
Segment-Everything-Everywhere-All-At-Once
基于多模态提示的图像分割模型
SEEM是一种新型图像分割模型,支持多种交互方式如点击、框选、涂鸦、文本和音频提示。该模型可接受任意组合的提示输入,精确分割图像中的目标对象并赋予语义标签。SEEM采用统一架构,具备多模态交互、语义理解和泛化能力,为图像分割任务提供了灵活通用的解决方案。





👀SEEM: 一次性分割一切事物
:grapes: [阅读我们的arXiv论文] :apple: [体验我们的演示]
我们介绍了SEEM,它可以使用多模态提示一次性Segment Everything Everywhere with Multi-modal prompts(分割任何地方的任何事物)。SEEM允许用户使用不同类型的提示轻松分割图像,包括视觉提示(点、标记、框、涂鸦和图像分割)和语言提示(文本和音频)等。它还可以与任何组合的提示一起使用,或扩展到自定义提示!
作者:Xueyan Zou*、Jianwei Yang*、Hao Zhang*、Feng Li*、Linjie Li、Jianfeng Wang、Lijuan Wang、Jianfeng Gao^、Yong Jae Lee^,发表于 NeurIPS 2023。
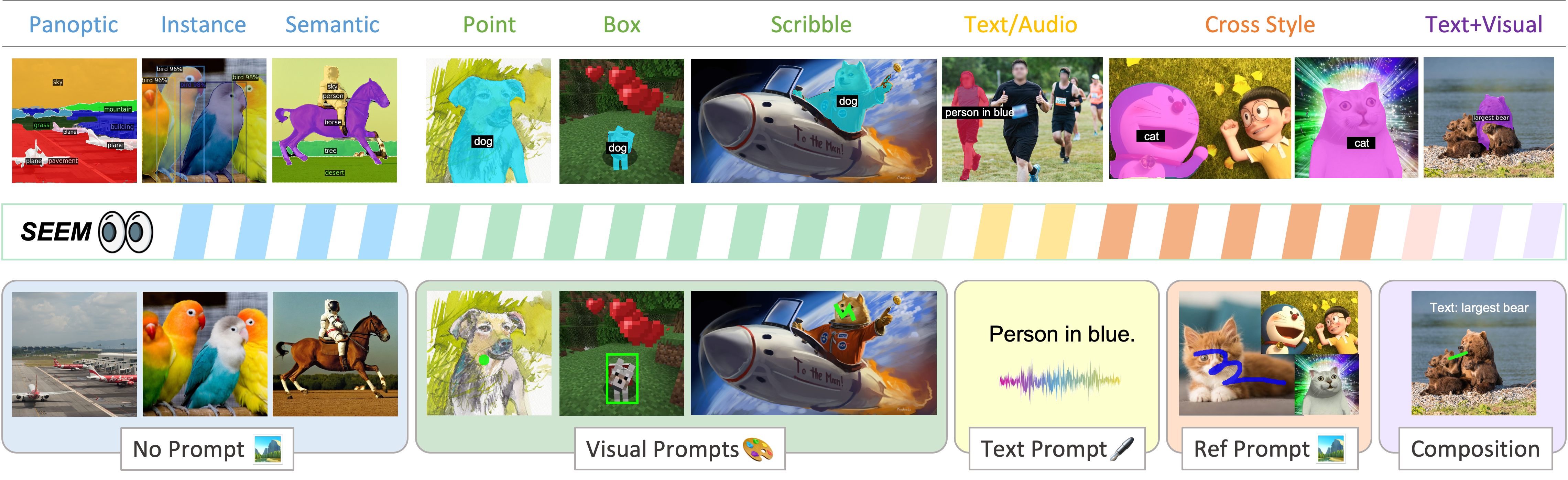
简要介绍我们可以执行的所有通用和交互式分割任务!
:rocket: 更新
- [2023.11.2] SEEM应用于LLaVA-Interactive:一个集图像聊天、分割、生成和编辑于一体的演示。通过视觉聊天体验未来的交互式图像编辑。 [项目页面] [演示] [代码] [论文]
- [2023.10.23] SEEM用于Set-of-Mark Prompting:GPT-4V的全新视觉提示技术!它完全释放了GPT-4V非凡的视觉定位能力! [项目页面] [代码] [论文]
- [2023.10.10] 我们发布了SEEM-Large-v1的训练日志和SEEM-Tiny-v1的日志!
- [2023.10.04] 我们很高兴发布 :white_check_mark: 训练/评估/演示代码、:white_check_mark: 新的检查点和 :white_check_mark: 全面的说明文档,适用于X-Decoder和SEEM!
- [2023.09.25] 我们的工作已被NeurIPS 2023接受!
- [2023.07.27] 我们很高兴发布X-Decoder训练代码!我们将很快发布其衍生的SEEM训练代码!
- [2023.07.10] 我们发布了Semantic-SAM,一个通用图像分割模型,能够以任何所需的粒度分割和识别任何物体。代码和检查点已可用!
- [2023.05.02] 我们发布了SEEM Focal-L和X-Decoder Focal-L检查点以及配置文件!
- [2023.04.28] 我们更新了ArXiv,展示了比SAM更好的交互式分割结果,而SAM的训练数据量是我们的50倍!
- [2023.04.26] 我们发布了演示代码和SEEM-Tiny检查点!请尝试一键启动!
- [2023.04.20] SEEM指代视频分割已发布!请尝试视频演示并查看NERF示例。
:bookmark_tabs: 目录
我们为SEEM和X-Decoder发布以下内容:exclamation:
- 演示代码
- 模型检查点
- 全面的用户指南
- 训练代码
- 评估代码
:point_right: Linux下的一键SEEM演示:
git clone git@github.com:UX-Decoder/Segment-Everything-Everywhere-All-At-Once.git && sh assets/scripts/run_demo.sh
:round_pushpin: [新] 入门指南:
- INSTALL.md <br>
- DATASET.md <br>
- TRAIN.md <br>
- EVAL.md :round_pushpin: [新] 最新检查点和数据: | | | | COCO | | | Ref-COCOg | | | VOC | | SBD | | |-----------------|---------------------------------------------------------------------------------------------|------------|------|------|------|-----------|------|------|-------|-------|-------|-------| | 方法 | 检查点 | 骨干网络 | PQ ↑ | mAP ↑ | mIoU ↑ | cIoU ↑ | mIoU ↑ | AP50 ↑ | NoC85 ↓ | NoC90 ↓| NoC85 ↓| NoC90 ↓| | X-Decoder | ckpt | Focal-T | 50.8 | 39.5 | 62.4 | 57.6 | 63.2 | 71.6 | - | - | - | - | | X-Decoder-oq201 | ckpt | Focal-L | 56.5 | 46.7 | 67.2 | 62.8 | 67.5 | 76.3 | - | - | - | - | | SEEM_v0 | ckpt | Focal-T | 50.6 | 39.4 | 60.9 | 58.5 | 63.5 | 71.6 | 3.54 | 4.59 | * | * | | SEEM_v0 | - | Davit-d3 | 56.2 | 46.8 | 65.3 | 63.2 | 68.3 | 76.6 | 2.99 | 3.89 | 5.93 | 9.23 | | SEEM_v0 | ckpt | Focal-L | 56.2 | 46.4 | 65.5 | 62.8 | 67.7 | 76.2 | 3.04 | 3.85 | * | * | | SEEM_v1 | ckpt | SAM-ViT-B | 52.0 | 43.5 | 60.2 | 54.1 | 62.2 | 69.3 | 2.53 | 3.23 | * | * | | SEEM_v1 | ckpt | SAM-ViT-L | 49.0 | 41.6 | 58.2 | 53.8 | 62.2 | 69.5 | 2.40 | 2.96 | * | * | | SEEM_v1 | ckpt/log | Focal-T | 50.8 | 39.4 | 60.7 | 58.5 | 63.7 | 72.0 | 3.19 | 4.13 | * | * | | SEEM_v1 | ckpt/log | Focal-L | 56.1 | 46.3 | 65.8 | 62.4 | 67.8 | 76.0 | 2.66 | 3.44 | * | * |
SEEM_v0: 支持单一交互对象的训练和推理 SEEM_v1: 支持多个交互对象的训练和推理
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/78551c4e-d96b-4a3c-83fb-ef604a2011b5.gif" width="400" /> <img src="https://yellow-cdn.veclightyear.com/835a84d5/252f56e7-be64-41da-b7a0-7d24fd1f40a1.gif" width="400" /> </div>:fire: 相关项目:
- FocalNet 和 DaViT:我们使用FocalNet和DaViT作为视觉骨干网络。
- UniCL:我们使用统一对比学习技术来学习图像-文本表示。
- X-Decoder:我们基于X-Decoder构建了SEEM,X-Decoder是一个通用解码器,可以用一个模型完成多个任务。
:fire: 其他你可能感兴趣的项目:
- Semantic-SAM,一个通用图像分割模型,可以在任何所需粒度下分割和识别任何物体
- OpenSeed:强大的开放集分割方法。
- Grounding SAM:结合Grounding DINO和Segment Anything;Grounding DINO:一个强大的开放集检测模型。
- X-GPT:由X-Decoder支持的对话式视觉代理。
- LLaVA:大型语言和视觉助手。
:bulb: 亮点
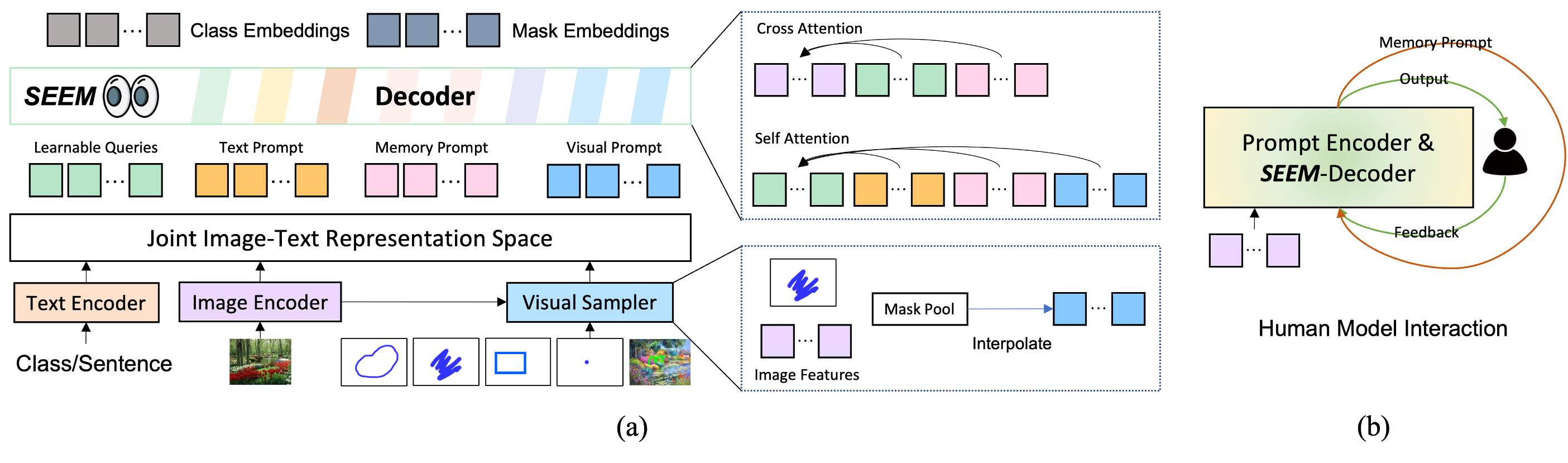
受到大语言模型中通用接口的启发,我们倡导单一模型实现任何类型分割的通用、交互式多模态接口。我们强调SEEM的4个重要特征如下。
- 多功能性:适用于各种类型的提示,例如点击、框、多边形、涂鸦、文本和参考图像;
- 组合性:处理任何提示的组合;
- 交互性:与用户进行多轮交互,得益于SEEM的记忆提示存储会话历史;
- 语义感知:为任何预测的掩码提供语义标签;
:unicorn: 如何使用演示
- 首先尝试我们的默认示例;
- 上传一张图片;
- 选择至少一种你喜欢的提示类型(如果你想使用另一张图片的参考区域,请选中"示例"并在参考图像面板中上传另一张图片);
- 记得为你选择的每种提示类型提供实际提示,否则你会遇到错误(例如,记得在参考图像上绘画);
- 我们的模型默认支持COCO 80类别的词汇表,其他类别将被归类为"其他"或被错误分类。如果你想使用开放词汇标签进行分割,请在画完涂鸦后在"文本"按钮中包含文本标签。
- 点击"提交"并等待几秒钟。
:volcano: 一个有趣的例子
一个变形金刚的例子。参考图像是擎天柱的卡车形态。无论擎天柱是什么形态,我们的模型都能在目标图像中分割出擎天柱。感谢Hongyang Li提供这个有趣的例子。
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/dee60b45-b01e-4a4e-9709-b60100fca57f.png" width = "700" alt="assets/images/transformers_gh.png" align=center /> </div>:tulip: NERF示例
- 受SA3D中示例的启发,我们在NERF示例上尝试了SEEM,效果很好 :)
:camping: 点击、涂鸦生成遮罩
用户只需简单点击或涂抹,我们就能生成相应的遮罩及其类别标签。

:mountain_snow: 文本生成遮罩
SEEM可以根据用户的文本输入生成遮罩,实现与人类的多模态交互。

:mosque: 参考图像生成遮罩
在参考图像上简单点击或涂抹,模型就能在目标图像上分割出具有相似语义的物体。

SEEM对空间关系的理解非常出色。看看这三只斑马!分割出的斑马与参考斑马的位置相似。例如,当上排最左边的斑马被指定时,下排最左边的斑马就被分割出来。

:blossom: 参考图像生成视频遮罩
无需在视频数据上训练,SEEM可以完美地根据您指定的任何查询为视频分割!

:sunflower: 音频生成遮罩
我们使用Whisper将音频转换为文本提示来分割物体。在我们的演示�中试试吧!
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/7e58b3e1-fb72-4c54-938f-eaec08184fae.png" width = "900" alt="assets/images/audio.png" align=center /> </div>:deciduous_tree: 不同风格的示例
分割表情包的示例。
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/72fb5f2a-2328-47d7-b74b-f554fd839b83.png" width = "500" alt="assets/images/emoj.png" align=center /> </div>分割卡通风格树木的示例。
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/7a801832-9b43-49d8-a58c-a2d2a95c4b46.png" width = "700" alt="assets/images/trees_text.png" align=center /> </div>分割Minecraft图像的示例。
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/db16c018-f923-4831-b006-43fda2c7175d.png" width = "700" alt="assets/images/minecraft.png" align=center /> </div>在流行的泰迪熊上使用参考图像的示例。

模型
与SAM的比较
在下图中,我们比较了三种分割任务(边缘检测、开放集和交互式分割)的交互和语义水平。开放集分割通常需要较高的语义水平,但不需要交互。与SAM相比,SEEM涵盖了更广泛的交互和语义水平。例如,SAM仅支持有限的交互类型,如点和框,而由于它本身不输出语义标签,因此缺少高语义任��务。原因如下:首先,SEEM有一个统一的提示编码器,将所有视觉和语言提示编码到一个联合表示空间中。因此,SEEM可以支持更广泛的用途。它有潜力扩展到自定义提示。其次,SEEM在文本到遮罩(基于定位的分割)方面表现出色,并输出具有语义意识的预测。
<div align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/69999e91-f363-4e20-94d9-2d43449b88d7.jpg" width = "500" alt="assets/images/compare.jpg" align=center /> </div>:cupid: 致谢
- 我们感谢hugging face为演示提供的GPU支持!
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号