
sam-hq
升级版零样本图像分割模型
SAM-HQ是对原始SAM模型的改进版本,专注于提高零样本图像分割的质量。该模型保留了SAM的灵活提示和泛化能力,同时通过引入可学习的高质量输出标记和特征融合策略,显著提升了分割效果,特别是对于复杂结构的物体。SAM-HQ仅增加少量参数就实现了性能的大幅提升。在9个不同领域的数据集测试中,SAM-HQ在各类下游任务中均表现优于原始SAM模型。



高质量的全能分割
![]() <a href="https://colab.research.google.com/drive/1QwAbn5hsdqKOD5niuBzuqQX4eLCbNKFL?usp=sharing"><img src="https://yellow-cdn.veclightyear.com/835a84d5/c4d4d9bb-73a2-437a-8f4f-49a40052254e.svg" alt="在Colab中打开"></a>
<a href="https://colab.research.google.com/drive/1QwAbn5hsdqKOD5niuBzuqQX4eLCbNKFL?usp=sharing"><img src="https://yellow-cdn.veclightyear.com/835a84d5/c4d4d9bb-73a2-437a-8f4f-49a40052254e.svg" alt="在Colab中打开"></a>

高质量的全能分割
NeurIPS 2023
苏黎世联邦理工学院 & 香港科技大学
我们提出HQ-SAM来升级SAM,实现高质量的零样本分割。更多详情请参考我们的论文。
更新
:fire::fire: SAM用于视频分割:对SAM和视频的结合感兴趣吗?HQ-SAM在文本提示模式下得到了DEVA的支持!另外,也可以查看使用SAM的MASA和SAM-PT工作。
:fire::fire: 3D中的SAM:对SAM和3D高斯喷溅的结��合感兴趣吗?请看我们的新工作高斯分组!此外,如果你对SAM和NeRF的结合感兴趣,请查看SANeRF-HQ工作!
更多:HQ-SAM被Osprey、CaR、SpatialRGPT采用,以提供细粒度的掩码标注。
2023/11/06:HQ-SAM被用于标注GLaMM提出的Grounding-anything数据集。
2023/10/15:HQ-SAM在OpenMMLab PlayGround中得到支持,可与Label-Studio一起用于标注。
2023/09/28:HQ-SAM被用于ENIGMA-51中标注自我中心视角的工业数据,并在论文中与SAM进行了比较。
2023/08/16:HQ-SAM被用于segment-geospatial以分割地理空间数据,以及掩码标注工具ISAT!
2023/08/11:支持Python包,便于pip安装。
2023/07/25:轻量级HQ-SAM与Grounded SAM结合,加入EfficientSAM系列!
2023/07/21:HQ-SAM也加入了OpenXLab应用,感谢他们的支持!
:rocket::rocket: 2023/07/17:我们发布了使用TinyViT作为骨干网络的轻量级HQ-SAM,用于快速且高质量的零样本分割,达到了41.2 FPS。更多详情请参考轻��量级HQ-SAM与MobileSAM的比较。
:trophy::1st_place_medal: 2023/07/14:Grounded HQ-SAM在野外分割竞赛的零样本赛道中获得第一名:1st_place_medal:(在CVPR 2023工作坊举办),超越了Grounded SAM。更多详情请参考我们的SGinW评估。
2023/07/05:我们发布了SAM调优说明和HQSeg-44K数据。
2023/07/04:HQ-SAM被SAM-PT采用,以提高基于SAM的零样本视频分割性能。此外,HQ-SAM还被用于Grounded-SAM、Inpaint Anything和HQTrack(在VOTS 2023中排名第二)。
2023/06/28:我们发布了ONNX导出脚本和colab笔记本,用于导出和使用ONNX模型。
2023/06/23:在体验HQ-SAM演示,支持点、框和文本提示。
2023/06/14:我们发布了colab演示 <a href="https://colab.research.google.com/drive/1QwAbn5hsdqKOD5niuBzuqQX4eLCbNKFL?usp=sharing"><img src="https://yellow-cdn.veclightyear.com/835a84d5/c4d4d9bb-73a2-437a-8f4f-49a40052254e.svg" alt="在Colab中打开"></a>和自动掩码生成器笔记本。
2023/06/13:我们发布了模型检查点和演示可视化代码。 SAM和HQ-SAM的视觉对比
SAM vs. HQ-SAM
<table> <tr> <td><img src="https://yellow-cdn.veclightyear.com/835a84d5/c28db034-cb6f-4bec-928c-78e88dd6cef8.gif" width="250"></td> <td><img src="https://yellow-cdn.veclightyear.com/835a84d5/8f2ef0f8-8250-4ea7-aa1d-8ee83602ce5a.gif" width="250"></td> <td><img src="https://yellow-cdn.veclightyear.com/835a84d5/6be16920-744a-4d2c-9b72-be1a567ecdf2.gif" width="250"></td> </tr> <tr> <td><img src="https://yellow-cdn.veclightyear.com/835a84d5/ff4e9862-d997-4714-8098-07970db1e648.gif" width="250"></td> <td><img src="https://yellow-cdn.veclightyear.com/835a84d5/7aeb9dd1-08cc-4f11-a263-f0111e917da4.gif" width="250"></td> <td><img src="https://yellow-cdn.veclightyear.com/835a84d5/f1133fff-66f7-4580-8c2a-d31fbf7e86ed.gif" width="250"></td> </tr> </table> <img width="900" alt="image" src='https://yellow-cdn.veclightyear.com/835a84d5/f5e47ad0-d142-43c1-8410-e3498b7f26e7.png'>简介
最近提出的Segment Anything Model (SAM)在扩展分割模型方面取得了重大突破,具备强大的零样本能力和灵活的提示功能。尽管SAM经过了11亿个掩码的训练,但在许多情况下,特别是在处理结构复杂的对象时,其掩码预测质量仍有不足。我们提出了HQ-SAM,赋予SAM准确分割任何对象的能力,同时保持SAM原有的可提示设计、效率和零样本泛化能力。我们的精心设计重用并保留了SAM的预训练模型权重,仅引入了少量额外参数和计算。我们设计了一个可学习的高质量输出令牌,将其注入SAM的掩码解码器中,负责预测高质量掩码。我们不仅将其应用于掩码解码器特征,还首先将其与早期和最终的ViT特征融合,以改善掩码细节。为了训练我们引入的可学习参数,我们从多个来源组合了一个包含44K个精细掩码的数据集。HQ-SAM仅在这44K个掩码的引入数据集上进行训练,在8个GPU上只需4小时。我们在9个不同的分割数据集上展示了HQ-SAM在各种下游任务中的有效性,其中7个数据集采用零样本迁移协议进行评估。
<img width="1096" alt="image" src='https://yellow-cdn.veclightyear.com/835a84d5/797f9642-c901-46c8-8f86-dd3d612e3074.png'>SAM和HQ-SAM的定量对比
注:对于基于框提示的评估,我们使用相同的图像/视频边界框输入SAM、MobileSAM和我们的HQ-SAM,并采用SAM的单掩码输出模式。
我们提供了SAM变体的全面性能、模型大小和速度比较: <img width="1096" alt="image" src='https://yellow-cdn.veclightyear.com/835a84d5/8f7820e5-374e-4880-804c-bc9b1ed92b6c.png'>
COCO数据集上的各种ViT��骨干网络:
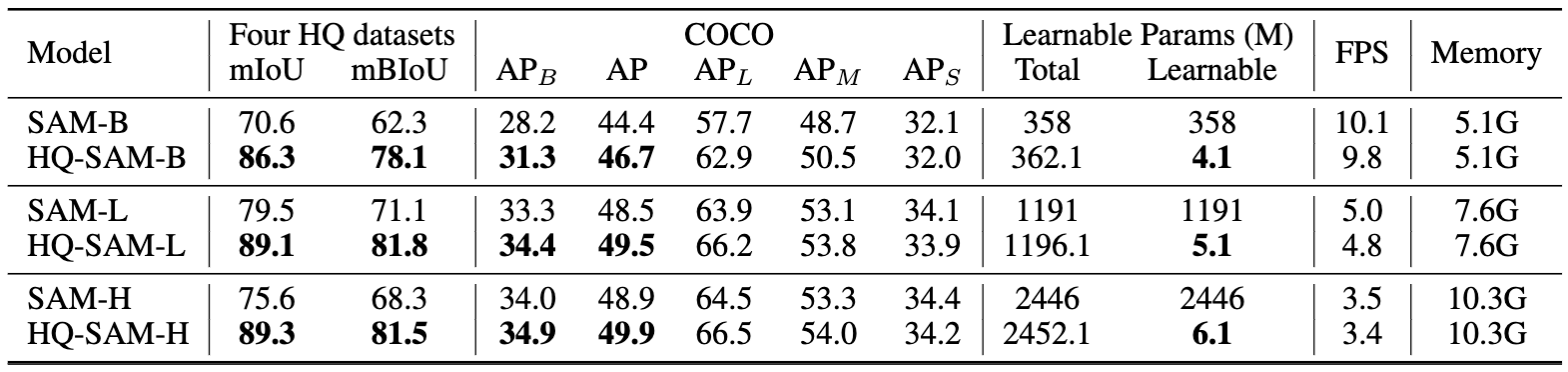 注:对于COCO数据集,我们使用在COCO数据集上训练的最先进检测器FocalNet-DINO作为我们的框提示生成器。
注:对于COCO数据集,我们使用在COCO数据集上训练的最先进检测器FocalNet-DINO作为我们的框提示生成器。
YTVIS和HQ-YTVIS
注:使用ViT-L骨干网络。我们采用在YouTubeVIS 2019数据集上训练的最先进检测器Mask2Former作为视频框提示生成器,同时重用其对象关联预测。

DAVIS
注:使用ViT-L骨干网络。我们采用最先进的模型XMem作为视频框提示生成器,同时重用其对象关联预测。

通过pip快速安装
pip install segment-anything-hq
python
from segment_anything_hq import sam_model_registry
model_type = "<model_type>" #"vit_l/vit_b/vit_h/vit_tiny"
sam_checkpoint = "<path/to/checkpoint>"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
通过运行以下命令查看具体使用示例(如vit-l):
export PYTHONPATH=$(pwd)
python demo/demo_hqsam_pip_example.py
标准安装
代码要求python>=3.8,以及pytorch>=1.7和torchvision>=0.8。请按照此处的说明安装PyTorch和TorchVision依赖项。强烈建议安装支持CUDA的PyTorch和TorchVision。
在本地克隆仓库并安装:
git clone https://github.com/SysCV/sam-hq.git
cd sam-hq; pip install -e .
以下可选依赖项对于掩码后处理、以COCO格式保存掩码、示例笔记本和以ONNX格式导出模型是必需的。运行示例笔记本还需要jupyter。
pip install opencv-python pycocotools matplotlib onnxruntime onnx timm
示例conda环境设置
conda create --name sam_hq python=3.8 -y conda activate sam_hq conda install pytorch==1.10.0 torchvision==0.11.0 cudatoolkit=11.1 -c pytorch -c nvidia pip install opencv-python pycocotools matplotlib onnxruntime onnx timm # 在你的工作目录下 git clone https://github.com/SysCV/sam-hq.git cd sam-hq pip install -e . export PYTHONPATH=$(pwd)
模型检查点
提供了三个版本的HQ-SAM模型,具有不同的骨干网络大小。可以通过运行以下代码实例化这些模型:
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
下载提供的训练模型并将它们放入pretrained_checkpoint文件夹:
mkdir pretrained_checkpoint
点击下面的链接下载相应模型类型的检查点。我们还在此处或hugging face提供了替代模型下载链接。
vit_b: ViT-B HQ-SAM模型。vit_l: ViT-L HQ-SAM模型。vit_h: ViT-H HQ-SAM模型。vit_tiny(轻量级HQ-SAM,用于实时需求): ViT-Tiny HQ-SAM模型。
入门
首先下载一个模型检查点。然后只需几行代码就可以使用模型从给定的提示中获取掩码:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
此外,请参阅我们的演示、Colab笔记本和自动掩码生成器笔记本中的使用示例。
要获取HQ-SAM的可视化结果:
python demo/demo_hqsam.py
要获取基线SAM的可视化结果。注意,你需要从基线SAM-L模型下载原始SAM检查点并将其放入pretrained_checkpoint文件夹中。
python demo/demo_sam.py
要获取Light HQ-SAM的可视化结果:
python demo/demo_hqsam_light.py
HQ-SAM调优和HQ-Seg44k数据
我们在HQ-SAM训练中提供了详细的训练、评估、可视化和数据下载说明。你也可以替换我们的训练数据,以在特定应用领域(如医疗、OCR和遥感)获得你自己的SAM。
请将当前文件夹路径更改为:
cd train
然后参考详细的readme说明。
Grounded HQ-SAM与Grounded SAM在SegInW上的比较
Grounded HQ-SAM在SegInW基准测试(包含25个公共零样本野外分割数据集)中获得第一名:1st_place_medal:,并使用相同的grounding-dino检测器优于Grounded SAM。
<table><tbody> <!-- START TABLE --> <!-- TABLE HEADER --> <th valign="bottom">模型名称</th> <th valign="bottom">编码器</th> <th valign="bottom">GroundingDINO</th> <th valign="bottom">平均AP</th> <th valign="bottom">评估脚本</th> <th valign="bottom">日志</th> <th valign="bottom">输出Json</th> <!-- TABLE BODY --> <!-- ROW: maskformer2_R50_bs16_50ep --> <tr><td align="left">Grounded SAM</td> <td align="center">vit-h</td> <td align="center">swin-b</td> <td align="center">48.7</td> <td align="center"><a href="seginw/test_seginw.sh">脚本</a></td> <td align="center"><a href="seginw/logs/grounded_sam.log">日志</a></td> <td align="center"><a href="https://huggingface.co/sam-hq-team/SegInW/resolve/main/result/grounded_sam.zip">结果</a></td> </tr> <!-- ROW: maskformer2_R101_bs16_50ep --> <tr><td align="left">Grounded HQ-SAM</td> <td align="center">vit-h</td> <td align="center">swin-b</td> <td align="center"><b>49.6</b></td> <td align="center"><a href="seginw/test_seginw_hq.sh">脚本</a></td> <td align="center"><a href="seginw/logs/grounded_hqsam.log">日志</a></td> <td align="center"><a href="https://huggingface.co/sam-hq-team/SegInW/resolve/main/result/grounded_hqsam.zip">结果</a></td> </tr> </tbody></table>请将当前文件夹路径更改为:
cd seginw
我们在Grounded-HQ-SAM评估中提供了SegInW上的详细评估说明和指标。
Light HQ-SAM与MobileSAM在COCO上的比较
我们基于MobileSAM提供的tiny vit图像编码器提出了Light HQ-SAM。我们在下面提供了零样本COCO性能、速度和内存的定量比较。在这里尝试Light HQ-SAM。
<table><tbody> <!-- START TABLE --> <!-- TABLE HEADER --> <th valign="bottom">模型</th> <th valign="bottom">编码器</th> <th valign="bottom">AP</th> <th valign="bottom">AP@L</th> <th valign="bottom">AP@M</th> <th valign="bottom">AP@S</th> <th valign="bottom">模型参数 (MB)</th> <th valign="bottom">FPS</th> <th valign="bottom">内存 (GB)</th> <!-- TABLE BODY --> <!-- ROW: maskformer2_R50_bs16_50ep --> <tr><td align="left">MobileSAM</td> <td align="center">TinyViT</td> <td align="center">44.3</td> <td align="center">61.8</td> <td align="center">48.1</td> <td align="center">28.8</td> <td align="center">38.6</td> <td align="center">44.8</td> <td align="center">3.7</td> </tr> <!-- ROW: maskformer2_R101_bs16_50ep --> <tr><td align="left"><b>Light HQ-SAM</b></td> <td align="center">TinyViT</td> <td align="center"><b>45.0</b></td> <td align="center">62.8</td> <td align="center">48.8</td> <td align="center">29.2</td> <td align="center">40.3</td> <td align="center">41.2</td> <td align="center">3.7</td> </tr> </tbody></table>注意:对于COCO数据集,我们使用在COCO数据集上训练的相同的SOTA检测器FocalNet-DINO作为我们和Mobile sam的边界框提示生成器。
ONNX导出
HQ-SAM的轻量级掩码解码器可以导出为ONNX格式,以便在支持ONNX运行时的任何环境中运行。使用以下命令导出模型:
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
查看示例笔记本,了解如何将HQ-SAM的backbone进行图像预处理与使用ONNX模型进行掩码预测相结合的详细信息。建议使用最新的稳定版PyTorch进行ONNX导出。
引用
如果你在研究中发现HQ-SAM有用或参考了提供的基线结果,请为这个仓库加星 :star: 并考虑引用 :pencil::
@inproceedings{sam_hq,
title={Segment Anything in High Quality},
author={Ke, Lei and Ye, Mingqiao and Danelljan, Martin and Liu, Yifan and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
booktitle={NeurIPS},
year={2023}
}
相关的高质量实例分割工作:
@inproceedings{transfiner,
title={Mask Transfiner for High-Quality Instance Segmentation},
author={Ke, Lei and Danelljan, Martin and Li, Xia and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
booktitle={CVPR},
year={2022}
}
致谢
- 感谢SAM、Grounded SAM和MobileSAM提供的公开代码和发布的模型。
编辑推荐精选


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。


TRELLIS
用于可扩展和多功能 3D 生成的结构化 3D 潜在表示
TRELLIS 是一个专注于 3D 生成的项目,它利用结构化 3D 潜在表示技术,实现了可扩展且多功能的 3D 生成。项目提供了多种 3D 生成的方法和工具,包括文本到 3D、图像到 3D 等,并且支持多种输出格式,如 3D 高斯、辐射场和网格等。通过 TRELLIS,用户可以根据文本描述或图像输入快速生成高质量的 3D 资产,适用于游戏开发、动画制作、虚拟现实等多个领域。


ai-agents-for-beginners
10 节课教你开启构建 AI 代理所需的一切知识
AI Agents for Beginners 是一个专为初学者打造的课程项目,提供 10 节课程,涵盖构建 AI 代理的必备知识,支持多种语言,包含规划设计、工具使用、多代理等丰富内容,助您快速入门 AI 代理领域。


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,��爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号