
ComfyUI-Anyline
基于TEED技术的高精度线条检测预处理器
ComfyUI-Anyline是基于TEED技术的ControlNet线条预处理器,可从各类图像中提取物体边缘、细节和文本内容。它能快速生成清晰边缘和高保真度的线条图,用于Stable Diffusion的条件生成输入。Anyline在轮廓准确性、细节保留和文字识别方面表现优异,有效减少噪声。结合MistoLine ControlNet模型,Anyline能在SDXL工作流中实现精确控制和强大的生成能力。



Anyline
快速、准确且详细的线条检测预处理器

Anyline是一个ControlNet线条预处理器,能够准确地从大多数图像中提取物体边缘、图像细节和文本内容。用户可以输入任何类型的图像,快速获得边缘清晰、细节保留充分、文本高保真度的线条图,然后将其用作Stable Diffusion中条件生成的输入。
技术细节
Anyline使用的模型和算法基于"小型高效边缘检测泛化模型(TEED)"论文(arXiv:2308.06468)的创新成果。ComfyUI中的TEED预设也源于这项工作,标志着它是一种强大的视觉算法(TEED目前是最先进的)。更多详情请参阅该论文。
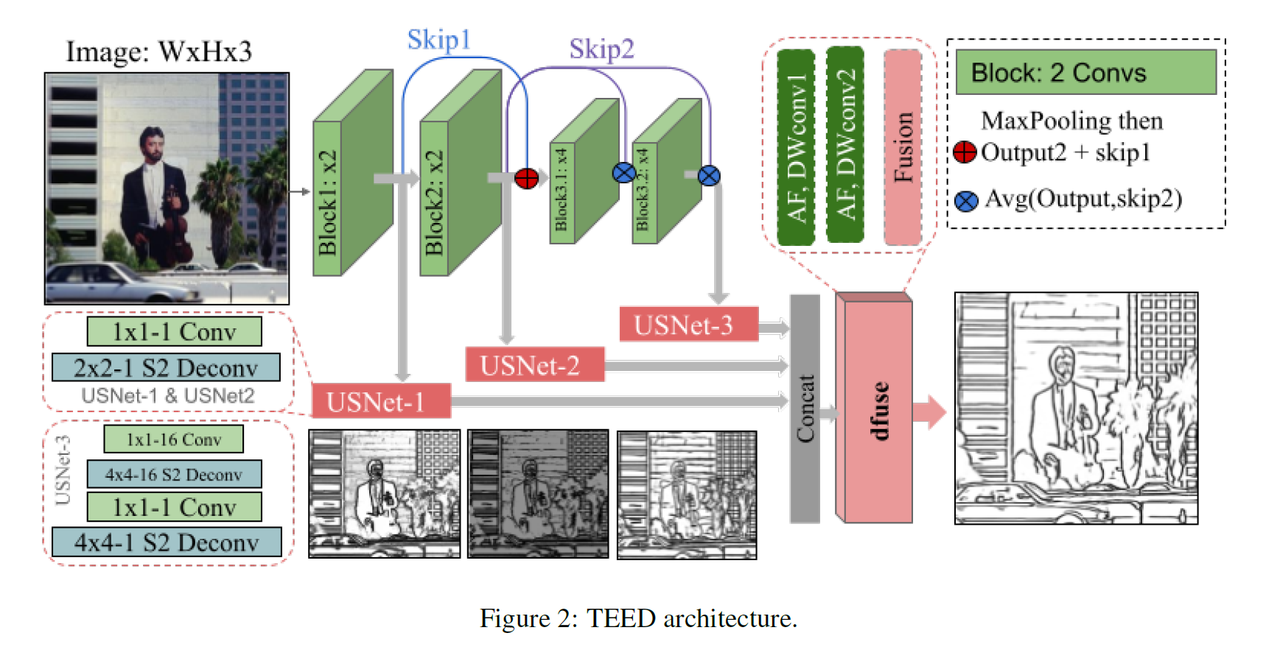
与其他线条提取预处理器的比较
Anyline使用1280px的处理分辨率,因此比较也在这个分辨率下进行。与其他常用的线条预处理器相比,Anyline在轮廓准确性、物体细节、材质纹理和字体识别(尤其是在大场景中)方面具有显著优势。它还在大多数场景中更好地减少噪音,从而在生成过程中产生更清晰的图像处理,减少不准确之处。

效果概览
Anyline与Mistoline ControlNet模型结合,形成了一个完整的SDXL工作流程,最大化精确控制并发挥SDXL模型的生成能力。Anyline也可以在SD1.5工作流程中与SD1.5的ControlNet一起使用,尽管它在SDXL工作流程中的Anyline+MistoLine设置中通常表现更好。

注意:最�终结果高度依赖于所使用的基础模型。请根据您的需求选择适当的基础模型。
视频教程
即将推出!
安装
要将Anyline作为ComfyUI插件使用,您需要先安装comfyui_controlnet_aux!您可以按照以下说明进行操作:https://github.com/Fannovel16/comfyui_controlnet_aux?tab=readme-ov-file#installation
安装完comfyui_controlnet_aux后,请按照以下步骤操作:
- 打开您的IDE和ComfyUI命令行,确保Python环境匹配。
- 导航到自定义节点目录:
cd custom_nodes - 克隆仓库,或手动下载此仓库并将其放入ComfyUI/custom_nodes目录:
git clone https://github.com/TheMistoAI/ComfyUI-Anyline.git - 导航到克隆的目录:
cd ComfyUI-Anyline - 安装依赖项:
pip install -r requirements.txt - 首次使用时模型将自动下载。如果失败,请从HuggingFace仓库手动下载,并将.pth文件放在指定目录中。
ComfyUI工作流程
安装完成后,可以通过搜索或右键点击在ComfyUI中访问Anyline预处理器。在SDXL中使用Anyline+Mistoline的标准工作流程如下:
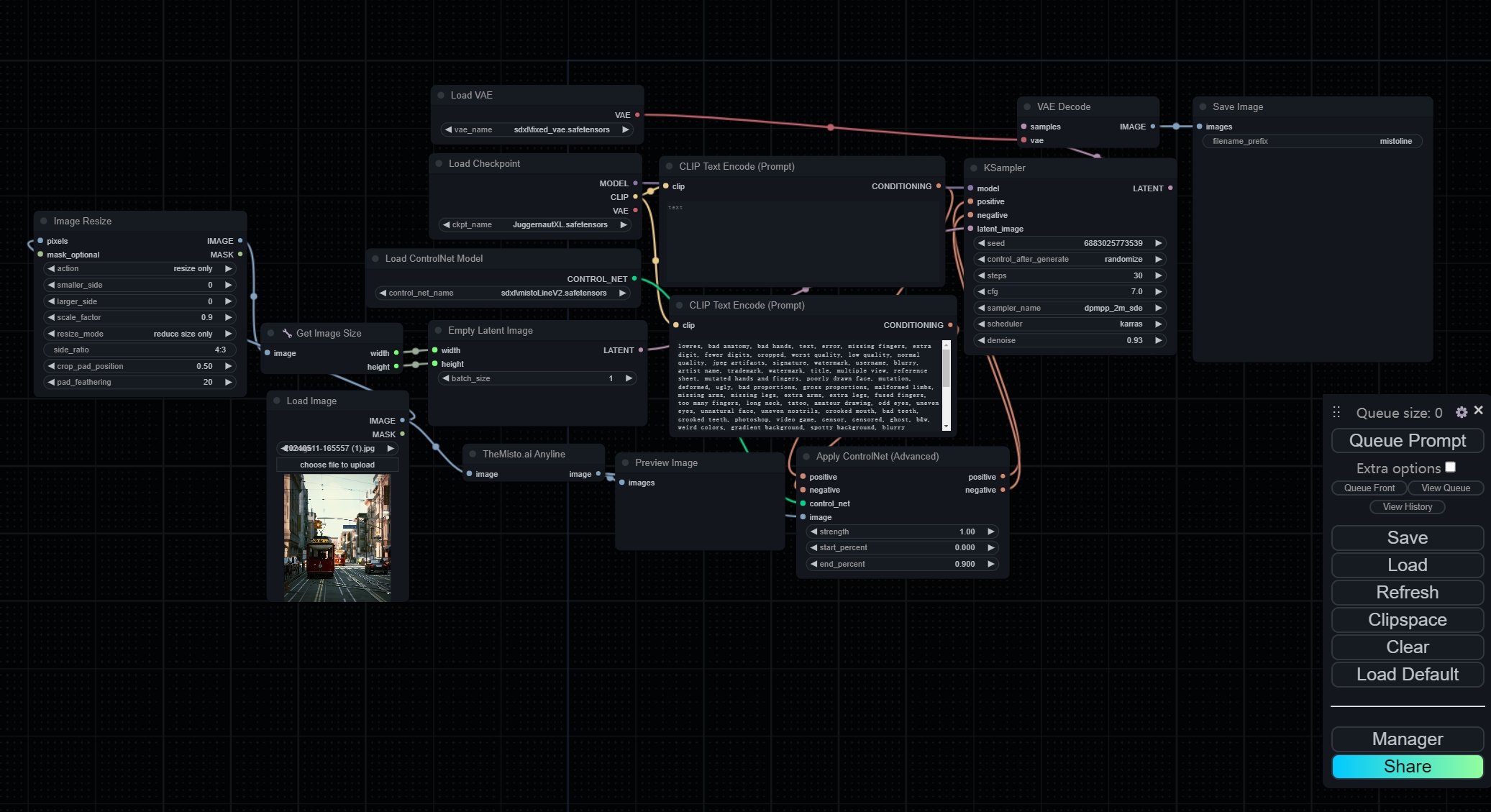
您可以在这里下载此工作流程JSON:ComfyUI工作流程
在A1111 sd-webui-controlnet中使用
请按照https://github.com/Mikubill/sd-webui-controlnet/discussions/2907中的说明操作。
局限性和未来发展
- Anyline可能在处理具有相机模糊或柔焦效果的图像时遇到困难,可能需要根据社区反馈进行迭代改进。
- 我们还计划联系ComfyUI的作者或ComfyUI-Controlnet的开发者,将Anyline集成到ComfyUI中,以便未来更易使用。
中国(大陆地区)便捷下载地址 (MTEED.pth):
链接:https://pan.baidu.com/s/1ik11P_u1vK8mI4q33v0MTQ?pwd=v8f1
提取码:v8f1
引用
@InProceedings{Soria_2023teed, author = {Soria, Xavier and Li, Yachuan and Rouhani, Mohammad and Sappa, Angel D.}, title = {Tiny and Efficient Model for the Edge Detection Generalization}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, month = {October}, year = {2023}, pages = {1364-1373} }
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号