
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文VEnhancer: 视频生成的生成式时空增强
高鹏, 林达华, 乔宇, 欧阳万里, 刘子为
香港中文大学, 上海人工智能实验室,
南洋理工大学S-Lab


VEnhancer,一个可以改善现有文本到视频结果的生成式时空增强框架。
| VideoCrafter2 | +VEnhancer |

|

|

|

|
🔥 更新
- [2024.07.28] 推理代码和预训练视频增强模型已发布。
- [2024.07.10] 创建此仓库。
🎬 概述
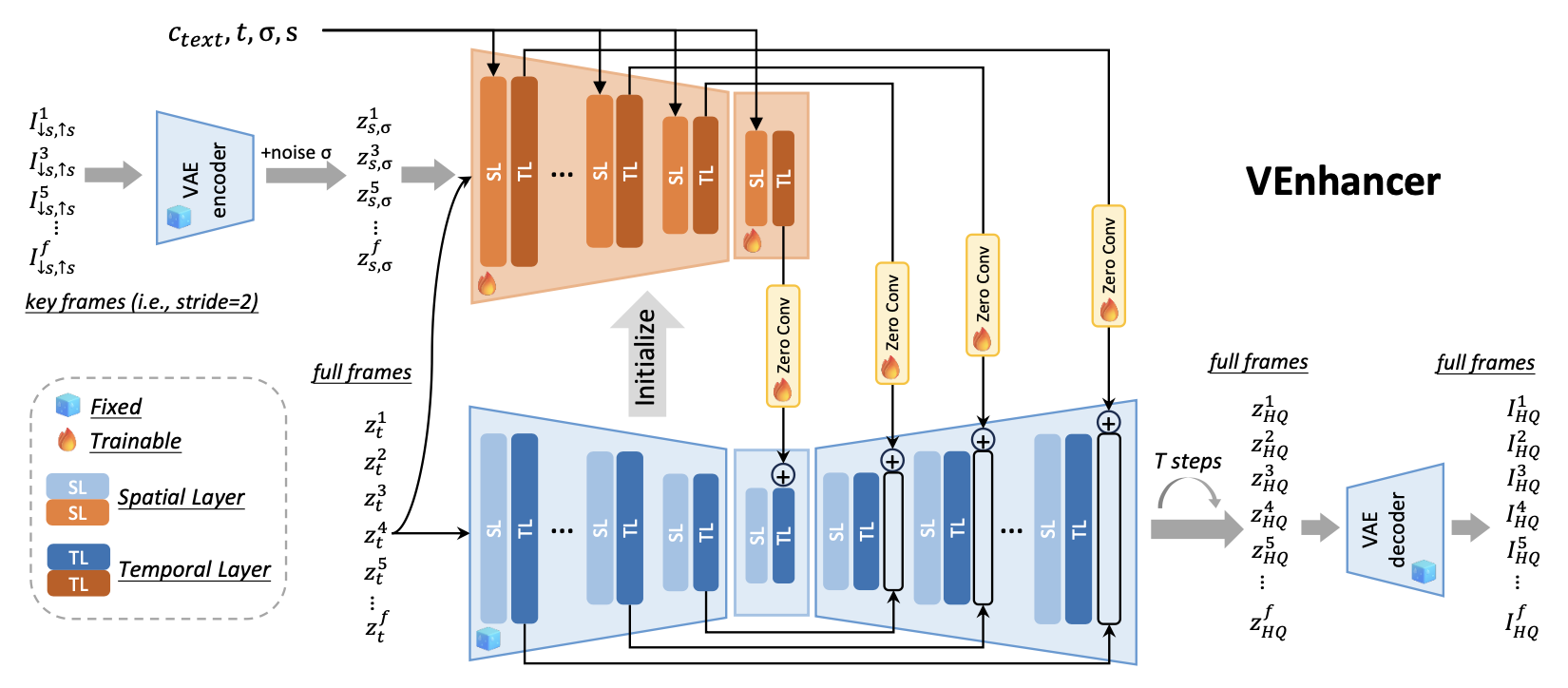
VEnhancer的架构。它遵循ControlNet,并复制预训练视频扩散模型的多帧编码器和中间块的架构和权重,以构建可训练的条件网络。
这个视频ControlNet接受低分辨率关键帧以及噪声潜在空间的完整帧作为输入。
此外,关于噪声增强的噪声级别$\sigma$和下采样因子$s$作为额外的网络条件,除了时间步$t$和提示$c_{text}$之外。
:gear: 安装
# 克隆此仓库
git clone https://github.com/Vchitect/VEnhancer.git
cd VEnhancer
# 创建环境
conda create -n venhancer python=3.10
conda activate venhancer
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
pip install -r requirements.txt
注意,ffmpeg命令应该被启用。如果您有sudo权限,可以使用以下命令安装:
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
:dna: 预训练模型
💫 推理
- 通过open clip下载clip模型,通过sd2.1下载Stable Diffusion的VAE,并下载VEnhancer模型。然后,将这三个检查点放在
VEnhancer/ckpts目录中。 - 运行以下命令。
bash run_VEnhancer.sh
BibTeX
如果您在研究中使用了我们的工作,请引用我们的出版物:
@article{he2024venhancer,
title={VEnhancer: Generative Space-Time Enhancement for Video Generation},
author={He, Jingwen and Xue, Tianfan and Liu, Dongyang and Lin, Xinqi and Gao, Peng and Lin, Dahua and Qiao, Yu and Ouyang, Wanli and Liu, Ziwei},
journal={arXiv preprint arXiv:2407.07667},
year={2024}
}
🤗 致谢
我们的代码库基于modelscope构建。 感谢作者们分享他们出色的代码库!
📧 联系
如果您有任何问题,请随时通过hejingwenhejingwen@outlook.com与我们联系。











