



SoccerNet 比赛状态重建
小地图上运动员的端到端跟踪和识别
[论文] [视频] [演示] [教程] [网站] [TrackLab] [EvalAI]

![]()
SoccerNet比赛状态重建:小地图上运动员的端到端跟踪和识别, CVPRW'24
Vladimir Somers, Victor Joos, Anthony Cioppa, Silvio Giancola, Seyed Abolfazl Ghasemzadeh, Floriane Magera, Baptiste Standaert, Amir Mohammad Mansourian, Xin Zhou, Shohreh Kasaei, Bernard Ghanem, Alexandre Alahi, Marc Van Droogenbroeck, Christophe De Vleeschouwer
欢迎使用SoccerNet比赛状态任务和挑战的开发套件。 该套件旨在帮助您开始处理数据和提出的任务。
SoccerNet比赛状态开�发套件基于TrackLab构建,TrackLab是一个多目标跟踪研究框架。
⚽ 什么是SoccerNet GSR? SoccerNet比赛状态重建(GSR)是一项新颖的计算机视觉任务,涉及从单个移动摄像机跟踪和识别球员,以构建类似视频游戏的小地图,无需球员佩戴任何特定硬件。 👉 虽然这项任务对体育产业具有巨大价值,但直到现在还没有适当的开源基准来比较方法!
🔎 工作亮点: 我们为比赛状态重建引入了一个新的基准,包括一个包含200个带注释片段的新数据集和一个新的评估指标。此外,我们发布了这个代码库,利用各种最先进的深度学习方法来支持该任务的进一步研究。
参加我们即将举行的CVPR 2024国际挑战赛(CVSports研讨会)! 参赛截止日期定于2024年5月30日。 官方挑战规则和提交说明可在ChallengeRules.md中找到。您可以将您的预测提交到EvalAI评估服务器。
🚀 新闻
[!重要] 我们更新了bbox-pitch注释以提高时间一致性。 请确保您至少使用数据集的1.3版本。 在Labels-GameState.json中:"info" > "version" >= 1.3
当前最新版本:
1.3
这个代码库仍在积极开发中,请务必定期回来获取最新更新! 别忘了将sn-gamestate和tracklab仓库都更新到最新提交。 如果遇到任何问题,请随时在GitHub上开启issue或在我们的官方Discord频道与我们互动:我们 很乐意提供详细说明来帮助您。
即将推出
- 发布sn-gamestate仓库
- SoccerNet比赛状态重建数据集可供下载
- 完整的基于TrackLab的基线构建可供参与者使用
- EvalAI服务器开放评估
- 提供有关新的比赛状态重建评估指标的更多详细信息
- 关于如何开始挑战和基线的直播教程
- 发布SoccerNet比赛状态重建论文,详细介绍任务、数据集、基线和评估指标。
- 发布新的可视化工具(参见演示视频和gif)
更新:
- [2024.07.10] 添加了"No Bells, Just Whistles"校准。
要测试,请在
soccernet.yaml中使用"nbjw_calib"替代"tvcalib",用于pitch和calibration。 - [2024.05.13] 发布数据集V1.3版本,更新了边界框-球场注释。
- [2024.05.08] 发布基线挑战追踪器状态:https://zenodo.org/records/11143697
- [2024.04.25] 发布基线验证和测试追踪器状态:https://zenodo.org/records/11065177
- [2024.03.27] 在ChallengeRules.md中发布提交说明。
- [2024.03.26] EvalAI服务器开放评估
- [2024.03.21] 发布数据集V1.2版本,修复了左/右队标签
- [2024.02.13] 完整基线发布
- [2024.02.11] 数据集可供下载
- [2024.02.05] 公开发布
⚽️ 关于比赛状态重建任务
比赛状态重建可以被视为一项压缩任务,目标是从原始视频输入中提取体育比赛的高级信息。 需要提取的高级信息包括以下内容:
- 场上所有运动员的2D位置
- 他们的角色(球员、守门员、裁判、其他)
- 对于球员和守门员:
- 他们的球衣号码
- 他们的队伍归属(即相对于摄像机视角的左侧或右侧)
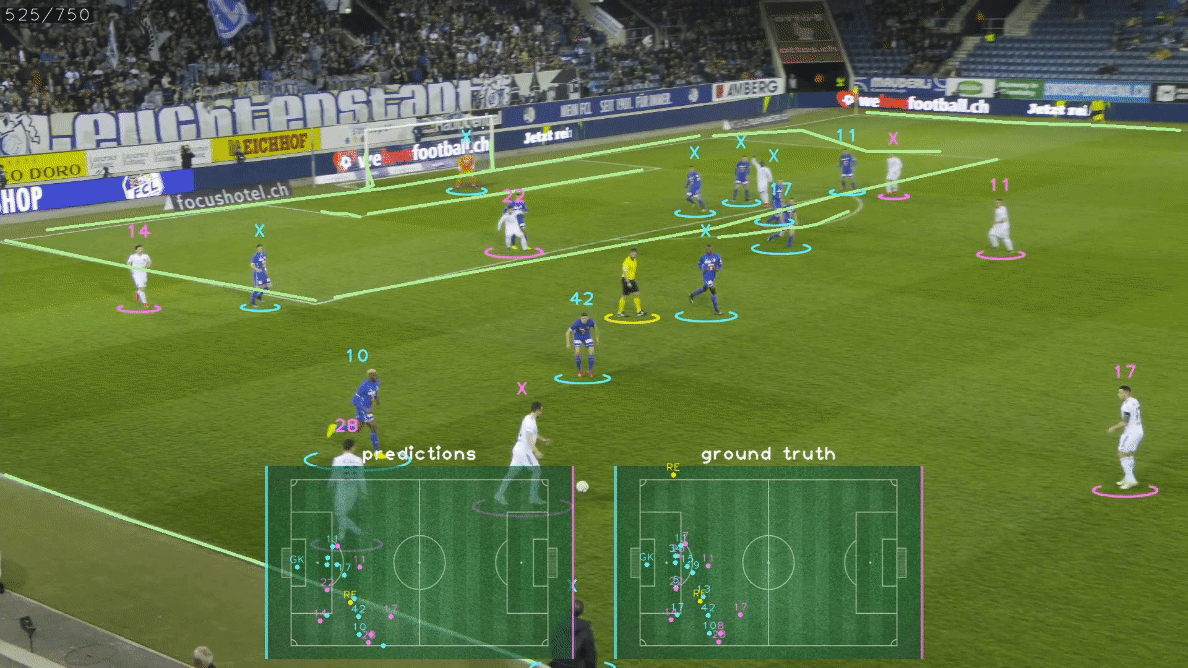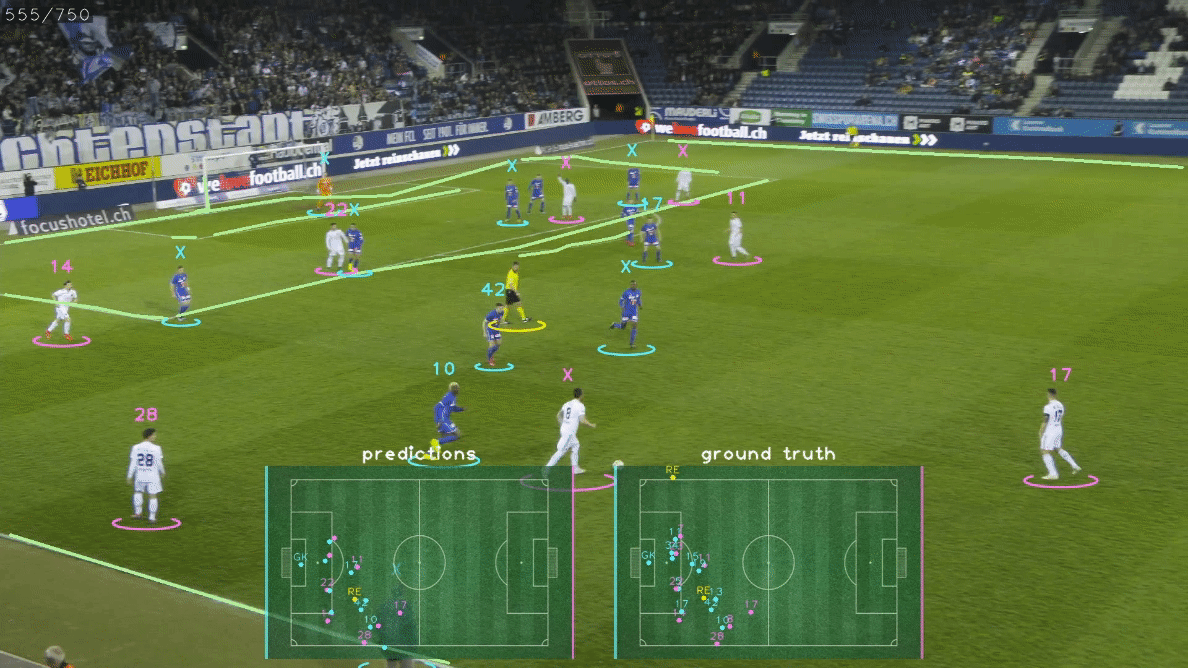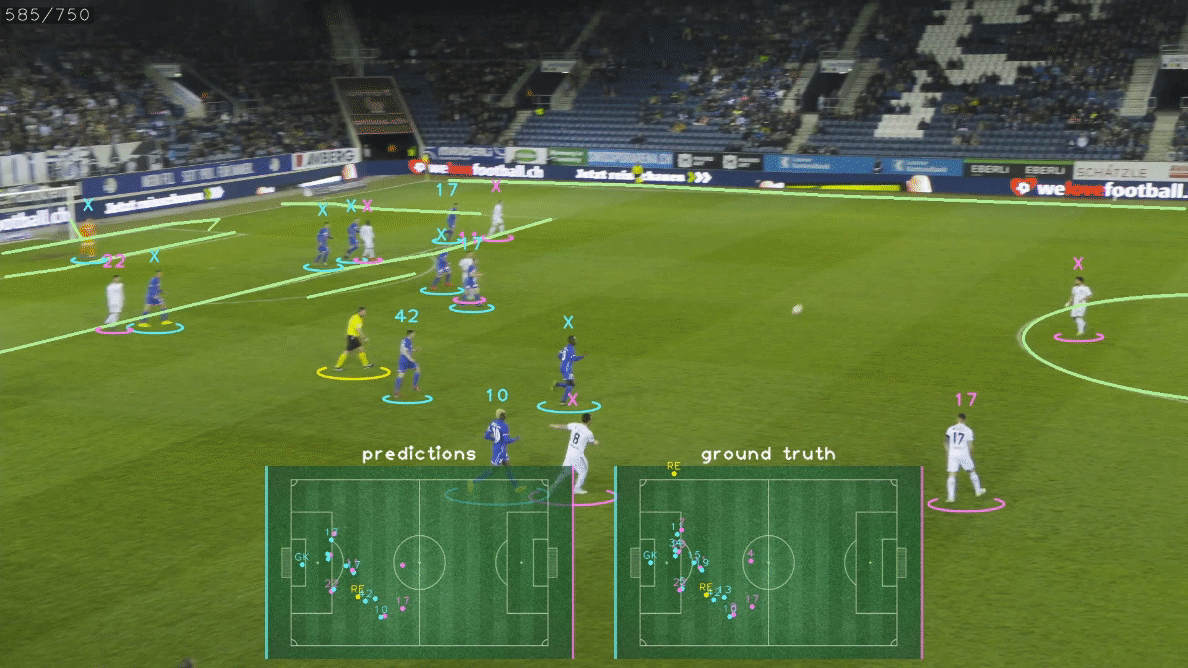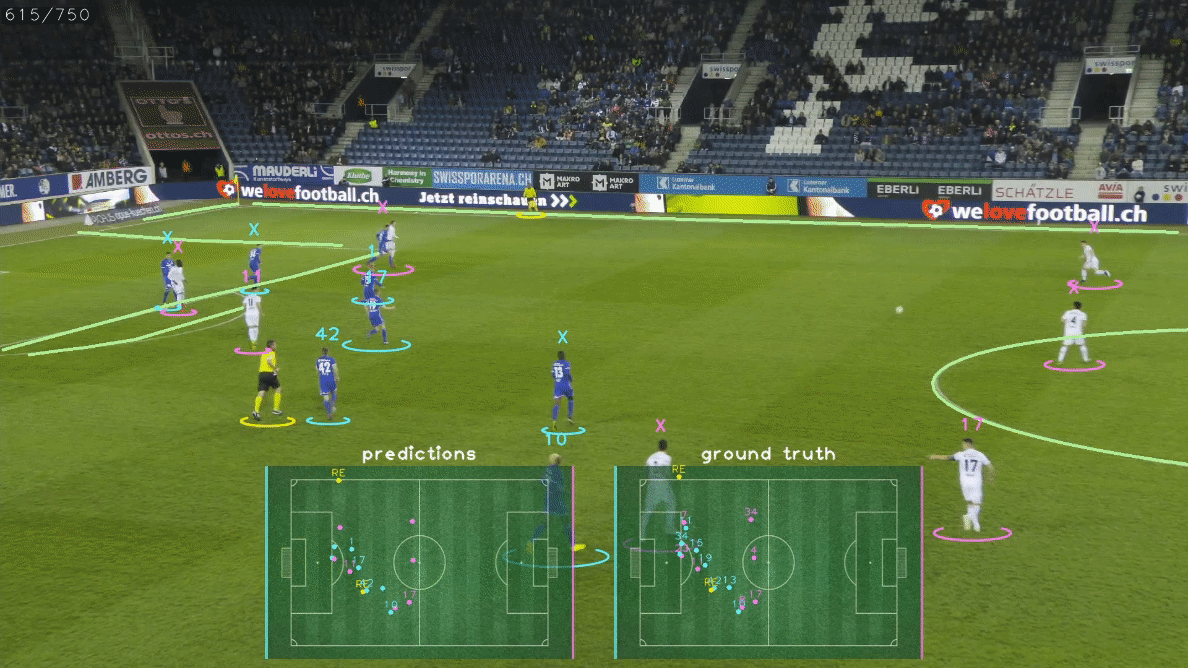
这些高级信息可以很好地显示为2D小地图、雷达视图或鸟瞰图(BEV),如上面的GIF所示。 比赛状态重建是一项具有挑战性的任务,因为它需要解决几个子任务,如:
- 球场定位和相机校准
- 人员检测、重新识别和跟踪
- 球衣号码识别
- 队伍归属
🎯 关于GS-HOTA:比赛状态重建的评估指标
GS-HOTA是一种新的评估指标,用于衡量GSR方法正确跟踪和识别体育场上所有运动员的能力。 GS-HOTA是HOTA指标的扩展,HOTA是一种流行的多目标跟踪评估指标。 为了在图像空间中匹配真实值和预测边界框,标准HOTA指标使用基于IoU的相似度分数。 GS-HOTA与HOTA的关键区别在于使用了一种新的相似度分数,考虑了GSR任务的特殊性,即额外的目标属性(球衣号码、角色、队伍)以及以2D点而非边界框形式提供的检测结果。 这个新的相似度分数,表示为$Sim_{GS-HOTA}(P, G)$,公式如下:
Sim_{\text{GS-HOTA}}(P, G) = \text{LocSim}(P, G) \times \text{IdSim}(P, G)
\text{其中 LocSim}(P, G) = e^{\ln(0.05)\frac{\|P - G\|_2^2}{\tau^2}}
\text{且 IdSim}(P, G) = \begin{cases} 1 & \text{如果所有属性匹配,} \\ 0 & \text{否则。} \end{cases}
$Sim_{\text{GS-HOTA}}$因此是两个相似度指标的组合。 第一个指标,定位相似度$\text{LocSim}(P, G)$,计算预测P和真实值G在球场坐标系中的欧几里得距离$|P - G|_2$。 随后使用高斯核处理这个距离,特殊距离容差参数$\tau$设为5米,得到最终分数落在$[0, 1]$范围内。 第二个指标,识别相似度$\text{IdSim}(P, G)$,仅当所有属性匹配时才设为1,即角色、队伍和球衣号码。 G中未提供的属性将被忽略,例如裁判的球衣号码。 因此,GSR方法必须为非球员角色输出"null"队伍和球衣号码属性,以及在视频中不可见时输出"null"球衣号码。 最后,一旦P和G�匹配,DetA和AssA将被计算并整合到最终的GS-HOTA分数中,遵循HOTA指标的原始公式。 GS-HOTA因此对预测检测结果施加了非常严格的约束,因为未能正确预测检测的所有属性会将其变成假阳性。 我们基于将定位数据分配给不正确或不存在的身份可能对下游应用产生的严重影响来证明这种严格约束的合理性。 我们建议读者参考官方论文以获取关于GS-HOTA的详细描述和讨论。
🏟️ 关于比赛状态重建基线
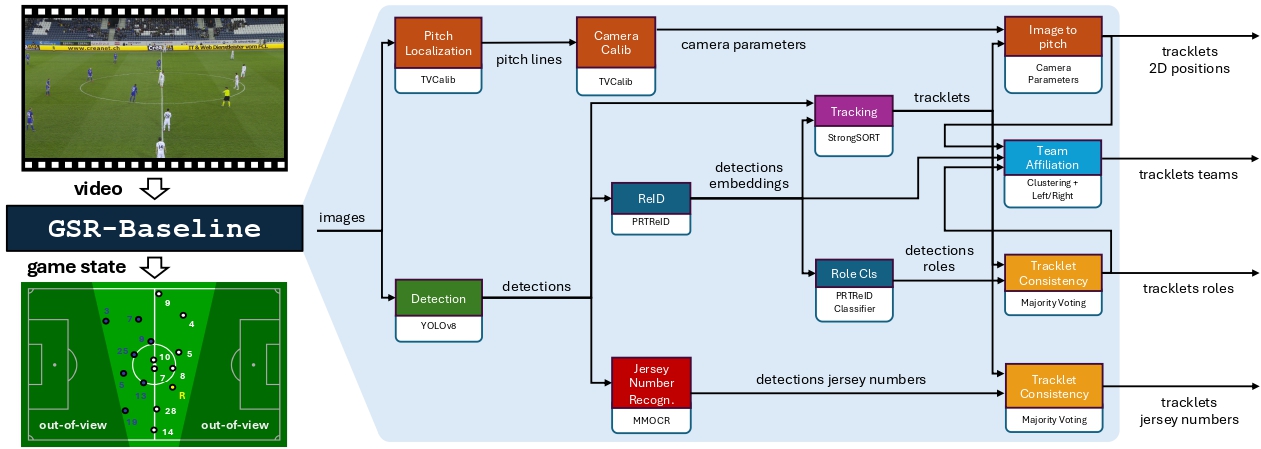
为了这个挑战的目的,我们使用TrackLab框架,这是一个开源模块化跟踪框架。 TrackLab仓库包含所有与多目标跟踪相关的通用代码(对象检测、重新识别、跟踪算法等),而sn-gamestate仓库包含特定于SoccerNet比赛状态重建任务的附加代码(球衣号码识别、队伍归属等)。 下面的图表代表了基线的完整流程。 TrackLab使得在流程中添加/定制/替换模块变得容易。 这使参与者能够专注于挑战的一个或多个特定子任务,而不必担心其他任务。 我们强烈建议参与者分析一些视频,以更好地直观了解应该改进流程的哪些部分。 我们在SoccerNet比赛状态重建论文中提供了关于基线所有组件的更多技术细节。
快速安装指南
本指南将告诉您如何安装框架、下载数据集和所有模型权重,并在验证集中的单个视频上运行基线。
Tracklab将在您当前工作目录下的output/{date}/{time}/visualization/videos/021.mp4创建一个.mp4视频,展示比赛状态重建结果。
1. 安装TrackLab和GameState基线
在首次运行基线之前,您需要克隆项目并按照下面的描述设置环境。
克隆仓库
首先在相邻目录中git克隆这个仓库和TrackLab框架:
mkdir soccernet cd soccernet git clone https://github.com/SoccerNet/sn-gamestate.git git clone https://github.com/TrackingLaboratory/tracklab.git
[!注意] 如果您使用的是集成开发环境(如PyCharm或VS Code),我们建议创建一个以
soccernet为根目录的单一项目。 操作说明:PyCharm和VS Code
选项1:使用Poetry安装
cd sn-gamestate poetry install poetry run mim install mmcv==2.0.1 poetry shell
要进入Poetry创建的虚拟环境,您可以使用poetry shell,
或者在所有命令前加上poetry run前缀。
选项2:使用conda安装
- 安装conda:https://docs.conda.io/projects/miniconda/en/latest/
- 创建新的conda环境:
conda create -n tracklab pip python=3.10 pytorch==1.13.1 torchvision==0.14.1 pytorch-cuda=11.7 -c pytorch -c nvidia -y conda activate tracklab
- 安装所有依赖��项:
cd sn-gamestate pip install -e . pip install -e ../tracklab mim install mmcv==2.0.1
更新
请务必定期查看官方GitHub以获取更新。
要将此存储库更新到最新版本,请在两个存储库上运行git pull:
git pull git -C ../tracklab pull
更新后,您应该重新运行依赖项的安装,以防它们已更新
(运行poetry install或两个pip install命令)。
我们会在soccernet discord上发布重大更新。
2. 下载数据集和基线模型权重
自动下载
当您第一次运行基线时,Tracklab将自动下载SoccerNet-gamestate数据集和所有模型权重。 如果脚本在下载完成前停止,请删除数据集文件夹并从头开始,以避免任何错误。 如果您选择此选项,可以直接进入下一步。
手动下载SoccerNet-gamestate
如果您想手动下载数据集,可以在安装soccernet包(pip install SoccerNet)后运行以下代码片段:
from SoccerNet.Downloader import SoccerNetDownloader
mySoccerNetDownloader = SoccerNetDownloader(LocalDirectory="data/SoccerNetGS")
mySoccerNetDownloader.downloadDataTask(task="gamestate-2024",
split=["train", "valid", "test", "challenge"])
运行此代码后,请解压文件夹,使数据结构如下:
data/
SoccerNetGS/
train/
valid/
test/
challenge/
您可以使用以下命令行解压它们:
cd data/SoccerNetGS unzip gamestate-2024/train.zip -d train unzip gamestate-2024/valid.zip -d valid unzip gamestate-2024/test.zip -d test unzip gamestate-2024/challenge.zip -d challenge cd ../..
更新数据集
[!重要] 当前数据集版本为v1.3。请检查 其中一个"Labels-GameState.json"文件,确保这确实是 您当前使用的版本。
您可以使用上述SoccerNet pip包手动更新数据集,或者 通过(重新)移动数据集目录并使用TrackLab的自动下载功能进行更新。
| 版本 | 更新日志 |
|---|---|
| 1.3 | 改进了边界框场地运动员位置的时间一致性 |
| 1.2 | 数据清理 |
| 1.1 | 球队左/右注释修正 |
| 1.0 | 原始发布 |
3. 在单个视频上运行基线
设置
[!注意] Tracklab使用Hydra配置库。
在运行代码之前,您需要在soccernet.yaml中设置一些变量:
data_dir:存储不同数据集的目录(必须是绝对路径!)。如果您选择了自动下载选项,data_dir应该已经指向正确的位置。- "Machine configuration"标题下的所有参数。对于相应的模块:
batch_size(如果遇到内存问题,请降低这些值)- 您可能想要更改模型超参数
命令行
最后,使用以下命令运行SoccerNet游戏状态重构基线:
python -m tracklab.main -cn soccernet
默认情况下,此命令将在一个SoccerNet验证序列上执行游戏状态重构,在保存到磁盘的.mp4视频中显示结果,并打印最终性能指标。 请记住,在首次运行时,数据集和所有模型权重将自动下载。
您可以通过运行以下命令查看所有可能的配置组:
python -m tracklab.main --help
您可以在soccernet.yaml中查看默认参数。
教程
如何开始
我们邀请用户仔细阅读以下资源:
- TrackLab README以获取有关框架的更多说明。
- soccernet.yaml以了解可用配置的更多信息。
- Hydra的教程以更好地理解如何配置TrackLab。
添加新模块
如果您想在tracklab管道中添加新模块,可以将其添加到此存储库中, 方法是在sn_gamestate中添加代码(新目录),并在 sn_gamestate/configs/modules中添加配置文件,这些文件将自动添加。
如果您想创建一个使用tracklab的独立项目,您需要使用入口点声明
配置文件的位置。入口点组应为tracklab_plugin,并应指向包含名为config_package变量的类,
如这里所示,该变量应指向配置文件夹的位置。
暂时,您也可以使用Hydra的--config-dir指定目录。
下载基线的跟踪器状态
跟踪器状态是Tracklab保存所有跟踪预测的地方,即所有检测结果及其信息,如��边界框、reid嵌入、球衣号码、跟踪ID等。 跟踪器状态可以保存到磁盘并重新加载,以节省下次运行的计算时间。 请查看使用跟踪器状态的Tracklab教程以获取更多信息。 我们在Zenodo上提供了验证集、测试集和挑战集的基线跟踪器状态。
故障排除
如果升级到最新版本后遇到问题,请记得运行poetry install或pip install -e .和pip install -e ../tracklab以保持环境更新。
如果需要进一步帮助,请随时在GitHub上提出问题或在Discord上联系我们。
常见问题
我们将尝试收集有趣的问题并在FAQ中回答。
参考文献
- 边界框检测:YOLOv8 [代码]
- 重识别:PRTReid [论文] [代码] | BPBreID [论文][代码]
- 相机标定与场地定位:TVCalib [论文] [代码]
- 球衣号码识别:MMOCR [论文] [代码]
引用
如果您在研究中使用本仓库或希望引用我们的贡献,请使用以下BibTeX条目:
@inproceedings{Somers2024SoccerNetGameState,
title = {{SoccerNet} Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap},
author = {Somers, Vladimir and Joos, Victor and Giancola, Silvio and Cioppa, Anthony and Ghasemzadeh, Seyed Abolfazl and Magera, Floriane and Standaert, Baptiste and Mansourian, Amir Mohammad and Zhou, Xin and Kasaei, Shohreh and Ghanem, Bernard and Alahi, Alexandre and Van Droogenbroeck, Marc and De Vleeschouwer, Christophe},
booktitle = cvsports,
shortjournalproceedings = {2024 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Work. (CVPRW)},
month = Jun,
year = {2024},
address = city-seattle,
}
@misc{Joos2024Tracklab,
title = {{TrackLab}},
author = {Joos, Victor and Somers, Vladimir and Standaert, Baptiste},
journal = {GitHub repository},
year = {2024},
howpublished = {\url{https://github.com/TrackingLaboratory/tracklab}}
}
@inproceedings{Mansourian2023Multitask,
title = {Multi-task Learning for Joint Re-identification, Team Affiliation, and Role Classification for Sports Visual Tracking},
author = {Mansourian, Amir M. and Somers, Vladimir and De Vleeschouwer, Christophe and Kasaei, Shohreh},
booktitle = mmsports,
shortjournalproceedings = {Proc. 6th Int. Work. Multimedia Content Anal. Sports},
pages = {103–112},
month = Oct,
year = {2023},
publisher = {ACM},
address = city-ottawa,
doi = {10.1145/3606038.3616172},
url = {https://doi.org/10.1145/3606038.3616172}
}
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号