


Ollama 应用
一个现代化且易于使用的 Ollama 客户端。在保持一切隐私和本地网络的同时,获得最佳体验。
 |  |  |  |
|---|
[!重要] 此应用程序不在设备上托管 Ollama 服务器,而是连接到一个服务器并使用其 API 端点。 你不知道 Ollama 是什么?在 ollama.com 了解更多。
安装
你可以在发布标签下找到 Ollama 应用的最新推荐版本。下载 APK 并安装到你的 Android 设备上。就这么简单,现在继续初始设置。
或者,你也可以从以下任何一个商店下载应用:
初始设置
安装应用并首次打开后,你会看到这个弹出窗口:
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/ff008a0e-1ece-4507-91f8-92045fb486a3.png" alt="欢迎说明" height="720" />一步一步浏览欢迎对话框,你应该阅读其内容,但不是必须的。
 | |  |
|---|
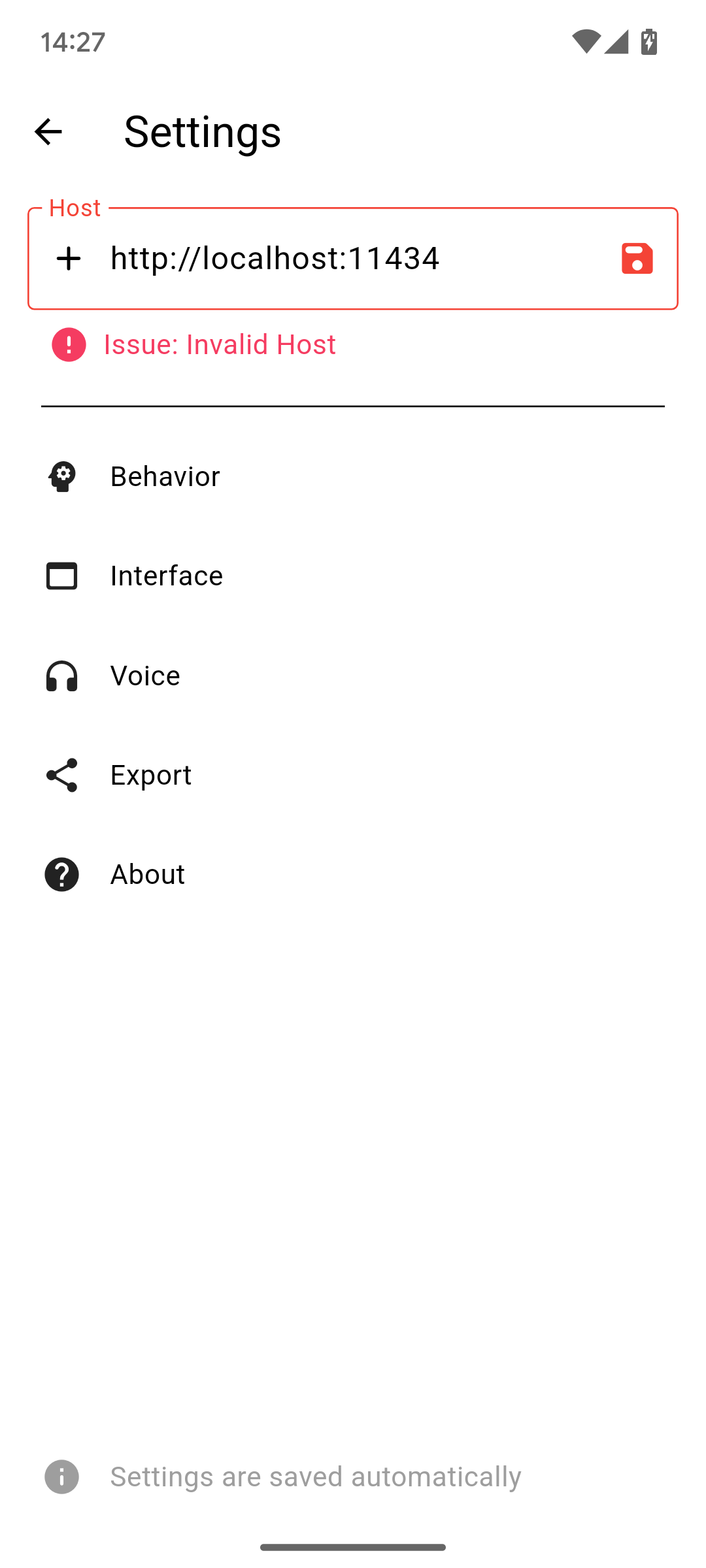
浏览完后,你会看到一个小的提示栏通知你需要设置主机。为此,打开侧边栏(从左向右滑动或点击左上角的图标)并点击设置。在那里你会找到所有与应用相关的设置,你应该浏览一遍,但对于初始设置,只有第一个是重要的。
在大的主机文本字段中,你必须输入你的实例的基本 URL。除非端口号与协��议匹配(HTTPS 为 443 或 HTTP 为 80),否则需要端口。之后,点击文本字段旁边的保存图标。
要了解更多关于主机设置的信息,请访问设置
[!重要] Ollama 服务器需要额外的步骤才能从本地机器外部访问。要了解更多信息,请访问 issue #5
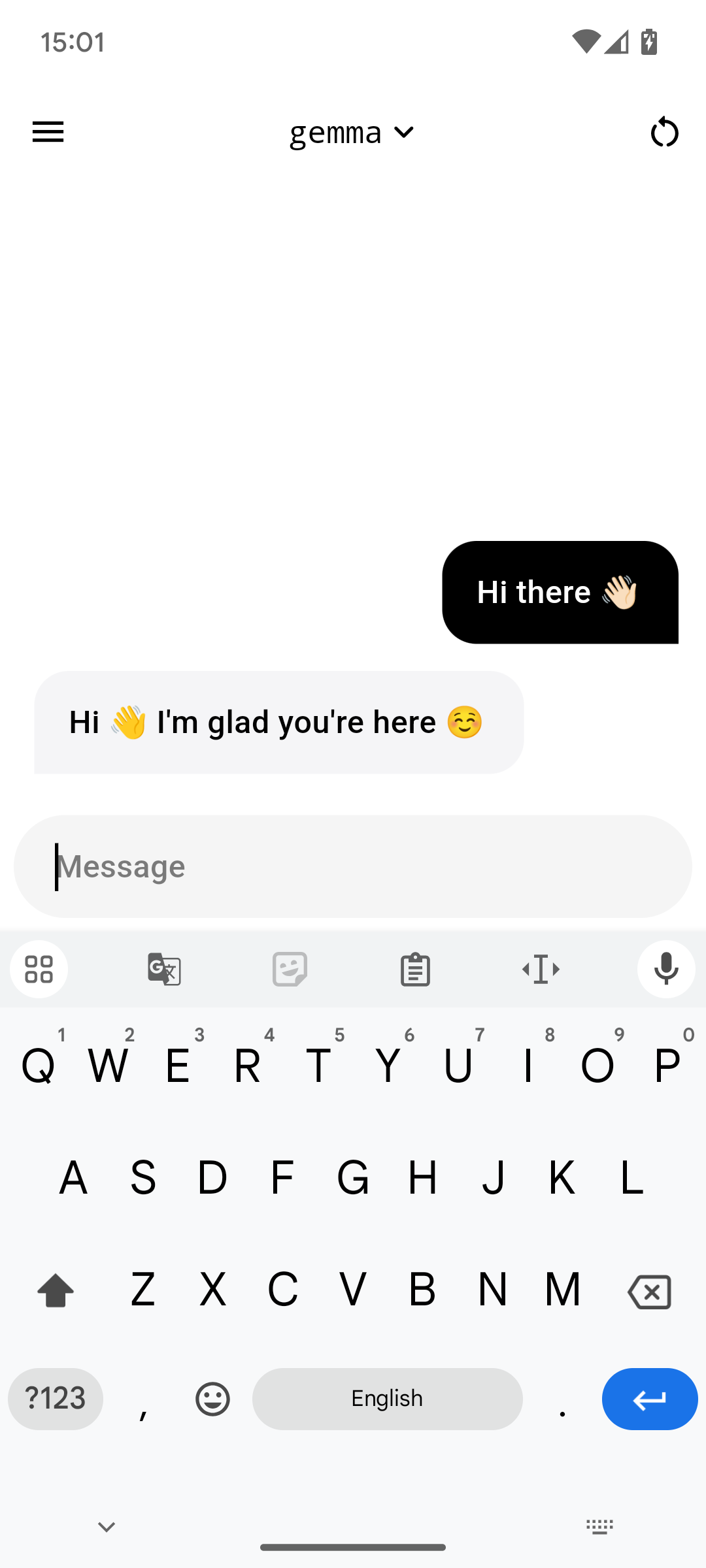
就是这样,现在你可以直接聊天了。在底部的框中输入一条消息,然后点击发送图标。
聊天界面
这是应用的主界面,简单而且最重要的是能正常工作。
[!注意] 要开始聊天,你首先需要在模型选择器中选择一个模型。先做这个,然后再回到这里。
聊天模式很简单。只需写一条消息,等待片刻,答案就会发送到聊天中。
聊天界面默认已经包含了一些有用的功能。可以通过双击你想从世界上抹去的消息来删除消息,包括该消息本身在内的所有自此发送的消息都会被删除。
编辑消息也几乎一样简单。在界面设置中启用消息编辑后,只需长按一条消息,就会打开一个弹出窗口,询问新的内容。
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/b4129798-7371-454e-bd02-85e653f96222.png" alt="消息编辑对话框" height="720" />[!提示] 消息(几乎)完全支持 Markdown 语法。这意味着 AI 将能够以 Markdown 格式接收和发送消息。
多模态输入
Ollama 应用支持多模态模型,即支持通过图像输入的模型。在模型选择器中,支持该技术的模型名称旁边会标有图像图标。
选择多模态模型后,消息栏左下角会出现一个新图标:相机图标。点击它会显示以下底部表单:
 |  |  |
|---|
选择其中一个,拍摄或选择你的照片,它就会被添加到聊天中。允许添加多张图片,只需重复这些步骤。
即使图像在发送后就会出现在聊天中,它们也不会被提交给 AI,直到发送新的文本消息。当你发送消息时,AI 会在考虑图像的情况下回答消息。
模型选择器
你可以通过点击顶部中间的 <selector> 文本或同一位置当前选定的模型名称来访问模型选择器。然后你会看到以下弹出对话框:
这将显示当前安装在你的 Ollama 服务器实例上的所有模型。
名称旁边带星号的模型是推荐模型。它们是由我(嘿嘿)选择列为推荐的。在自定义构建下阅读更多内容。
添加按钮目前不起作用,它只是打开一个列出如何向实例添加模型的步骤的提示栏。出于安全原因,我没有在应用中直接添加通过名称添加模型的功能。
支持多模态输入的模型在其名称旁边标有图像图标,如上图中的 llava。
侧边菜单
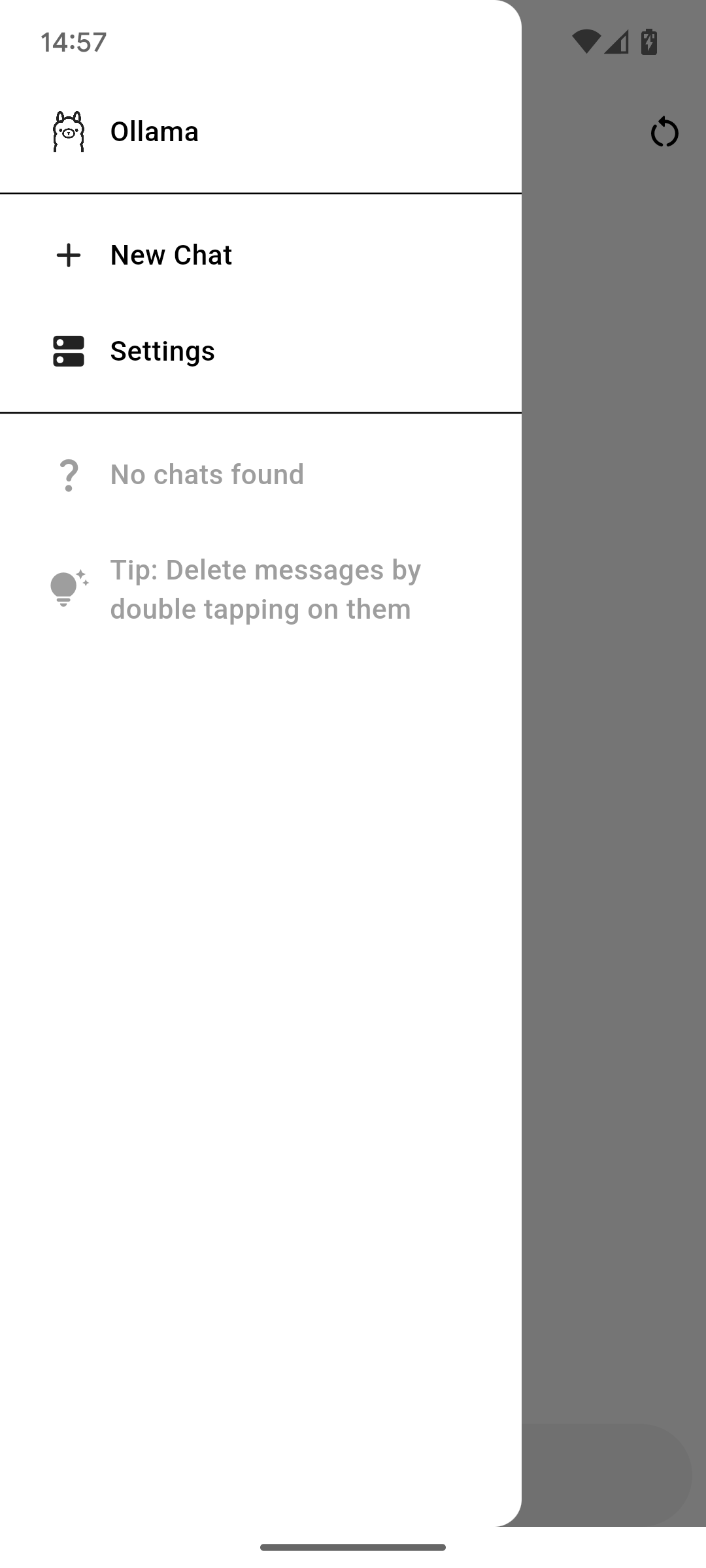
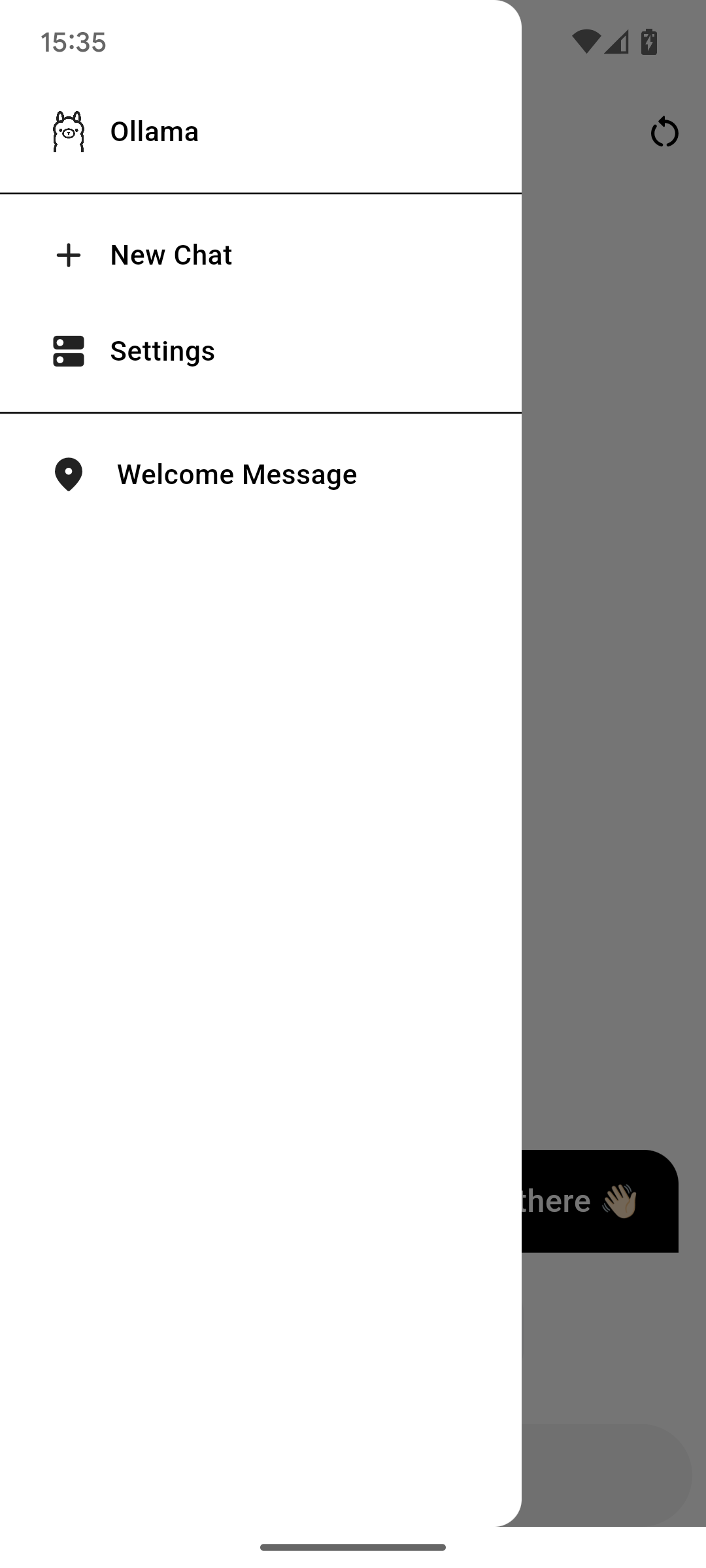
左上角的按钮打开菜单。在其中,你有两个选项:新建聊天和设置。第一个选项创建一个新的聊天,第二个选项打开设置,你可以在其中更改一切的工作方式。
下面是所有的聊天。要删除一个,从左向右滑动。要重命名聊天,点击并按住直到出现弹出对话框。在其中,你可以更改标题或点击闪光图标让 AI 为你找一个。这不受"生成标题"设置的影响。
|  |  |
|---|
[!注意] 右上角的按钮删除聊天。它的效果与在侧边栏中滑动聊天相同。
设置
Ollama 应用提供了许多配置选项。我们将逐一介绍每个选项。
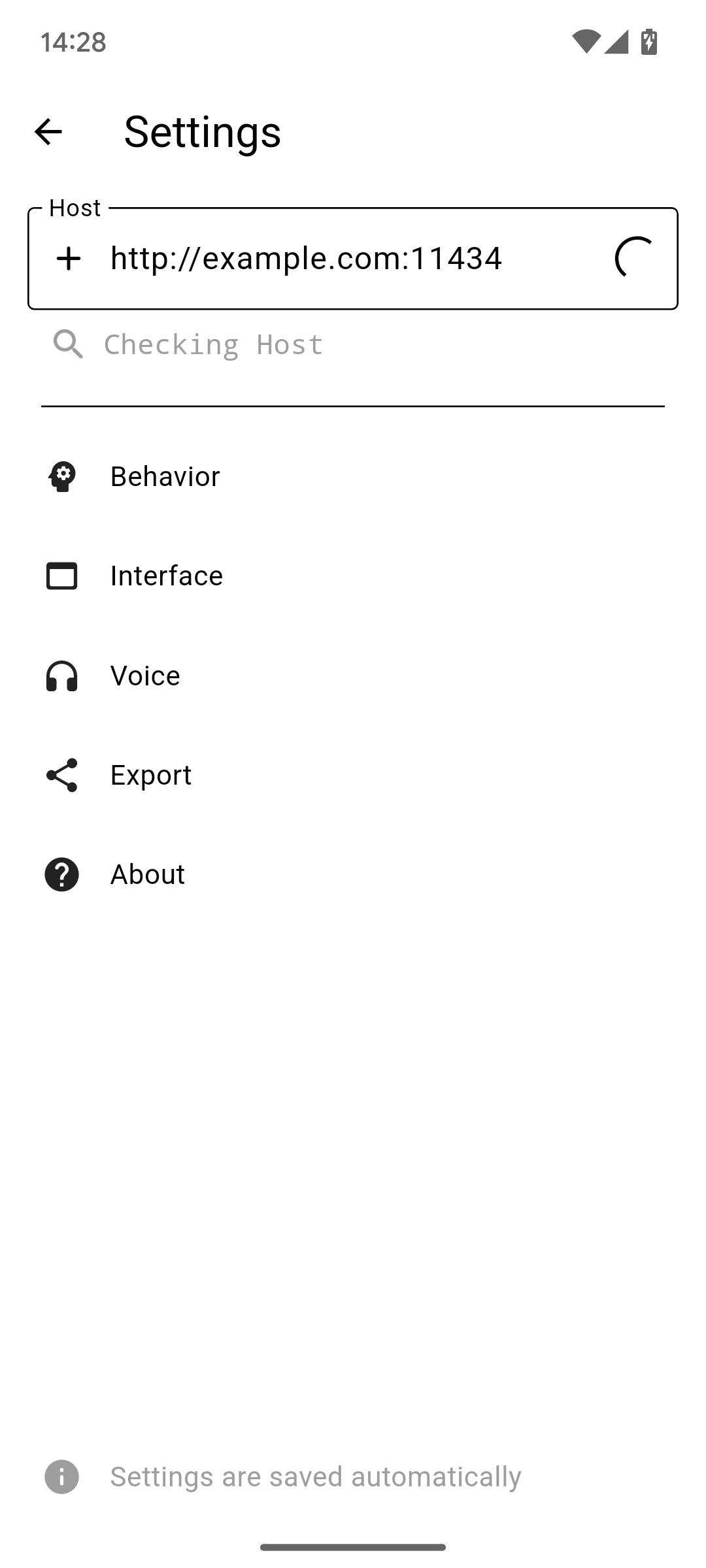
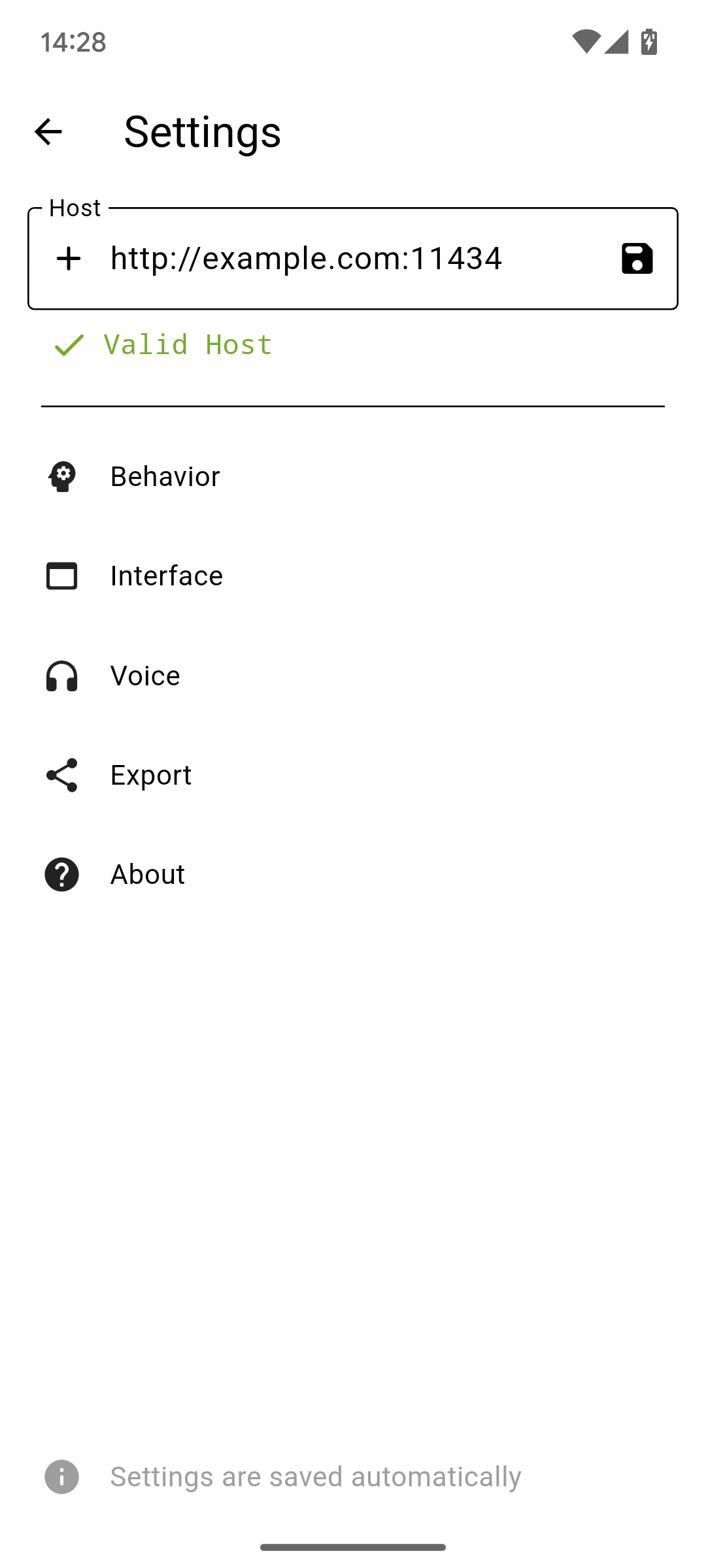
主机
主机是你的 Ollama 服务器的主要地址。它可能包括端口、协议和主机名。不建议使用路径。
|  |  |
|---|
除非端口号与协议匹配(HTTPS 为 443 或 HTTP 为 80),否则需要端口。之后,点击文本字段旁边的保存图标来设置主机。
主机地址将被检查,所以不用担心输入错误的地址。如果你设置了主机,而你的服务器离线,请求将失败,但如果你不自己更改,主机将保持保存。要更改,只需进入侧边菜单并打开设置即可。
自定义标头
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/914dc5e0-4e9a-4081-a1db-22626cd6fa73.png" alt="设置屏幕" height="720" />Ollama 应用支持添加自定义标头。如果你想用身份验证或类似方式保护你的实例,这可能很有用。只需按主机输入旁边的加号图标,并将其设置为 JSON 对象。例如:
{ "Authorization": "Bearer <token>" }
行为
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/3681a251-debf-4c89-837f-ddddff5ce1e3.png" alt="设置屏幕" height="720" />行为设置包括与系统提示相关的设置。它们只有在你创建新�的聊天后才会应用。
系统提示在对话开始时发送给助手。它引导助手朝某个方向发展,它会按照你在这条消息中告诉它的方式说话。要将系统提示重置为默认值,清空其值,点击保存图标并关闭屏幕。
禁用 Markdown 的选项并不安全,助手仍然可能在其响应中添加 Markdown。
界面
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/2c99b1bc-918c-491a-9598-f3d97d380677.png" alt="设置界面" height="720" />界面设置主要集中在Ollama应用的界面上,正如其名称所暗示的那样。以下列表将详细说明所有选项:
- 针对模型选择器:
- 在模型选择器中显示模型标签。如果你安装了同一模型的多个版本,这可能会很有用
- 更换模型时清除聊天记录。强烈建议启用此选项,禁用可能导致意外行为
- 用于聊天视图:
- 设置请求模式。推荐使用流式传输,但有时可能不可用,此时选择"请求"
- 是否使用Ollama AI生成聊天标题。可能会增加潜在的配额成本
- 是否长按消息打开编辑对话框
- 是否在删除聊天前询问。如果聊天中可能存储重要数据,这很有用
- 是否在主侧边栏显示提示
- 后端加载选项:
- 始终保持模型加载状态(
keep_alive设为-1) - 不保持模型加载状态(
keep_alive设为0) - 保持模型活跃的时间
- 始终保持模型加载状态(
- 外观设置:
- 是否启用触觉反馈
- 是否以最大化窗口启动(仅限桌面版)
- 应用主题
- 跟随设备主题/颜色
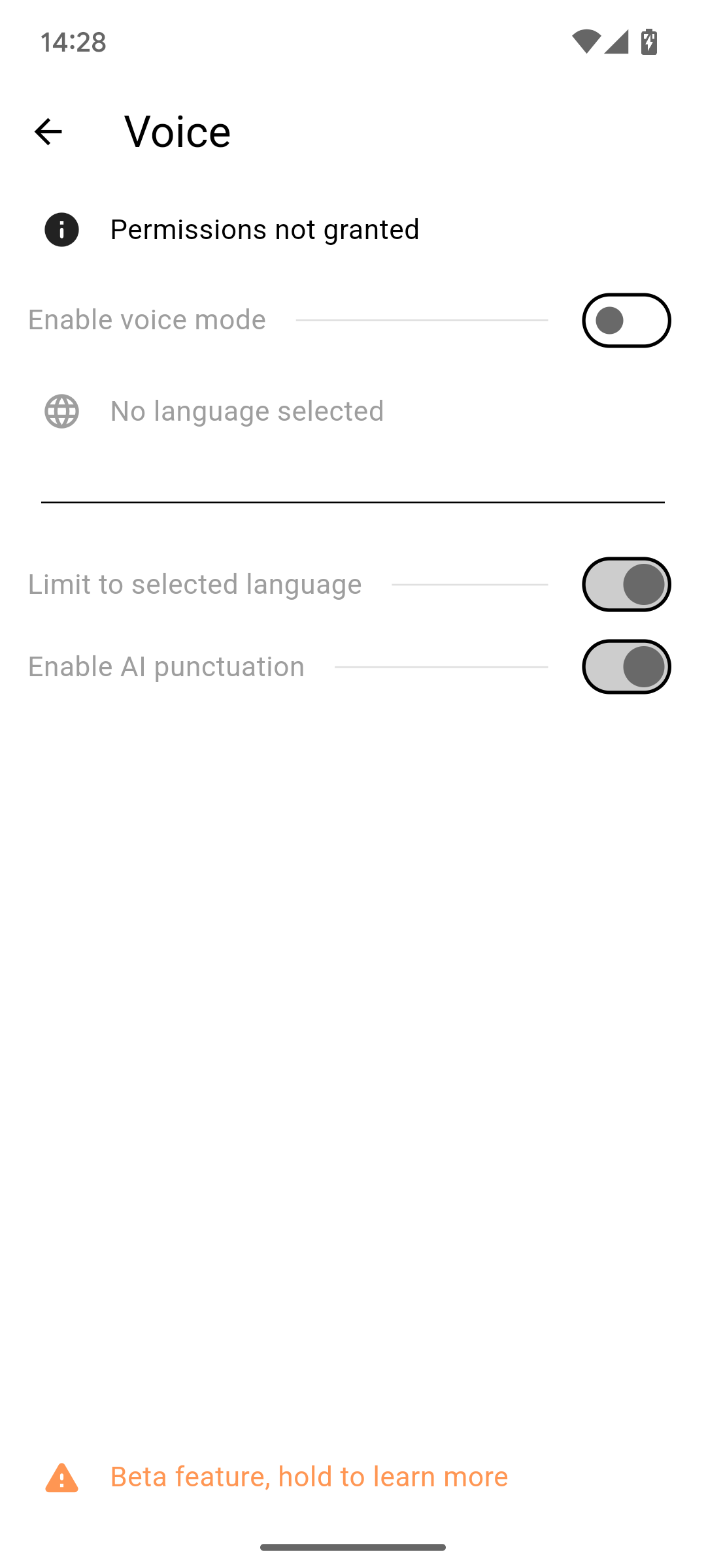
语音
[!警告] 这仍是一项实验性功能!某些功能可能无法按预期工作!
 |  |  |
|---|
点击"未授予权限"按钮以允许所需权限。这些权限是语音转文字功能所必需的。
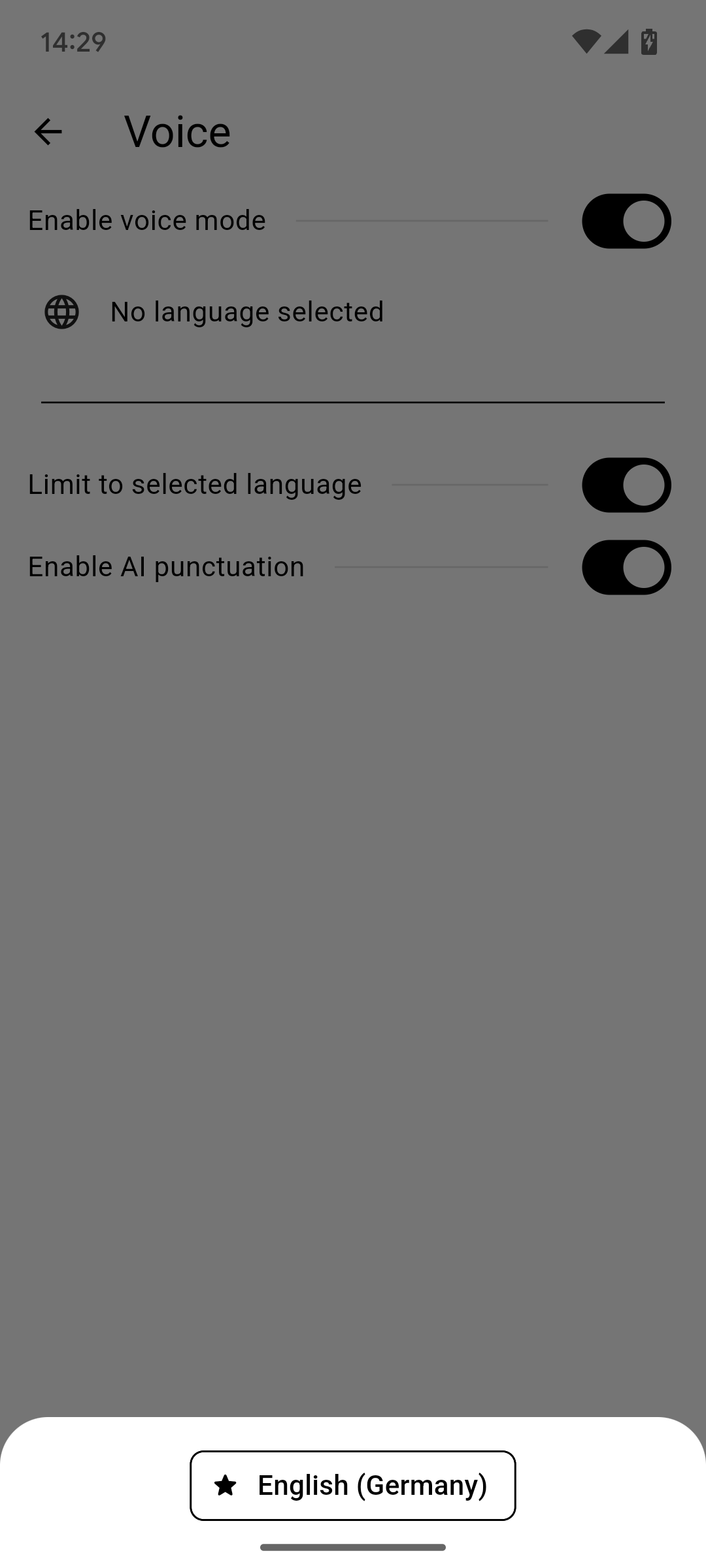
之后,通过切换开关启用语音模式。要使其正常工作,你现在需要点击"未选择语言"并在语言对话框中选择一种语言。就是这样。
然后,在多模态模型的附件图标位置按下按钮,或按下照片图标和"语音"按钮。
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/6c0fc76d-257a-4b96-838f-b690edf078fd.png" alt="设置界面" height="720" />[!注意] 一旦此功能脱离实验阶段,将会添加适当的文档
导出
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/9f33f549-1c7b-49d6-ac3b-bb0d8935a644.png" alt="设置界面" height="720" />导出功能允许你将所有聊天记录导出并保存到文件中。如果你想备份数据或在设备之间同步数据,这可能非常有用。
[!警告] 导入功能会删除当前保存在磁盘上的所有聊天记录,并用文件中的聊天记录替换它们。此操作无法撤销。
关于(和更新)
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/b5ce6b0e-590e-441c-9a9f-262743351afb.png" alt="设置界面" height="720" />关于界面包含许多有用的信息。
你可以直接从这个界面访问应用的GitHub仓库或问题页面。
另一个有用的功能是更新检查器。它会在仓库中查找更新,并提示你直接从GitHub下载。不过要小心,使用的GitHub API有速率限制。在速率限制生效之前,你只能发送有限数量的请求。
多语言界面
Ollama应用支持多种语言。目前可用的语言有:
- 英语(后备)
- 德语
- 中文(简体)
- 意大利语
- 土耳其语
如果语言已100%翻译完成,则会打勾。这可能不是最新情况,请查看项目页面以获取最新进展。
如果你要找的语言没有列出,可以在Crowdin项目页面上查看开发是否正在进行。如果没有,你随时可以贡献。
自定义构建
现在事情变得有趣了。应用的构建方式使你可以轻松创建自定义构建。目前,可以自定义以下值:
// 是否使用主机,如果为false则显示对话框
const useHost = false;
// ollama的主机,必须从客户端可访问,不带尾斜杠,将始终被视为有效
const fixedHost = "http://example.com:11434";
// 是否使用模型,如果为false则显示选择器
const useModel = false;
// 模型名称字符串,必须是有效的ollama模型!
const fixedModel = "gemma";
// 推荐模型,在模型选择器中以星号显示
const recommendedModels = ["gemma", "llama3"];
// 允许打开设置
const allowSettings = true;
// 允许多个聊天
const allowMultipleChats = true;
这些可以在lib/main.dart的顶部找到。useHost和useModel决定是否要使用fixedHost和fixedModel来控制任何内容。fixedHost和fixedModel决定要使用的值。如果你尝试创建特定于你的实例的应用,这可能会很实用。
recommendedModels是一个在模型选择器中列为推荐的模型列表。它们更像是个人偏好。如果为空,则不会优先考虑任何模型。
allowSettings将禁用设置界面。但它也会禁用首次启动时的欢迎对话框和重命名聊天的能力。
allowMultipleChats简单地从侧边菜单中移除"新建聊天"选项。并在应用启动时加载唯一可用的聊天。
实际构建
但你如何创建自定义构建呢?
首先,按照Flutter安装指南选择Android作为第一个应用类型。然后按照这些步骤操作,直到你获得自定义的key.properties。将其放入项目根目录的android文件夹中。
确保dart可作为命令使用或已添加为.dart的默认程序。然后执行scripts/build.dart并等待处理完成。然后转到build/.output。你会在那里找到所需的一切,包括普通的Android应用和实验性的Windows构建。
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,�是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号