


ComfyUI-3D包
使ComfyUI生成3D资产变得像生成图像/视频一样好用和方便! <br> 这是一个广泛的节点套件,使ComfyUI能够使用尖端算法(3DGS、NeRF等)和模型(InstantMesh、CRM、TripoSR等)处理3D输入(网格和UV纹理等)。
<span style="font-size:1.5em;"> <a href=#Features>功能</a> — <a href=#install>安装</a> — <a href=#roadmap>路线图</a> — <a href=#development>开发</a> — <a href=#tips>提示</a> — <a href=#supporters>支持者</a> </span>安装:
可以直接从ComfyUI-Manager安装🚀
- 预构建版本可用于:
- Windows 10/11,Ubuntu 22.04
- Python 3.10/3.11/3.12
- CUDA 12.1/11.8
- torch 2.3.0+cu121/cu118,torchvision 0.18.0+cu121/cu118
- install.py将根据您的运行环境自动下载并安装预构建版本,如果找不到相应的预构建版本,则构建脚本将自动启动,如果自动构建对您不起作用,请查看半自动构建指南
- 如果在任何开放的Comfy3D工作流程中缺少任何节点,只需在ComfyUI-Manager中点击安装缺失的自定义节点
- 如果由于某些原因您的comfy3d无法自动下载预训练模型,您始终可以手动下载它们并将其放入Checkpoints目录下的正确文件夹中,但请不要覆盖任何现有的.json�文件
- Docker安装请查看DOCKER_INSTRUCTIONS.md
- **注意:**目前,您仍需要安装Visual Studio Build Tools for Windows和为Linux安装
gcc g++,以使InstantNGP & Convert 3DGS to Mesh with NeRF and Marching_Cubes节点工作,因为这两个节点使用了在运行时构建的JIT torch cpp扩展,但我计划很快替换这些节点
功能:
-
使用案例请查看示例工作流程。[最后更新:2024年8月1日]
- **注意:**在运行示例工作流程之前,您需要将示例输入文件和文件夹放在ComfyUI根目录\ComfyUI\input文件夹下
- tripoSR分层扩散工作流程由@Consumption提供
-
StableFast3D:Stability-AI/stable-fast-3d
- 单张图像到带RGB纹理的3D网格
- 注意:在能够下载模型权重之前,您需要同意Stability-AI的使用条款,如果您手动下载了模型权重,则需要将其放在Checkpoints/StableFast3D下,否则您可以在Configs/system.conf中添加您的huggingface令牌
- 模型权重:https://huggingface.co/stabilityai/stable-fast-3d/tree/main
<video controls autoplay loop src="https://github.com/user-attachments/assets/3ed3d1ed-4abe-4959-bd79-4431d19c9d47"></video>
-
CharacterGen:zjp-shadow/CharacterGen
- 任意姿势的角色单个正面视图
- 可以与Unique3D工作流程结合以获得更好的结果
- 模型权重:https://huggingface.co/zjpshadow/CharacterGen/tree/main
<video controls autoplay loop src="https://github.com/user-attachments/assets/4f0ae0c0-2d29-49f0-a6f2-a636dd4b4dcc"></video>
-
Unique3D:AiuniAI/Unique3D
- 四个阶段的流程:
- 单张图像到4个多视图图像,分辨率:256X256
- 一致的多视图图像上采样到512X512,超分辨率到2048X2048
- 多视图图像到法线贴图,分辨率:512X512,超分辨率到2048X2048
- 多视图图像和法线贴图到带纹理的3D网格
- 要使用所有阶段Unique3D工作流程,下载模型:
- sdv1.5-pruned-emaonly并将其放入
您的ComfyUI根目录/ComfyUI/models/checkpoints - fine-tuned controlnet-tile并将其放入
您的ComfyUI根目录/ComfyUI/models/controlnet - ip-adapter_sd15并将其放入
您的ComfyUI根目录/ComfyUI/models/ipadapter - OpenCLIP-ViT-H-14,将其重命名为OpenCLIP-ViT-H-14.safetensors并放入
您的ComfyUI根��目录/ComfyUI/models/clip_vision - RealESRGAN_x4plus并将其放入
您的ComfyUI根目录/ComfyUI/models/upscale_models
- sdv1.5-pruned-emaonly并将其放入
- 模型权重:https://huggingface.co/spaces/Wuvin/Unique3D/tree/main/ckpt
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/45dd6bfc-4f2b-4b1f-baed-13a1b0722896"></video>
- 四个阶段的流程:
-
Era3D MVDiffusion模型:pengHTYX/Era3D
- 单张图像到6个多视图图像和法线贴图,分辨率:512X512
- 注意:您至少需要16GB显存才能运行此模型
- 模型权重:https://huggingface.co/pengHTYX/MacLab-Era3D-512-6view/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/fc210cac-6c7d-4a55-926c-adb5fb7b0c57"></video>
-
InstantMesh重建模型:TencentARC/InstantMesh
- 白色背景的稀疏多视图图像到带RGB纹理的3D网格
- 适用于任意MVDiffusion模型(可能与Zero123++效果最佳,但也适用于CRM MVDiffusion模型)
- 模型权重:https://huggingface.co/TencentARC/InstantMesh/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/a0648a44-f8cb-4f78-9704-a907f9174936"></video> <video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/33aecedb-f595-4c12-90dd-89d5f718598e"></video>
-
Zero123++:SUDO-AI-3D/zero123plus
- 单张图像到6个视图图像,分辨率:320X320
-
卷积重建模型: thu-ml/CRM
- 三阶段流程:
- 单张图像转换为6个视角图像(前、后、左、右、上、下)
- 单张图像和6个视角图像转换为6个相同视角的CCM(规范坐标图)
- 6个视角图像和CCM生成3D网格
- 注意: 对于低显存电脑,如果无法将三个阶段的所有模型都装入GPU内存,可以将这三个阶段分成不同的ComfyUI工作流程,分别运行
- 模型权重: https://huggingface.co/sudo-ai/zero123plus-v1.2
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/cf68bb83-9244-44df-9db8-f80eb3fdc29e"></video>
- 三阶段流程:
-
TripoSR: VAST-AI-Research/TripoSR | ComfyUI-Flowty-TripoSR
- 生成NeRF表示,并使用行进立方体算法将其转换为3D网格
- 模型权重: https://huggingface.co/stabilityai/TripoSR/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/ec4f8df5-5907-4bbf-ba19-c0565fe95a97"></video>
-
Wonder3D: xxlong0/Wonder3D
- 从单张图像生成空间一致的6个视角图像和法线贴图
- 模型权重: https://huggingface.co/flamehaze1115/wonder3d-v1.0/tree/main
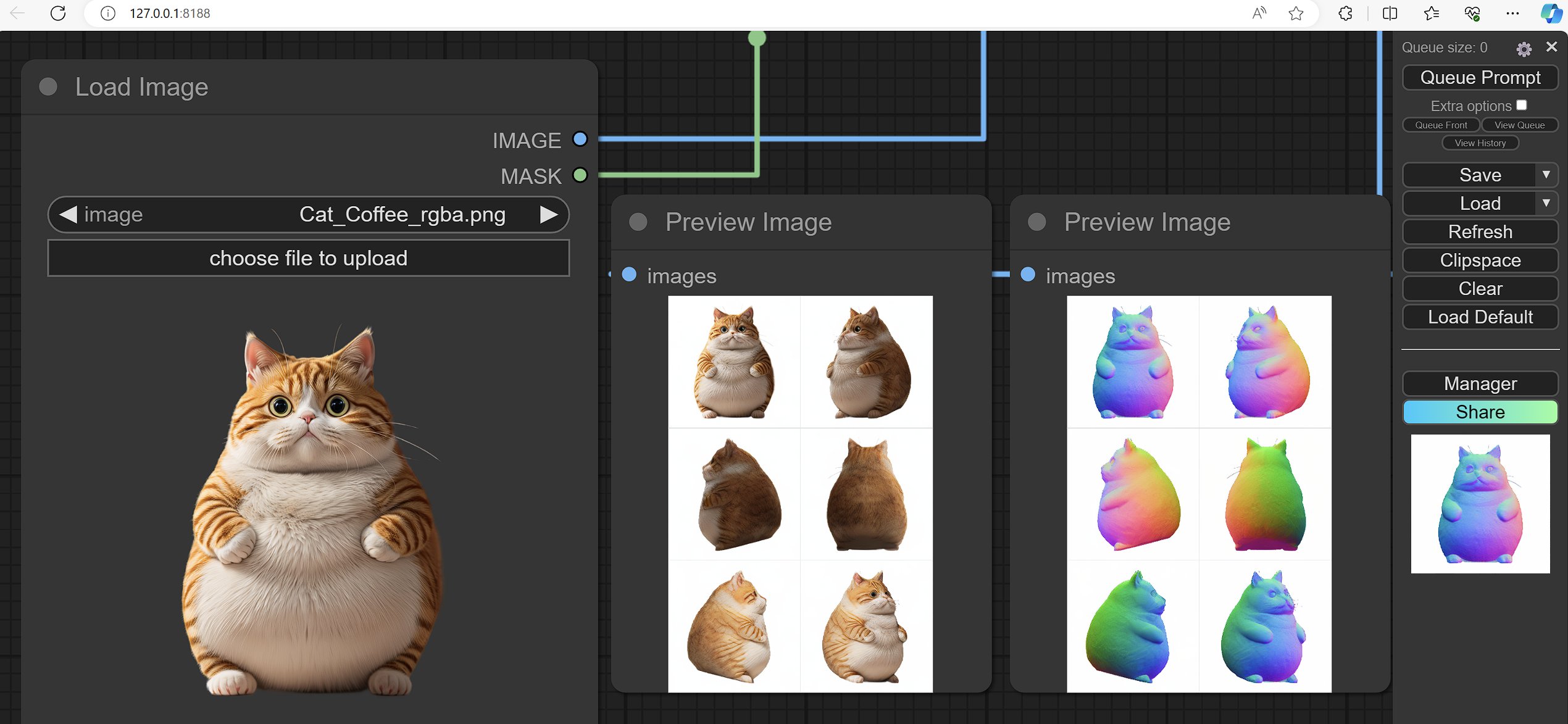
-
大规模多视角高斯模型: 3DTopia/LGM
- 在RTX3080 GPU上不到30秒内从单张图像生成3D高斯,之后还可以将3D高斯转换为网格
- 模型权重: https://huggingface.co/ashawkey/LGM/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/e221d7f8-49ac-4ed4-809b-d4c790b6270e"></video>
-
三平面高斯变换器: VAST-AI-Research/TriplaneGaussian
- 在RTX3080 GPU上不到10秒内从单张图像生成3D高斯,之后还可以将3D高斯转换为网格
- 模型权重: https://huggingface.co/VAST-AI/TriplaneGaussian/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/90e7f298-bdbd-4c15-9378-1ca46cbb4871"></video>
-
预览3DGS和3D网格: ComfyUI内的3D可视化:
- 分别使用gsplat.js和three.js进行3DGS和3D网格可视化
- 基于JS库的可自定义背景: mdbassit/Coloris
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/9f3c56b1-afb3-4bf1-8845-ab1025a87463"></video>
-
堆叠轨道相机姿�态: 自动生成全范围的相机姿态组合
-
可用于调节StableZero123 (需要先下载检查点),在一次提示中覆盖全范围的相机姿态
-
可用于生成轨道相机姿态,并直接输入到其他3D处理节点(如高斯溅射和网格纹理烘焙)
-
使用示例:
<img src="https://yellow-cdn.veclightyear.com/835a84d5/42ecb056-5eff-4ae5-abec-ce7551469859.png" width="256"/> <img src="https://yellow-cdn.veclightyear.com/835a84d5/9f0b6caa-c5fe-412a-b79d-431a4bf9b589.png" width="256"/> <br> <img src="https://yellow-cdn.veclightyear.com/835a84d5/99456c95-6eba-4bad-89f8-07141f28d387.gif" width="256"/> <img src="https://yellow-cdn.veclightyear.com/835a84d5/f083516d-c687-47d3-a096-713795fc6384.gif" width="256"/>
-
坐标系统:
- 方位角: 俯视图中,从0度角开始旋转360度,步长为-90度,得到(0, -90, -180/180, 90, 0),此时相机顺时针旋转,反之亦然。
- 仰角: 当相机水平向前指时为0度,指向地面为负角度,反之亦然。
-
-
FlexiCubes: nv-tlabs/FlexiCubes
- 多视角深度图和蒙版(可选法线贴图)作为输入
- 导出为3D网格
- 使用指南:
- voxel_grids_resolution: 决定网格分辨率/质量
- depth_min_distance depth_max_distance: 物体到相机的距离,渲染中比depth_min_distance更近(更远)的物体部分将被渲染为纯白(黑)RGB值1, 1, 1(0, 0, 0)
- mask_loss_weight: 控制重建3D网格的轮廓
- depth_loss_weight: 控制重建3D网格的形状,这个损失还会影响网格��表面的变形细节,因此结果取决于深度图的质量
- normal_loss_weight: 可选。用于细化网格表面的变形细节
- sdf_regularizer_weight: 有助于去除应用目标未监督区域中的浮点,例如仅使用图像监督时的内部面
- remove_floaters_weight: 如果在平坦区域观察到伪影,可以增加这个值
- cube_stabilizer_weight: 这在单个形状的优化过程中没有显著影响,但在某些情况下有助于稳定训练
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/166bbc1f-04b7-42c8-87bb-302e3f5aabb2"></video>
-
Instant NGP: nerfacc
- 多视角图像作为输入
- 使用行进立方体算法导出为3D网格
-
3D高斯溅射
- 改进的微分高斯光栅化
- 来自Gsgen的更好的基于紧凑性的密化方法
- 支持从给定3D网格初始化高斯分布(可选)
- 支持小批量优化
- 多视角图像作为输入
- 支持导出标准3DGS .ply格式
-
高斯溅射轨道渲染器
- 给定3DGS文件和由堆叠轨道相机姿态节点生成的相机姿态,将3DGS渲染为图像序列或视频
-
网格轨道渲染器
- 给定网格文件和由堆叠轨道相机姿态节点生成的相机姿态,将3D网格渲染为图像序列或视频
-
多视角图像网格拟合
- 使用Nvdiffrast将多视角图像烘焙到给定3D网格的UV纹理中,支持:
- 导出为.obj, .ply, .glb格式
-
保存和加载3D文件
- .obj, .ply, .glb格式用于3D网格
- .ply格式用于3DGS
-
3DGS和3D网格的轴切换
- 由于不同算法可能使用不同的坐标系统,因此重新映射坐标轴的能力对于在不同节点之间传递生成结果至关重要。
-
- 自定义客户端IP地址
- 添加你的Hugging Face用户令牌
路线图:
-
改进3DGS/Nerf到网格的转换算法:
- 寻找更好的方法将3DGS或点云转换为网格(可能通过法线贴图重建?)
-
添加并改进一些最佳的MVS算法(如2DGS等)
-
从原始多视图图像添加相机姿态估计
开发
如何贡献
- Fork项目
- 进行改进/添加新功能
- 创建一个Pull Request到dev分支
项目结构
-
nodes.py: <br>包含所有Comfy3D节点的接口代码(即在ComfyUI中实际可见和使用的节点),你可以在这里添加新节点
-
Gen_3D_Modules: <br>包含所有生成模型/系统代码的文件夹(如多视图扩散模型、3D重建模型)�。新的3D生成模块应添加在这里
-
MVs_Algorithms: <br>包含所有多视图立体算法代码的文件夹,即将多视图图像转换为3D表示(如高斯、MLP或网格)的算法(如高斯散射、NeRF和FlexiCubes)。新的MVS算法应添加在这里
-
web: <br>包含所有浏览器UI相关文件和代码(html、js、css)的文件夹(如html布局、样式和3D网格及高斯预览的核心逻辑)。新的网页UI应添加在这里
-
webserver: <br>包含与浏览器通信代码的文件夹,即处理网页客户端请求(如当请求特定URL路由时向客户端发送3D网格)。新的网页服务器相关功能应添加在这里
-
Configs: <br>包含不同模块配置文件的文件夹,新的配置应添加在这里,如果单个模块有多个配置,请使用子文件夹(如Unique3D、CRM)
-
Checkpoints: <br>包含所有预训练模型和一些diffusers所需模型架构配置文件的文件夹。如果新的检查点可以由
Load_Diffusers Pipeline节点自动下载,那么应该添加在这里 -
install.py: <br>主安装脚本,将根据您的运行环境自动下载并安装预构建,如果找不到对应的预构建,则构建脚本将自动启动,由ComfyUI-Manager在使用pip安装requirements.txt中列出的依赖项后立即调用 <br>如果您尝试添加的新模块需要一些无法简单添加到requirements.txt和build_config.remote_packages的额外包,那么您可以尝试通过修改此脚本来添加
-
_Pre_Builds: <br>包含构建所有必需依赖项的文件和代码的文件夹,如果您想预构建一些额外的依赖项,请查看_Pre_Builds/README.md以获取更多信息
提示
- OpenGL(Three.js、Blender)世界和相机坐标系:
世界 相机 +y 上 目标 | | / | | / |______+x |/______右 / / / / / / +z 前方 z轴指向您并从屏幕中伸出 仰角:在(-90,90)范围内,从+y到+x为(-90,0) 方位角:在(-180,180)范围内,从+z到+x为(0,90) - 如果遇到OpenGL错误(例如,
[F glutil.cpp:338] eglInitialize() failed),则在相应节点上将force_cuda_rasterize设置为true - 如果安装后,您的ComfyUI在启动或运行时卡住,您可以按照以下链接中的说明解决问题:在GPU上评估神经元模型时代码无限期挂起
支持者
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作��服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系�统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号