
sd-webui-controlnet
为Stable Diffusion WebUI增添高度可控的图像生成功能
sd-webui-controlnet扩展为Stable Diffusion WebUI集成了ControlNet功能。它支持多种控制模型和预处理器,实现像素级精确控制,兼容高分辨率修复和上采样脚本。用户可调整提示词与控制网络的权重,还可使用参考图像进行无模型控制。该扩展显著提升了Stable Diffusion的可控性,为AI图像生成开启更多可能性。




Stable Diffusion WebUI的ControlNet扩展
ControlNet和其他基于注入的SD控制的WebUI扩展。
这个扩展是为AUTOMATIC1111的Stable Diffusion web UI设计的,允许Web UI将ControlNet添加到原始的Stable Diffusion模型中生成图像。这种添加是即时进行的,无需合并。
新闻
- [2024-07-09] 🔥[v1.1.454] 支持ControlNet联合模型 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2989]
- [2024-07-01] 🔥[v1.1.452] Depth Anything V2 - UDAV2深度预处理器 [拉取请求:https://github.com/Mikubill/sd-webui-controlnet/pull/2969]
- [2024-05-19] 🔥[v1.1.449] Anyline预处理器 & MistoLine SDXL模型 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2907]
- [2024-05-04] 🔥[v1.1.447] PuLID [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2841]
- [2024-04-30] 🔥[v1.1.446] ControlNet/IPAdapter支持有效区域蒙版 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2831]
- [2024-04-27] 🔥发布ControlNet-lllite Normal Dsine [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2813]
- [2024-04-19] 🔥[v1.1.445] IPAdapter高级权重 [即时风格] [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2770]
- [2024-04-17] 🔥[v1.1.444] Marigold深度预处理器 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2760]
- [2024-04-15] 🔥发布ControlNet++模型 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2778]
- [2024-04-13] 🔥发布TTPLanet_SDXL_Controlnet_Tile_Realistic v2 [Civitai页面]
- [2024-03-31] 🔥[v1.1.443] IP-Adapter CLIP蒙版和ip-adapter-auto预处理器 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2723]
- [2024-03-20] 🔥IPAdapter组合 [讨论帖:https://github.com/Mikubill/sd-webui-controlnet/discussions/2781]
安装
- 打开"扩展"标签。
- 在该标签中打开"从URL安装"标签。
- 在"扩展的git仓库URL"中输入
https://github.com/Mikubill/sd-webui-controlnet.git。 - 点击"安装"按钮。
- 等待5秒,你会看到消息"已安装到stable-diffusion-webui\extensions\sd-webui-controlnet。使用已安装标签重启"。
- 转到"已安装"标签,点击"检查更新",然后点击"应用并重启UI"。(下次你也可以使用这些按钮来更新ControlNet。)
- 完全重启A1111 webui,包括你的终端。(如果你不知道什么是"终端",你可以重启电脑来达到同样的效果。)
- 下载模型(见下文)。
- 将模型放��入正确的文件夹后,你可能需要刷新才能看到这些模型。刷新按钮在你的"模型"下拉菜单右侧。
下载模型
你可以在这里找到所有下载链接:https://github.com/Mikubill/sd-webui-controlnet/wiki/Model-download。
ControlNet 1.1的特性
完美支持所有ControlNet 1.0/1.1和T2I Adapter模型。
现在我们完美支持所有可用的模型和预处理器,包括对T2I风格适配器和ControlNet 1.1 Shuffle的完美支持。(确保你的YAML文件名和模型文件名相同,参见"stable-diffusion-webui\extensions\sd-webui-controlnet\models"中的YAML文件。)
完美支持A1111高分辨率修复
现在如果你在A1111中开启高分辨率修复,每个controlnet将输出两个不同的控制图像:一个小的和一个大的。小的用于基本生成,大的用于高分辨率修复生成。这两个控制图像由一个智能算法计算,称为"超高质量控制图像重采样"。这是默认开启的,你不需要更改任何设置。
完美支持所有A1111 Img2Img或Inpaint设置和所有蒙版类型
现在ControlNet已经对A1111的不同类型的蒙版进行了广泛测试,包括"Inpaint masked"/"Inpaint not masked",以及"Whole picture"/"Only masked",和"Only masked padding"&"Mask blur"。调整大小完美匹配A1111的"Just resize"/"Crop and resize"/"Resize and fill"。这意味着你可以在A1111 UI的几乎任何地方使用ControlNet,而不会遇到困难!
新的"像素完美"模式
现在如果你开启像素完美模式,你不需要手动设置预处理器(标注器)分辨率。ControlNet将自动为你计算最佳的标注器分辨率,使每个像素完美匹配Stable Diffusion。
用户友好的GUI和预处理器预览
我们重新组织了一些之前令人困惑的UI,比如"新画布的画布宽度/高度",现在它在📝按钮中。现在预览GUI由"允许预览"选项和触发按钮💥控制。预览图像大小比以前更好,你不需要上下滚动 - 你的a1111 GUI不会再混乱了!
支持几乎所有的放大脚本
现在ControlNet 1.1可以支持几乎所有的放大/平铺方法。ControlNet 1.1支持脚本"Ultimate SD upscale"和几乎所有其他基于平铺的扩展。请不要将"Ultimate SD upscale"与"SD upscale"混淆 - 它们是不同的脚本。注意,最推荐的放大方法是"Tiled VAE/Diffusion",但我们尽可能测试了多种方法/扩展。注意,"SD upscale"从1.1.117版本开始支持,如果你使用它,你需要将所有ControlNet图像留空(我们不推荐"SD upscale",因为它有些问题并且无法维护 - 请使用"Ultimate SD upscale"代替)。
更多控制模式(以前称为猜测模式)
我们修复了之前1.0版本猜测模式的许多bug,现在它被称为控制模式
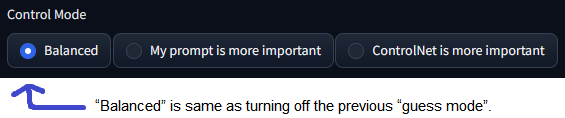
现在你可以控制哪个方面更重要(你的提示词还是你的ControlNet):
-
"平衡":ControlNet在CFG比例的两侧,与在ControlNet 1.0中关闭"猜测模式"相同
-
"我的提示词更重要":ControlNet在CFG比例的两侧,逐步减少SD U-Net注入(layer_weight*=0.825**I,其中0<=I<13,13表示ControlNet注入SD 13次)。这样,你可以确保你的提示词在生成的图像中完美显示。
-
"ControlNet更重要":ControlNet仅在CFG比例的条件方(A1111批处理中的cond)上起作用。这意味着如果你的cfg-scale是X,ControlNet将变得X倍强。例如,如果你的cfg-scale是7,那么ControlNet就会变得7倍强。请注意,这里的X倍强与"控制权重"不同,因为你的权重并未被修改。这种"更强"的效果通常产生的伪影更少,并给予ControlNet更多空间来猜测你的提示中缺失的内容(在之前的1.0版本中,这被称为"猜测模式")。
仅参考控制
现在我们有了一个reference-only预处理器,它不需要任何控制模型。它可以直接使用图像作为参考来引导扩散过程。
(提示词"一只狗在草地上奔跑,最佳质量,...")
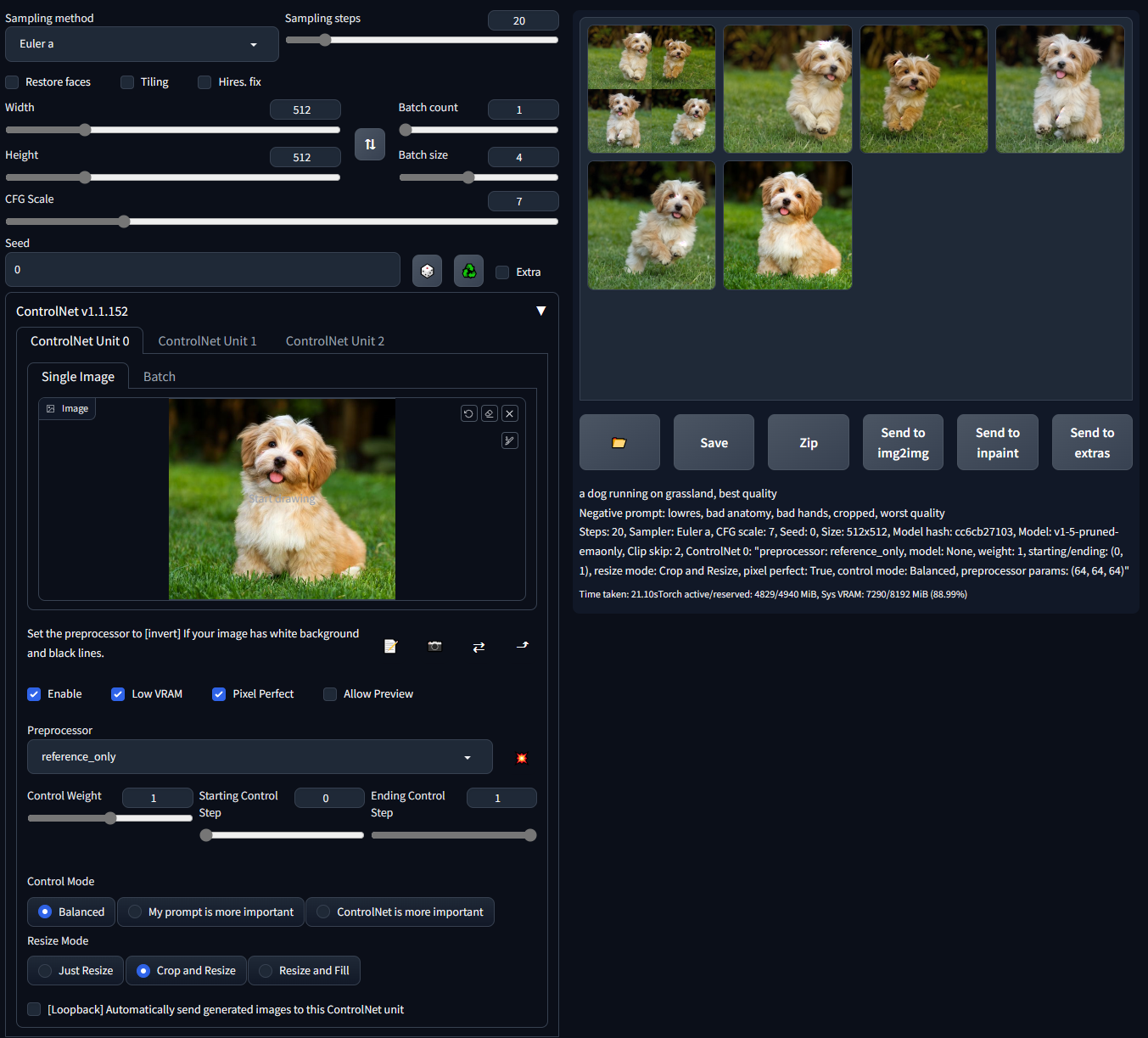
这种方法类似于基于修复的参考,但不会使你的图像变得混乱。
许多专业的A1111用户知道一个技巧,可以通过修复来使用参考图像进行扩散。例如,如果你有一张512x512的狗的图片,想生成另一张具有相同狗的512x512图片,一些用户会将512x512的狗图片和一个512x512的空白图片连接成一个1024x512的图片,发送到修复功能,然后遮罩掉空白的512x512部分,以扩散出一只外观相似的狗。然而,这种方法通常不太令人满意,因为图像是连接的,会出现许多失真。
这个reference-only ControlNet可以直接将你的SD的注意力层链接到任何独立的图像,这样你的SD就可以读取任意图像作为参考。你需要至少ControlNet 1.1.153版本才能使用它。
使用方法很简单,只需选择reference-only作为预处理器并放入一张图片。你的SD就会将该图片作为参考。
请注意,这种方法尽可能地"不带偏见"。它只包含非常基本的连接代码,没有任何个人偏好,用于将注意力层与你的参考图像连接。然而,即使我们尽最大努力不包含任何带有偏见的代码,我们仍然需要编写一些主观实现来处理权重、cfg-scale等 - 技术报告正在编写中。
更多示例请看这里。
技术文档
另请参阅ControlNet 1.1的文档:
https://github.com/lllyasviel/ControlNet-v1-1-nightly#model-specification
默认设置
这是我的设置。如果你遇到任何问题,可以使用这个设置作为健全性检查
使用以前的模型
使用ControlNet 1.0模型
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
你仍然可以使用之前ControlNet 1.0中的所有模型。现在,之前的"depth"现在被称为"depth_midas",之前的"normal"被称为"normal_midas",之前的"hed"被称为"softedge_hed"。从1.1版本开始,所有线条图、边缘图、线稿图、边界图都将有黑色背景和白色线条。
使用T2I-Adapter模型
(来自TencentARC/T2I-Adapter)
要使用T2I-Adapter模型:
- 从https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models 下载文件
- 将它们放入"stable-diffusion-webui\extensions\sd-webui-controlnet\models"目录。
- 确保pth文件和yaml文件的文件名一致。
注意,"CoAdapter"尚未实现。
展示区
以下结果来自ControlNet 1.0。
| 源 | 输入 | 输出 |
|---|---|---|
| (无预处理器) | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/8d114e62-8acf-42ff-86c8-8682e539b03a.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/da93f0e5-a158-4dcd-b27d-892f885078cb.png?raw=true"> |
| (无预处理器) | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/32e52e47-bcaf-4251-9518-e334589a7bb1.jpg?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/c4566bdc-1a73-412a-9532-63dee1061ae2.png?raw=true"> |
| <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/4d601be0-e69c-45c9-94ee-65be7d451755.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/d24b3565-d7ea-46f0-85d5-42a2689b0693.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/e3fa6253-53f1-4dfa-8bf5-91d61efe44ef.png?raw=true"> |
| <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/6520e07d-27f9-42ad-b3ae-10cce1b858d7.jpg?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/98e1eb6f-7d4b-43a5-a232-ce2bc0932ea5.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/b8208d94-671f-43ab-a326-c2c586edff09.png?raw=true"> |
| <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/1b2866a0-e61e-43ee-bf7f-7517a1329baa.jpg?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/1d00d259-99e7-48dd-bad6-72f2bf6facd9.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/425a0db2-2db1-42d5-a75c-4a1355efab15.png?raw=true"> |
| <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/4820bc8d-42af-4641-a612-086d52ee15ac.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/df14fd42-d837-4b52-a773-b939136733b5.png?raw=true"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/628f55a6-facf-4938-9f38-095bc2d0ce1a.png?raw=true"> |
以下示例来自T2I-Adapter。
来自 t2iadapter_color_sd14v1.pth :
| 源 | 输入 | 输出 |
|---|---|---|
| <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/ec0c491a-dd7b-4fc9-a836-9ea379ac3c5e.jpeg"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/7f13a803-a2ff-494e-9799-0ce88b2a2ceb.png"> | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/dd7a3905-b312-4973-8e07-b8d157fed9da.png"> |
来自 t2iadapter_style_sd14v1.pth :
| 源 | 输入 | 输出 |
|---|---|---|
| <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/ec0c491a-dd7b-4fc9-a836-9ea379ac3c5e.jpeg"> | (clip,非图像) | <img width="256" alt="" src="https://yellow-cdn.veclightyear.com/835a84d5/a9f2c76c-1b4c-4dfc-a849-f9af122fa395.png"> |
最低要求
- (Windows)(NVIDIA:Ampere)4GB - 启用
--xformers选项,并在用户界面中勾选"低VRAM模式",可支持最高768x832分辨率
多重ControlNet
此选项允许单次生成使用多个ControlNet输入。要启用此选项,请在设置中更改"多重ControlNet:最大模型数量(需要重启)"。请注意,更改后需要重启WebUI才能生效。
<table width="100%"> <tr> <td width="25%" style="text-align: center">源A</td> <td width="25%" style="text-align: center">源B</td> <td width="25%" style="text-align: center">输出</td> </tr> <tr> <td width="25%" style="text-align: center"><img src="https://yellow-cdn.veclightyear.com/835a84d5/86f6d8dd-af37-4ded-b4b2-3373d841958d.png"></td> <td width="25%" style="text-align: center"><img src="https://yellow-cdn.veclightyear.com/835a84d5/e42cdfac-113f-48ce-8fab-318f593cbf88.png"></td> <td width="25%" style="text-align: center"><img src="https://yellow-cdn.veclightyear.com/835a84d5/97c0fd83-e01e-4358-894d-338efc7db016.png"></td> </tr> </table>控制权重/开始/结束
权重是ControlNet"影响"的权重。它类似于提示词的注意力/强调。例如(myprompt:1.2)。从技术角度来说,它是在将ControlNet输出与原始SD Unet合并之前,用于乘以ControlNet输出的因子。
引导开始/结束是ControlNet应用的总步骤百分比(引导强度 = 引导结束)。它类似于提示词编辑/转移。例如 [myprompt::0.8](从开始应用到总步骤的80%)
批处理模式
将任何单元设置为批处理模式以激活所有单元的批处理模式。为每个单元指定批处理目录,或使用img2img批处理选项卡中的新文本框作为后备选项。尽管该文本框位于img2img批处理选项卡中,但您也可以使用它在txt2img选项卡中生成图像。
请注意,此功能仅在gradio用户界面中可用。如需自定义批处理调度,请多次调用API。
API和脚本访问
此扩展可以通过API或外部扩展调用接受txt2img或img2img任务。请注意,对于外部调用,您可能需要在设置中启用"允许其他脚本控制此扩展"。
使用API:使用参数 --api 启动WebUI,然后访问 http://webui-address/docs 获取文档,或查看示例。
使用外部调用:查看Wiki
命令行参数
此扩展为webui添加了以下命令行参数:
--controlnet-dir <controlnet模型目录路径> 添加controlnet模型目录
--controlnet-annotator-models-path <标注器模型目录路径> 设置标注器模型目录
--no-half-controlnet 以全精度加载controlnet模型
--controlnet-preprocessor-cache-size controlnet预处理器结果的缓存大小
--controlnet-loglevel controlnet扩展的日志级别
--controlnet-tracemalloc 启用malloc内存追踪
MacOS支持
已在pytorch nightly版本上测试:https://github.com/Mikubill/sd-webui-controlnet/pull/143#issuecomment-1435058285
要在mps和普通pytorch上使用此扩展,目前您可能需要使用 --no-half 参数启动WebUI。
已弃用版本的存档
之前的版本(sd-webui-controlnet 1.0)已存档在
https://github.com/lllyasviel/webui-controlnet-v1-archived
使用此版本并不是暂时停止更新。您将永久停止所有更新。
如果您与要求100%精确复现所有先前结果(逐像素)的专业工作室合作,请考虑使用此版本。
致谢
此实现受到kohya-ss/sd-webui-additional-networks的启发
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音�助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的�性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号