79.4 | 50.9 |
| ToRA-13B | 75.8 | 48.1 |
| MathCODER-CL-13B | 74.1 | 35.9 |
| InternLM2-Chat-20B | 84.5 | 51.2 |
| InternLM2-Math-20B | 80.7 | 54.3 |
| MathCODER-CL-34B | 81.7 | 45.2 |
| ToRA-70B | 84.3 | 49.7 |
| GPT-4 代码解释器 * | 97.0 | 69.7 |
评估
你可以使用OpenCompass轻松地在各种数学数据集(如Math和GSM8K)上评估InternLM2-Math,只需一条命令即可。安装OpenCompass后,只需在终端中执行以下命令即可开始:
python run.py --models hf_internlm2_chat_math_7b --datasets gsm8k_gen math_gen_736506
或者,为了更简化的体验,你可以使用预定义的配置文件。运行以下命令,确保根据你的需求调整参数:
python run.py config/eval_internlm_math_chat.py
推理
LMDeploy
我们建议使用LMDeploy(>=0.2.1)进行推理。
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig backend_config = TurbomindEngineConfig(model_name='internlm2-chat-7b', tp=1, cache_max_entry_count=0.3) chat_template = ChatTemplateConfig(model_name='internlm2-chat-7b', system='', eosys='', meta_instruction='') pipe = pipeline(model_path='internlm/internlm2-math-7b', chat_template_config=chat_template, backend_config=backend_config) problem = '1+1=' result = pipe([problem], request_output_len=1024, top_k=1)
Huggingface
import torch from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2-math-7b", trust_remote_code=True) # 设置`torch_dtype=torch.float16`以float16格式加载模型,否则将以float32格式加载,可能导致内存溢出错误。 model = AutoModelForCausalLM.from_pretrained("internlm/internlm2-math-7b", trust_remote_code=True, torch_dtype=torch.float16).cuda() model = model.eval() response, history = model.chat(tokenizer, "1+1=", history=[], meta_instruction="") print(response)
特殊用法
我们列出了一些在SFT中使用的指令。你可以使用它们来帮助你。你可以用其他方式提示模型,但以下是推荐的。InternLM2-Math可能会结合以下能力,但不能保证。
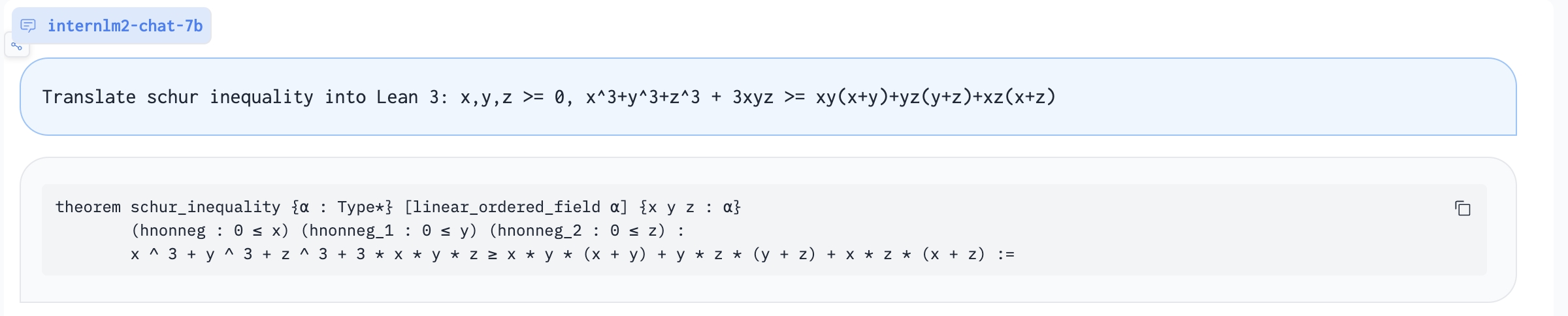
将证明问题翻译成Lean:
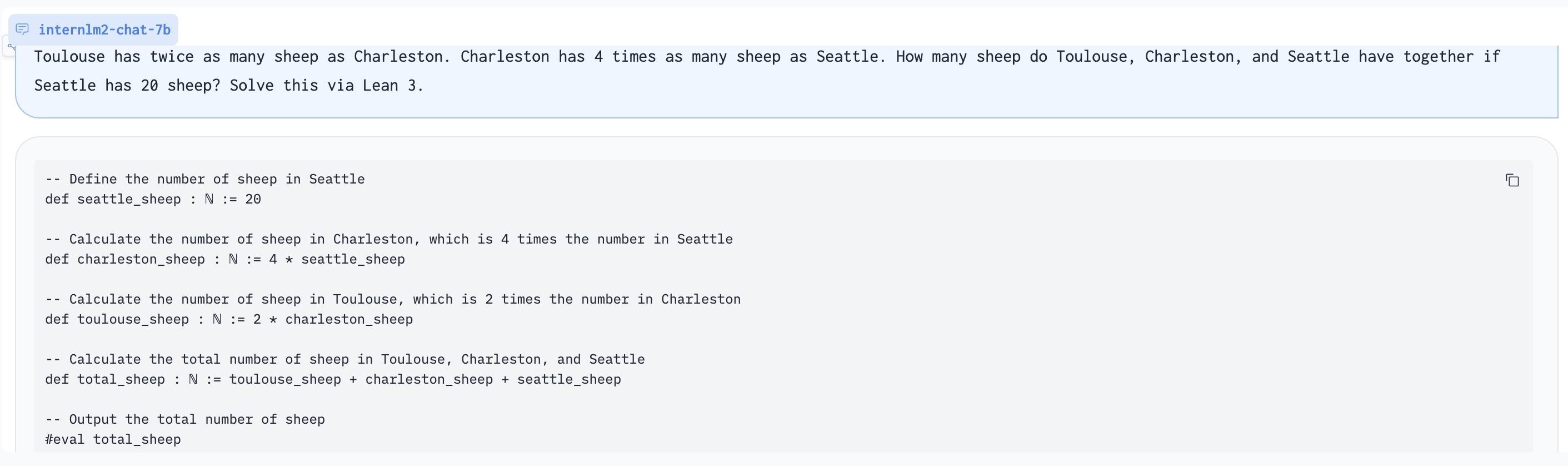
使用Lean 3解决GSM8K问题:
基于Lean 3代码生成问题:
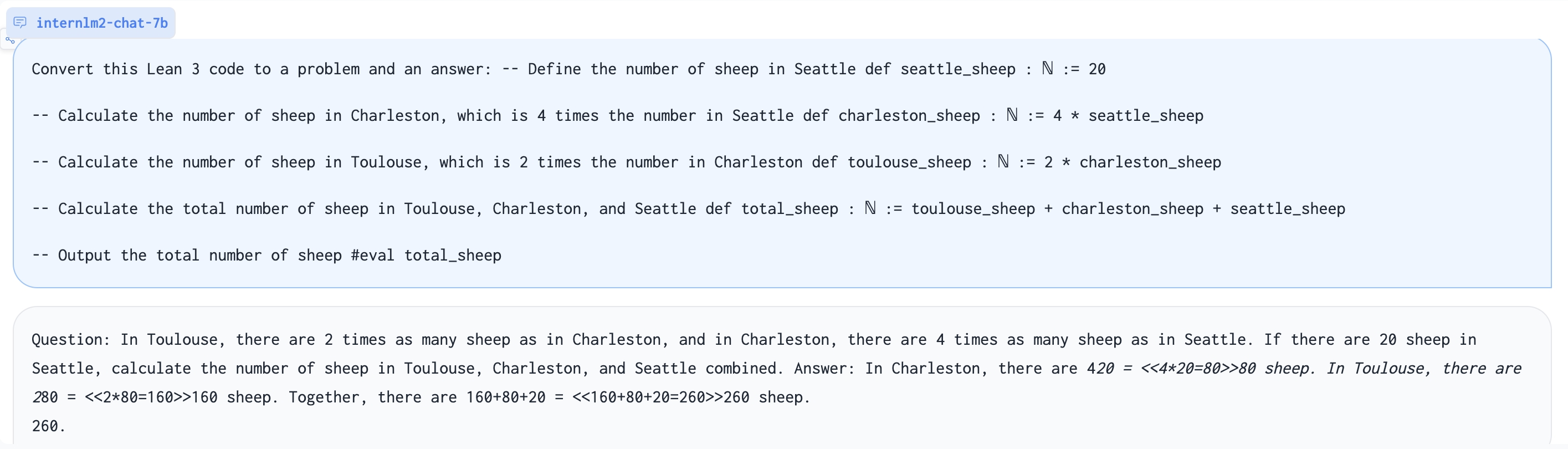
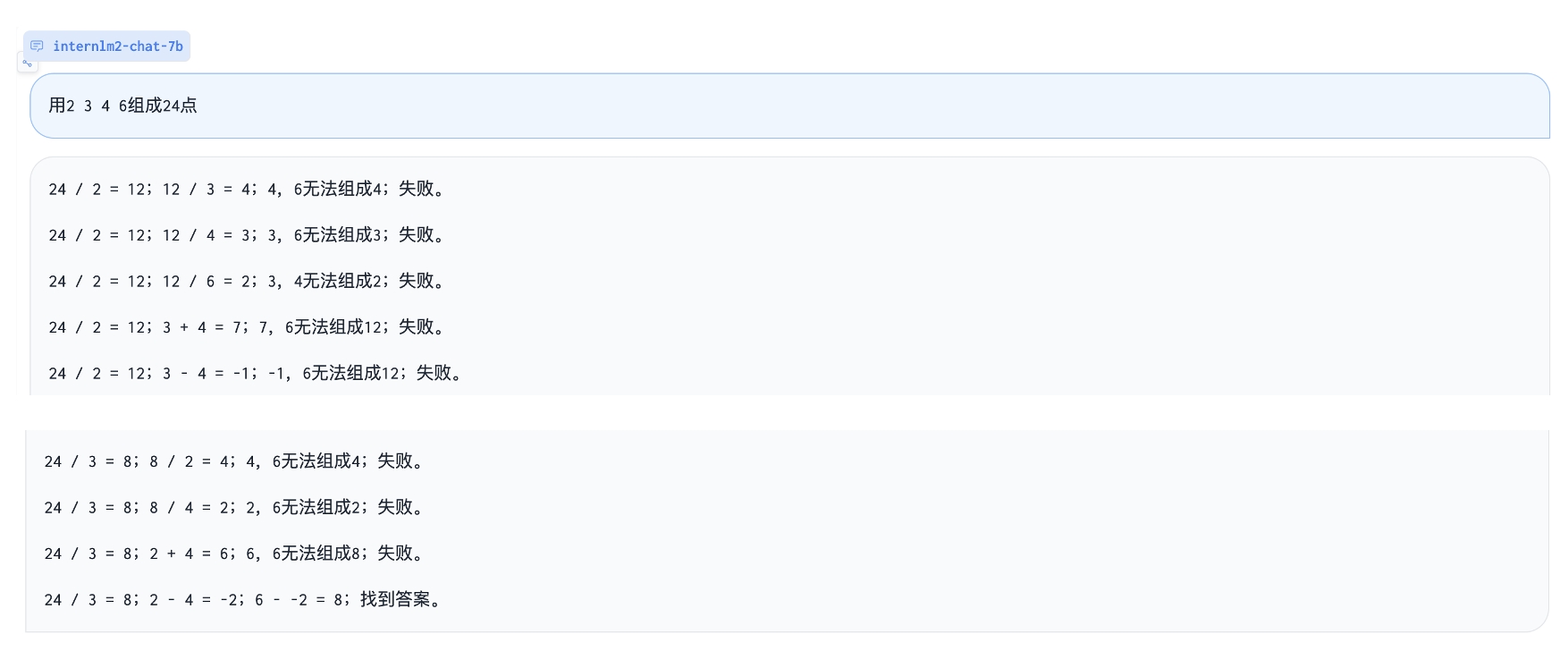
玩24点游戏:
增强更难的数学问题:

| 描述 | 查询 |
|---|---|
| 通过思维链解决问题 | {问题} |
| 通过 Lean 3 解决问题 | {问题}\n用 Lean 3 解决这个问题 |
| 结果奖励模型 | 给定一个问题和一个答案,检查是否正确?\n问题:{问题}\n答案:{思维链} |
| 过程奖励模型 | 给定一个问题和一个答案,检查每一步的正确性。\n问题:{问题}\n答案:{思维链} |
| 奖励模型 | 给定一个问题和两个答案,哪个更好?\n问题:{问题}\n答案1:{思维链}\n答案2:{思维链} |
| 将思维链转换为 Lean 3 | 将此答案转换为Lean3。问题:{问题}\n答案:{思维链} |
| 将 Lean 3 转换为思维链 | 将此 Lean 3 代码转换为自然语言问题和答案:\n{LEAN代码} |
| 将问题和思维链答案转换为证明语句 | 将此问题和答案转换为证明格式。\n问题:{问题}\n答案:{思维链} |
| 将证明问题转换为 Lean 3 | 将此自然语言陈述转换为 Lean 3 定理陈述:{定理} |
| 将 Lean 3 转换为证明问题 | 将此 Lean 3 定理陈述转换为自然语言:{陈述} |
| 根据 Lean 状态建议策略 | 给定 Lean 3 策略状态,建议下一个策略:\n{LEAN状态} |
| 重述问题 | 用另一种方式描述这个问题。{问题} |
| 增强问题 | 请基于以下问题增强一个新问题:{问题} |
| 增强一个更难的问题 | 增加问题的复杂性:{问题} |
| 更改特定数字 | 更改特定数字:{问题} |
| 引入分数或百分比 | 引入分数或百分比:{问题} |
| 代码解释器 | lagent |
| 上下文学习 | 问题:{问题}\n答案:{思维链}\n...问题:{问题}\n答案:{思维链} |
微调和其他
请参考 InternLM。
已知问题
我们的模型仍在开发中,将会升级。InternLM-Math 存在一些可能的问题。如果您发现某些能力的表现不佳,欢迎提出问题。
- 跳过计算步骤。
- 由于 SFT 数据组成,在中文填空问题和英文选择题上表现不佳。
- 由于 SFT 数据组成,在面对中文问题时倾向于生成代码解释器。
- 奖励模型模式可以通过分配的令牌概率更好地利用。
- 由于 SFT 数据组成导致的代码切换。
- 一些 Lean 的能力只能适应类似 GSM8K 的问题(例如将思维链转换为 Lean 3),与 Lean 相关的性能不能保证。
引用和技术报告
@misc{ying2024internlmmath,
title={InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning},
author={Huaiyuan Ying and Shuo Zhang and Linyang Li and Zhejian Zhou and Yunfan Shao and Zhaoye Fei and Yichuan Ma and Jiawei Hong and Kuikun Liu and Ziyi Wang and Yudong Wang and Zijian Wu and Shuaibin Li and Fengzhe Zhou and Hongwei Liu and Songyang Zhang and Wenwei Zhang and Hang Yan and Xipeng Qiu and Jiayu Wang and Kai Chen and Dahua Lin},
year={2024},
eprint={2402.06332},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{ying2024lean,
title={Lean Workbook: A large-scale Lean problem set formalized from natural language math problems},
author={Huaiyuan Ying and Zijian Wu and Yihan Geng and Jiayu Wang and Dahua Lin and Kai Chen},
year={2024},
eprint={2406.03847},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{wu2024leangithubcompilinggithublean,
title={LEAN-GitHub: Compiling GitHub LEAN repositories for a versatile LEAN prover},
author={Zijian Wu and Jiayu Wang and Dahua Lin and Kai Chen},
year={2024},
eprint={2407.17227},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2407.17227},
}
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商�品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号