
aiXcoder-7B
多语言代码生成模型 提高开发效率与代码质量
aiXcoder-7B是一个支持多种编程语言的代码生成模型。该模型在代码补全、理解和生成方面表现优异,经过1.2万亿唯一标记的训练,采用了针对实际代码生成场景的预训练任务和上下文信息设计。aiXcoder-7B提高了代码补全和生成的效率与准确性,未来还将优化测试用例生成和代码调试等功能,为开发者提供更全面的编程支持。



aiXcoder-7B 代码大语言模型
<p align="center"> 🏠 <a href="https://www.aixcoder.com/" target="_blank">官方网站</a>|🛠 <a href="https://marketplace.visualstudio.com/items?itemName=aixcoder-plugin.aixcoder" target="_blank">VS Code 插件</a>|🛠 <a href="https://plugins.jetbrains.com/plugin/13574-aixcoder-code-completer" target="_blank">Jetbrains 插件</a>|🤗 <a href="https://huggingface.co/aiXcoder/aixcoder-7b-base" target="_blank">模型权重</a>|<a href="./assets/wechat_1.jpg" target="_blank">微信</a>|<a href="./assets/wechat_2.jpg" target="_blank">微信公众号</a> </p>欢迎来到 aiXcoder-7B 代码大语言模型的官方仓库。该模型旨在理解和生成多种编程语言的代码,在代码补全、理解、生成等编程语言相关任务中提供最先进的性能。
目录
模型介绍
随着大型代码模型能力的逐步挖掘,aiXcoder 一直在思考如何让这些模型在实际开发场景中发挥更大的作用。为此,我们开源了 aiXcoder 7B Base,该模型在 1.2T 独特 Token 上进行了大规模训练,其预训练任务和上下文�信息都针对真实代码生成场景进行了独特设计。
aiXcoder 7B Base 在代码补全场景中是同等参数规模模型中最有效的模型,并且在多语言 nl2code 基准测试的平均性能上超过了像 codellama 34B 和 StarCoder2 15B 这样的主流模型。
在我们持续探索大型代码模型应用的过程中,aiXcoder 7B Base 的发布是一个重要里程碑。当前版本的 aiXcoder 7B Base 是一个基础模型,专注于提高代码补全和代码生成任务的效率和准确性,旨在为开发者在这些场景中提供强有力的支持。值得注意的是,这个版本尚未经过特定的指令微调,这意味着它可能还无法为测试用例生成和代码调试等专门的高级任务提供最佳性能。
然而,我们已经有计划进一步发展 aiXcoder 模型系列。在不久的将来,我们计划发布经过精心指令微调的新版本模型,以适应更广泛的编程任务,包括但不限于测试用例生成和代码调试。通过这些经过指令微调的模型,我们期望为开发者提供更全面、更深入的编程支持,帮助他们在软件开发的每个阶段最大化效率。
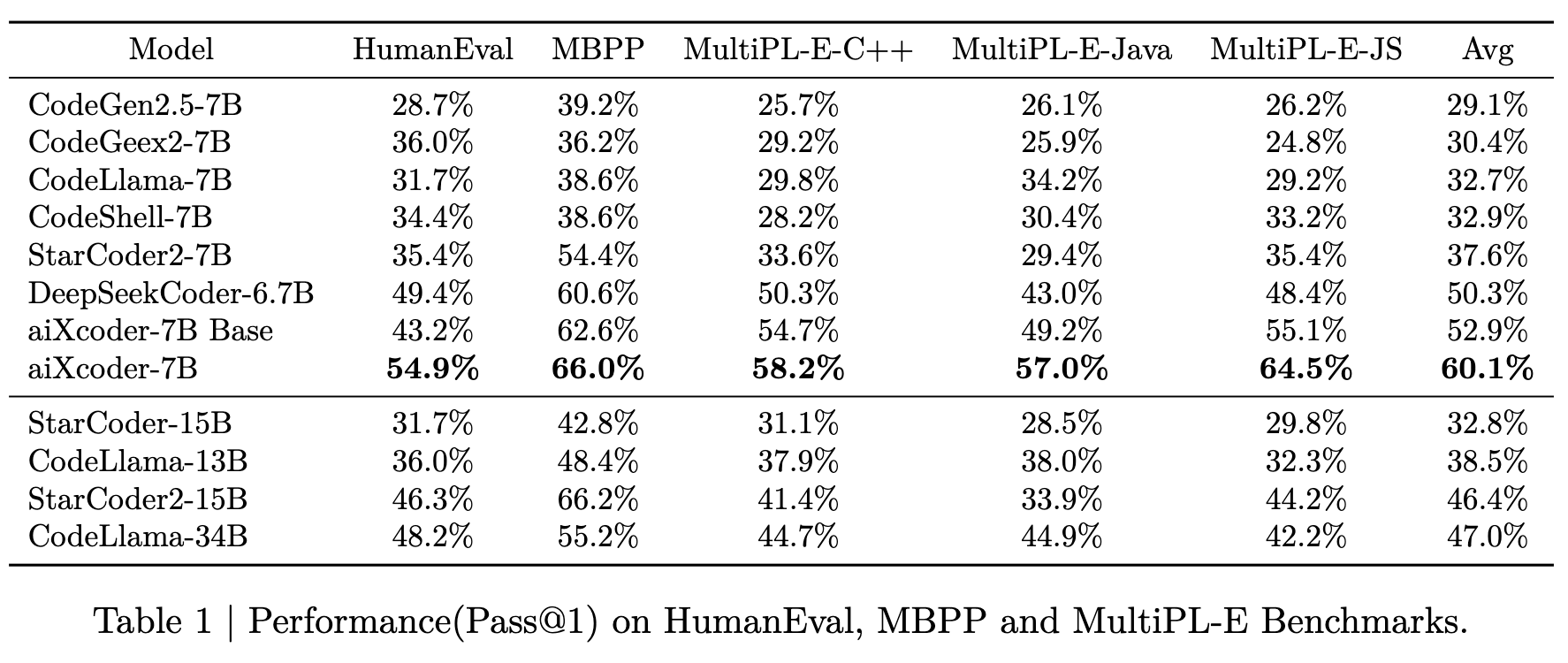
<br> <br>aiXcoder 7B 在 nl2code 基准测试中超越了主流模型。aiXcoder-7B 是 aiXcoder-7B-Base 的增强版,在类似 Evol-instruct 的十万条数据上进行了一个 epoch 的微调。
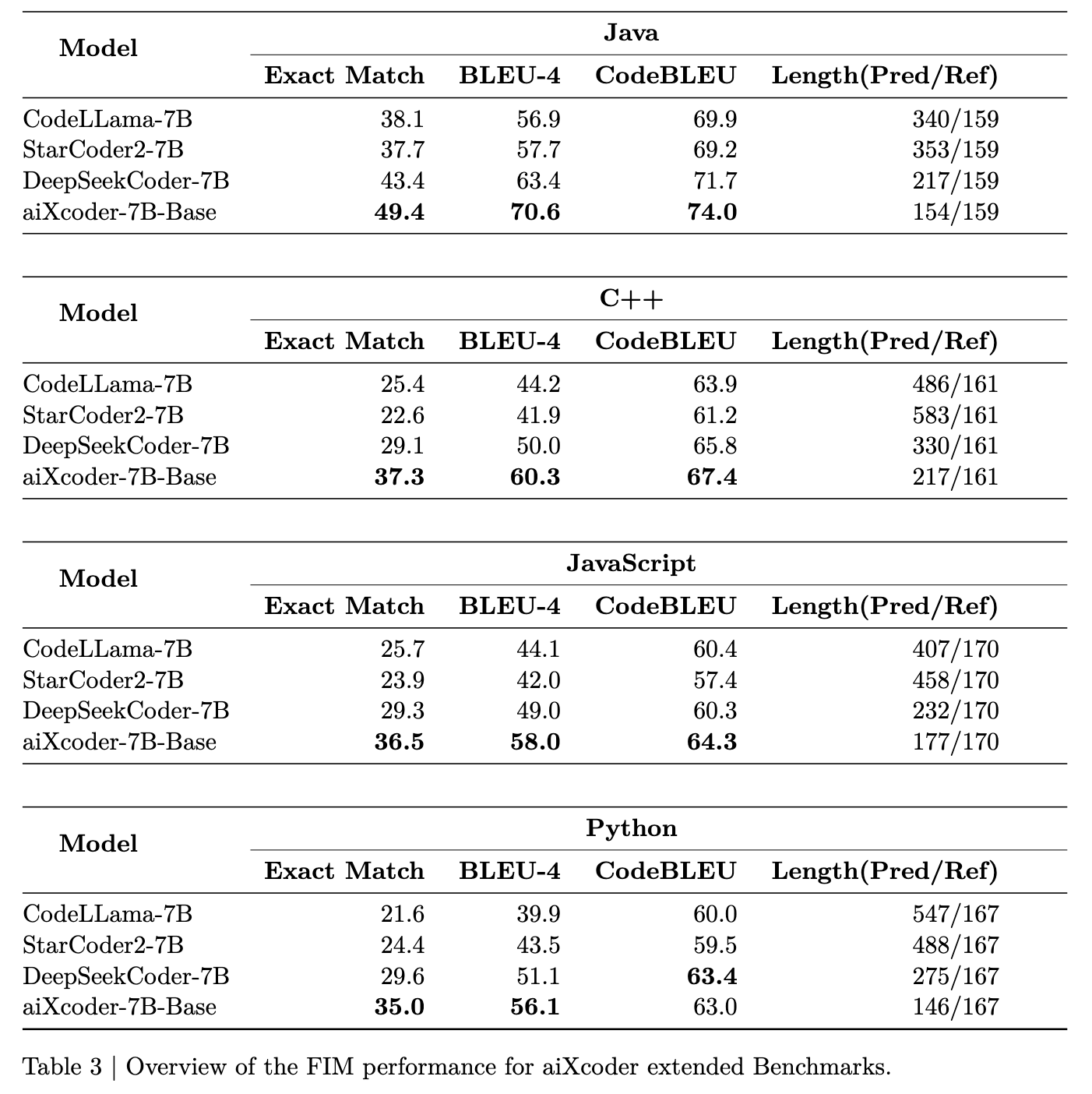
<br> <br>aiXcoder 7B Base 在代码补全场景中超越了主流模型。
快速开始
环境要求
选项1:构建环境
要运行模型推理代码,您需要以下环境设置:
- Python 3.8 或更高版本
- PyTorch 2.1.0 或更高版本
- sentencepiece 0.2.0 或更高版本
- transformers 4.34.1 或更高版本(如果使用 transformers 库进行推理)
请确保使用以下命令安装所有依赖项:
conda create -n aixcoder-7b python=3.11 conda activate aixcoder-7b git clone git@github.com:aixcoder-plugin/aiXcoder-7b.git cd aiXcoder-7b pip install -r requirements.txt
requirements.txt 列出了所有必需的库及其版本。
为了实现更快的推理速度,特别是对于大型模型,我们建议安装 flash attention。Flash attention 是一种优化的注意力机制,可以显著减少transformer模型的计算时间,同时不牺牲准确性。
在继续之前,请确保您的环境满足 CUDA 要求,因为 flash attention 利用 GPU 加速。按照以下步骤安装 flash attention:
git clone git@github.com:Dao-AILab/flash-attention.git cd flash-attention MAX_JOBS=8 python setup.py install
选项2:Docker
为了获得一致和隔离的环境,我们建议使用 Docker 运行模型推理代码。以下是如何为我们的模型设置和使用 Docker:
-
安装 Docker:如果您尚未安装,请在您的机器上安装 Docker。
-
拉取 Docker 镜像:从 Docker Hub 拉取 Docker 镜像。
docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel
- 运行容器:一旦镜像拉取完成,您可以在 Docker 容器内运行模型。
docker run --gpus all -it -v /dev/shm:/dev/shm --name aix_instance pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bash pip install sentencepiece git clone git@github.com:aixcoder-plugin/aiXcoder-7b.git cd aiXcoder-7b
这条命令从pytorch镜像启动一个名为aix_instance的容器。你可以在这个容器内与模型进行交互。
为了实现更快的推理速度,特别是对于大型模型,我们建议安装flash attention。
git clone git@github.com:Dao-AILab/flash-attention.git cd flash-attention MAX_JOBS=8 python setup.py install
- 模型推理:在Docker容器内,你可以按照推理示例部分的描述运行模型推理代码。
使用Docker提供了一个干净、可控的环境,最大限度地减少了与软件版本和依赖项相关的问题。
模型权重
你可以从以下链接下载模型权重:
- aiXcoder Base下载
- aiXcoder Instruct下载(即将推出...)
推理示例
命令行执行
快速开始时,你可以直接从命令行运行模型推理:
torchrun --nproc_per_node 1 sess_megatron.py --model_dir "path/to/model_weights_dir"
将"path/to/model_weights_dir"替换为你下载的模型权重的实际路径。
或者使用huggingface的transformers运行推理:
python sess_huggingface.py
Python脚本执行
另外,你也可以在Python脚本中以编程方式调用模型。这种方法在将模型集成到你的应用程序或工作流程中时提供了更多的灵活性。以下是一个简单的示例:
from sess_megatron import TestInference infer = TestInference() res = infer.run_infer( # 对于FIM风格的输入,code_string代表前缀上下文 code_string="""# 快速排序算法""", # 对于FIM风格的输入,later_code代表后缀上下文 later_code="\n", # file_path应该是从项目到文件的路径 file_path="test.py", # 生成的最大token数 max_new_tokens=256, ) print(res) """输出: def quick_sort(arr): if len(arr) <= 1: return arr pivot = arr[0] less = [i for i in arr[1:] if i <= pivot] greater = [i for i in arr[1:] if i > pivot] return quick_sort(less) + [pivot] + quick_sort(greater) # 测试 arr = [3, 2, 1, 4, 5] print(quick_sort(arr)) # [1, 2, 3, 4, 5] """
import torch import sys from hf_mini.utils import input_wrapper from transformers import AutoModelForCausalLM, AutoTokenizer device = "cuda" # 加载模型的设备 tokenizer = AutoTokenizer.from_pretrained("aiXcoder/aixcoder-7b-base") model = AutoModelForCausalLM.from_pretrained("aiXcoder/aixcoder-7b-base", torch_dtype=torch.bfloat16) text = input_wrapper( # 对于FIM风格的输入,code_string代表前缀上下文 code_string="# 快速排序算法", # 对于FIM风格的输入,later_code代表后缀上下文 later_code="\n# 测试\narr = [3, 2, 1, 4, 5]\nprint(quick_sort(arr)) # [1, 2, 3, 4, 5]", # file_path应该是从项目到文件的路径 path="test.py" ) if len(text) == 0: sys.exit() inputs = tokenizer(text, return_tensors="pt", return_token_type_ids=False) inputs = inputs.to(device) model.to(device) outputs = model.generate(**inputs, max_new_tokens=256) print(tokenizer.decode(outputs[0], skip_special_tokens=False)) """输出: def quick_sort(arr): # 如果数组长度小于等于1,直接返回 if len(arr) <= 1: return arr # 选择数组的第一个元素作为基准 pivot = arr[0] # 初始化左右指针 left, right = 1, len(arr) - 1 # 循环直到左指针小于右指针 while left < right: # 从右到左找到第一个小于基准的元素,与左指针元素交换 if arr[right] < pivot: arr[left], arr[right] = arr[right], arr[left] left += 1 # 从左到右找到第一个大于等于基准的元素,与右指针元素交换 if arr[left] >= pivot: right -= 1 # 将基准元素与左指针元素交换 arr[left], arr[0] = arr[0], arr[left] # 对左半部分进行递归排序 quick_sort(arr[:left]) # 对右半部分进行递归排序 quick_sort(arr[left + 1:]) return arr</s> """
通过bitsandbytes进行量化
我们还可以通过pip install bitsandbytes acceleration安装Bitsandbytes,然后简单地添加配置来执行int8或int4推理(如果你需要进一步压缩运行时应用的临时内存,建议安装FlashAttention):
import sys import torch from hf_mini.utils import input_wrapper from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig # 使用4位量化,请改用`load_in_4bit=True` bnb_config = BitsAndBytesConfig(load_in_8bit=True) device = "cuda" # 加载模型的设备 tokenizer = AutoTokenizer.from_pretrained("aiXcoder/aixcoder-7b-base") model = AutoModelForCausalLM.from_pretrained("aiXcoder/aixcoder-7b-base", quantization_config=bnb_config, device_map=device, attn_implementation='flash_attention_2') text = input_wrapper( code_string="# 快速排序算法", later_code="\n", path="test.py" ) if len(text) == 0: sys.exit() inputs = tokenizer(text, return_tensors="pt", return_token_type_ids=False) inputs = inputs.to(device) outputs = model.generate(**inputs, max_new_tokens=256) print(f"模型内存占用: {model.get_memory_footprint() / 2**20:.2f} MB") print(f"Torch最大内存分配: {torch.cuda.max_memory_allocated() / 2**20:.2f} MB") """ load_in_4bit=True: - 模型内存占用: 5656.52 MB - Torch最大内存分配: 6448.89 MB load_in_8bit=True: - 模型内存占用: 9008.52 MB - Torch最大内存分配: 10061.51 MB """
微调示例
如果你想在自己的代码上进行微调,可以使用Huggingface�的PEFT工具快速开始训练。在此之前,你需要通过pip install -r requirements_peft.txt安装必要的库。
然后,执行训练命令:
accelerate launch finetune.py \ --model_id "aiXcoder/aixcoder-7b-base" \ --dataset_name "bigcode/the-stack-smol" \ --subset "data/rust" \ --dataset_text_field "content" \ --split "train" \ --max_seq_length 1024 \ --max_steps 10000 \ --micro_batch_size 1 \ --gradient_accumulation_steps 8 \ --learning_rate 5e-6 \ --warmup_steps 20 \ --fim_rate 0.5 \ --num_proc "$(nproc)"
在微调脚本中,我们构建了一个简单的随机FIM(Fill-In-the-Middle)训练任务,可以在你自己的数据上训练模型的补全和生成能力。需要注意的是,aiXcoder-7b-base在预训练时使用了结构化FIM,即将完整的代码块构建为MIDDLE。但是构建这样的训练数据需要进行语法解析,可能需要开发者自行实现。
aiXcoder 7B的数据
aiXcoder的数据分为核心数据集和扩展数据集。核心数据集包括开发中常用的编程语言以及与代码密切相关的自然语言。核心数据集的编程语言主要包括C++、Python、Java、JavaScript等近百种主流语言,自然语言部分主要由StackOverflow问答、技术博客、代码文档和计算机科学论文组成。扩展数据主要由经过筛选的开源代码数据集、高质量英文自然语言数据集和高质量中文自然语言数据集构成。
aiXcoder核心数据集主要用于提升大型代码模型在上述编程语言中的表现,经过了严格的过滤和筛选过程。具体来说,这个过程包括以下步骤:1)原始数据选择;2)项目综合排名与筛选;3)使用MinHashes等方法进行代码去重和自动生成代码的去除;4)个人敏感信息的识别与处理;5)注释代码的清理;6)语法分析以过滤不正确或异常的代码文件;7)静态分析以检测和消除Java、C++、Python、JavaScript等主流编程语言中的163种高风险bug和197种缺陷。
- 原始数据选择
- 排除copyleft许可证下的项目。
- 对从各种代码托管平台和开源数据集收集的项目进行去重。
- 项目级综合排名
- 计算项目指标,包括Stars数量、Git Commit次数和Test文件数量。
- 根据综合评分排除最低10%的数据。
- 代码文件级过滤
- 移除自动生成的代码。
- 采用近似去重方法进行冗余删除。
- 敏感信息移除
- 使用命名实体识别模型识别并删除姓名、IP地址、账号密码、URL等敏感信息。
- 注释代码
- 随机删除大段注释代码
- 语法分析
- 删除前五十种语言中存在语法解析错误或语法错误的代码。
- 静态分析
- 利用静态分析工具扫描并定位161种影响代码可靠性和可维护性的Bug,以及197种影响代码安全性的漏洞。
# "__init__"方法不应返回值 # 不合规:将引发TypeError class MyClass(object): def __init__(self): self.message = 'HelloWorld' return self # 合规解决方案 class MyClass(object): def __init__(self): self.message = 'HelloWorld'
上述代码展示了Python中__init__方法不应返回值的bug模式。
训练
训练超参数
分词器:
- 基于字节码的字节对编码(BPE)
- 词汇表大小为49,152
模型结构:
- 使用RoPE(旋转位置编码)进行相对位置编码
- 使用SwiGLU作为中间层
- 使用分组查询注意力
训练参数:
- 结构化FIM(填充中间)训练任务占70%,自回归训练任务占30%
- 预训练序列长度为32,768
批处理方法
经过预处理后,我们的代码数据按项目组织,项目内文件的顺序既考虑规则又考虑随机性。具体来说,我们尝试使用调用图、K-Means聚类、文件路径相似度和TF-IDF距离等方法将相似或相依的代码文件聚集在一起,以帮助模型更好地理解代码文件之间的关系。然而,代码文件的排序也包含随机性,因为在实际编程场景中,项目并不完整,相似或相依的代码文件可能尚未完全开发。
通过确保项目代码文件整体上表现出随机性,而局部上具有相似或相依关系,我们将项目代码文件拉伸成一个向量,并使用Transformer-XL风格的处理方式组织批次序列。即使单个批次的序列长度在预训练过程中已达到32,768,这种方法仍然允许可见序列长度的延伸更长。
预训练任务
与其他自然语言大模型或代码模型不同,在代码编程的语境中,aiXcoder考虑了代码本身的结构特征,旨在让模型预测完整的代码节点。简单来说,aiXcoder 7b的训练任务结合了填充中间(FIM,Bavarian等人,2022)和解析器生成器工具技术。在构建训练数据时,我们将代码解析为抽象语法树(AST),并随机选择一个完整节点来构建FIM任务。这种方法的理由有两个:首先,我们需要确保输入数据相对完整,前后部分处于同一层级。其次,我们还希望模型的预测更加完整,生成的代码具有完整的层级结构��。
for i in range(20): if i % 5 == 0: print("Hello World")

<br> <br>鉴于简单的代码可以被解析成抽象语法树(AST),我们将基于AST的节点构建结构化的填充中间(FIM)训练任务。
假设我们选择上述AST中的IF节点,那么我们将从IF节点及其子树构建训练样本。以下两个例子是等效的:
# 填充中间,SPM模式 "<s>▁<AIX-SPAN-PRE>▁<AIX-SPAN-POST> print(\"Hello World\")\n▁<AIX-SPAN-MIDDLE># the file path is: test.py\n# the code file is written by Python\nfor i in range(20):\n if i % 5 == 0:<\s>" # 填充中间,PSM模式 "<s>▁<AIX-SPAN-PRE># the file path is: test.py\n# the code file is written by Python\nfor i in range(20):\n if ▁<AIX-SPAN-POST> print(\"Hello World\")\n▁<AIX-SPAN-MIDDLE>i % 5 == 0:<\s>"
实验结果详情
NL2Code基准测试
表1显示了aiXcoder-7B基础模型在独立方法生成基准测试上的表现。我们的模型在数百亿参数范围内的大规模预训练基础模型中达到了当前最佳结果。
代码补全(填充中间)
与表1中的独立nl2code任务不同,在实际编程场景中,我们需要考虑光标位置的代码补全能力。通常,各种开源代码大语言模型在预训练时都会加入填充中间(FIM)模式,以提高模型在考虑代码上下文时生成更准确结果的能力。因此,我们将使用FIM作为默认的代码补全方法来评估各模型在实际编程场景中的表现。
目前,上下文感知的代码补全主流评估数据集是Santacoder(Ben Allal等人,2023)提出的单行评估方法。该评估数据集从HumanEval或MultiPL-E中提取单行代码,并在给定完整前后文的情况下评估模型生成结果的精确匹配度。
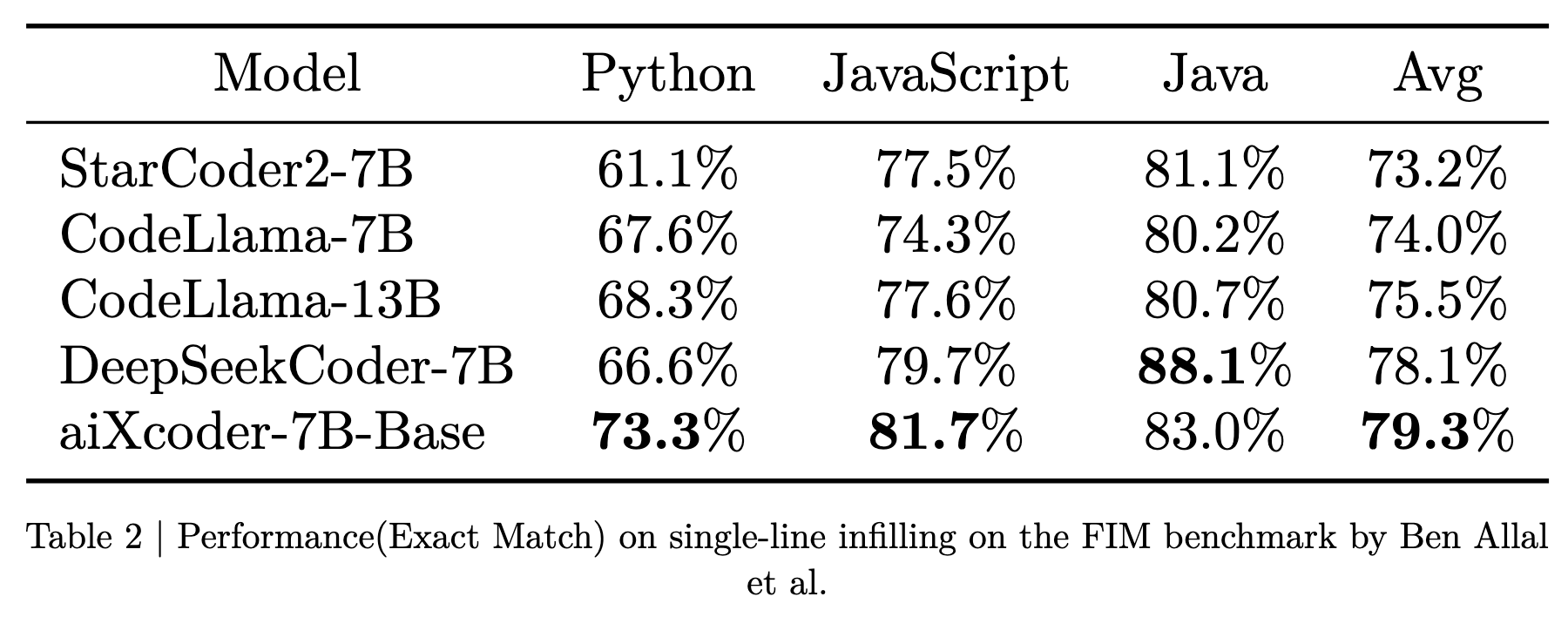
为了更细粒度地评估代码大语言模型的代码补全能力,aiXcoder构建了一个规模更大、测试代码更多样化、测试代码上下文长度更长、更贴近实际开发项目的评估数据集。这个评估数据集也将同步在GitHub上开源。在评估过程中,我们确保不同的代码大语言模型使用相同的16K最大序列长度,并评估在不同场景下的生成性能,如生成完整方法块、条件块、循环处理块、异常处理块等共计十三种情况。
表3显示了不同模型在不同语言中的平均生成性能。最终评估结果是所有补全场景和评估样本的平均值。aiXcoder 7B基础模型在主要编程语言和各项评估指标上都取得了最佳表现,表明aiXcoder 7B基础模型在同等规模的所有开源模型中具有最佳的基础代码补全能力,是在实际编程场景中提供代码补全能力的最适合的基础模型。
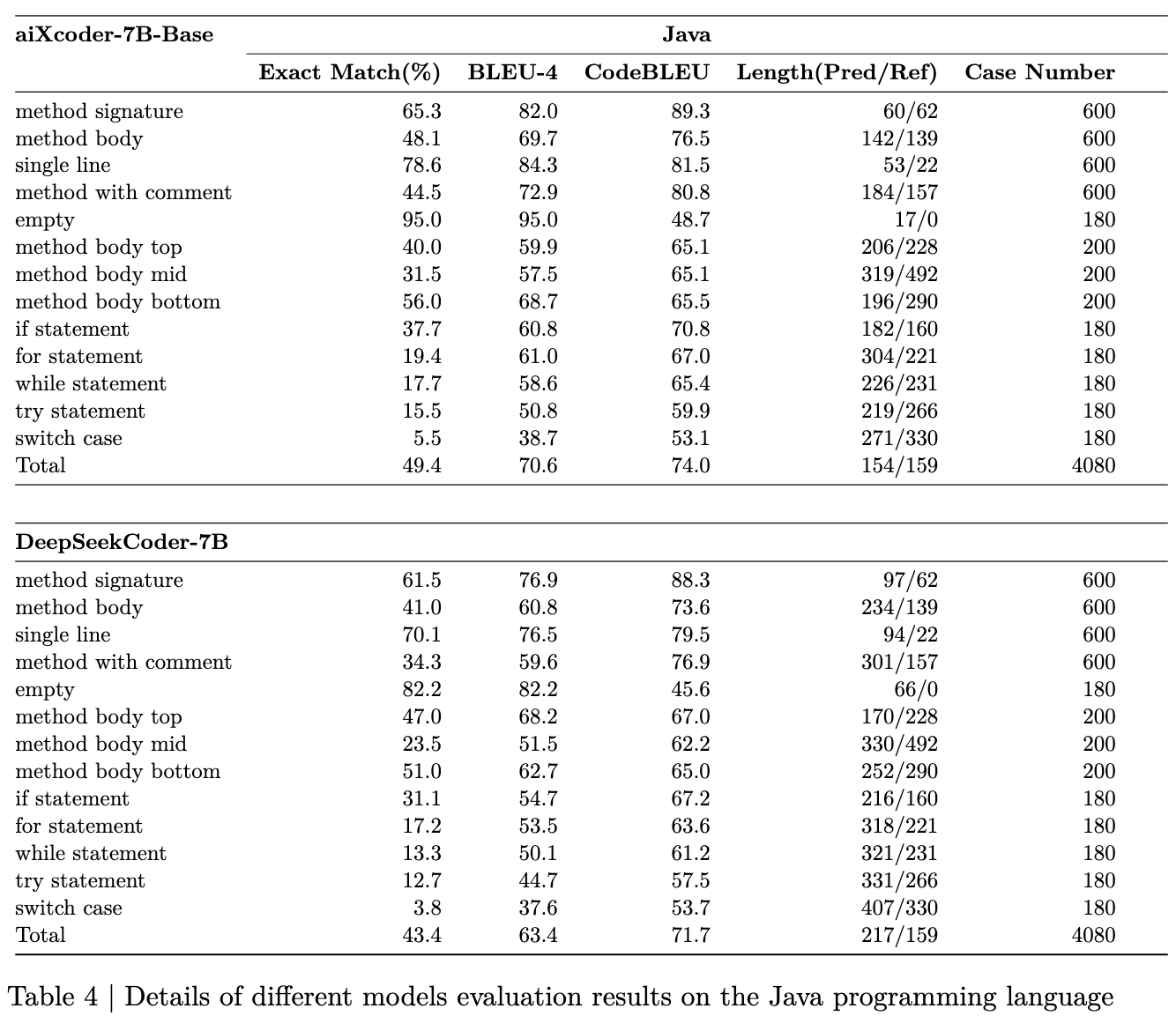
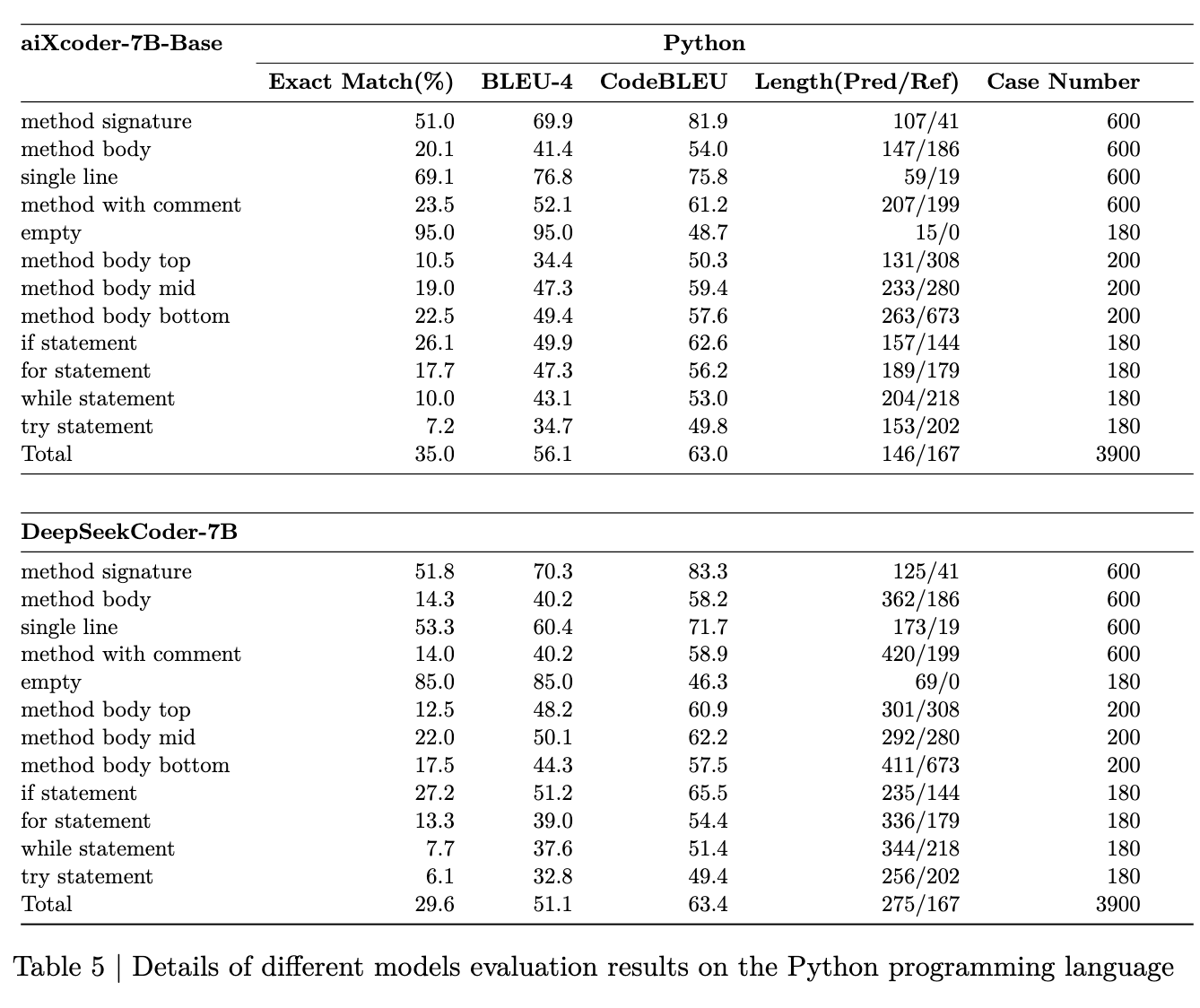
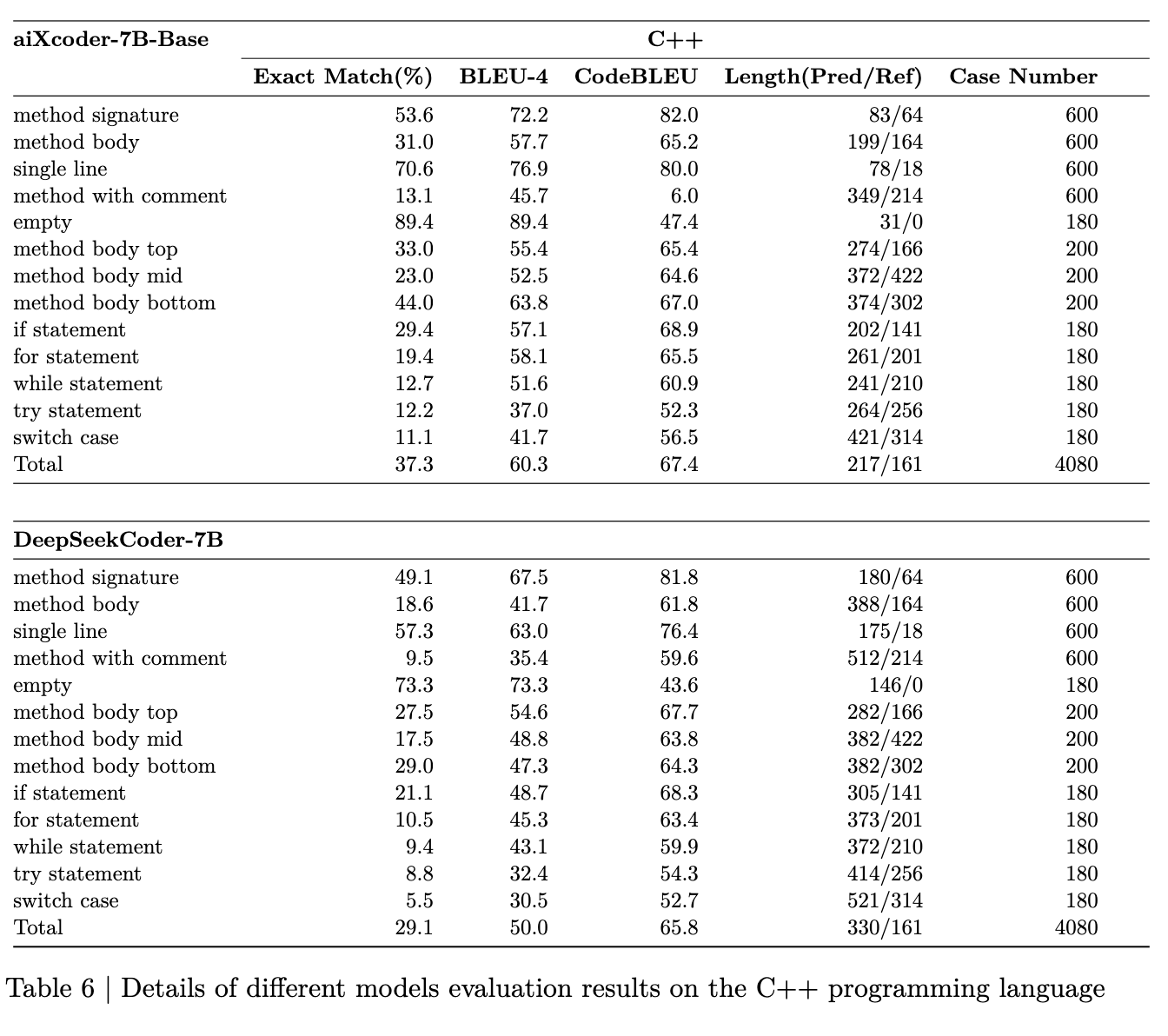
表3中的每个评估结果都有更详细的评估维度。表4至表7显示了不同模型在不同语言中的多维评估细节:
- 方法签名表示模型根据上下文生成方法签名的能力。
- 方法体代表模型根据上下文生成完整方法体的能力,包括函数签名。
- 单行指单行代码的补全。
- 带注释的方法表示根据上下文生成相应的函数体,包括函数签名和注释。
- 空白表示模型在完整上下文情况下预测空白的能力。
- 方法体上、中、下部分别展示了函数体上部、中部、下部的代码生成性能。
- If、for、while、try、switch语句代表生成条件代码块、循环代码块、异常捕获块和条件分支块的效果。

跨文件代码评估
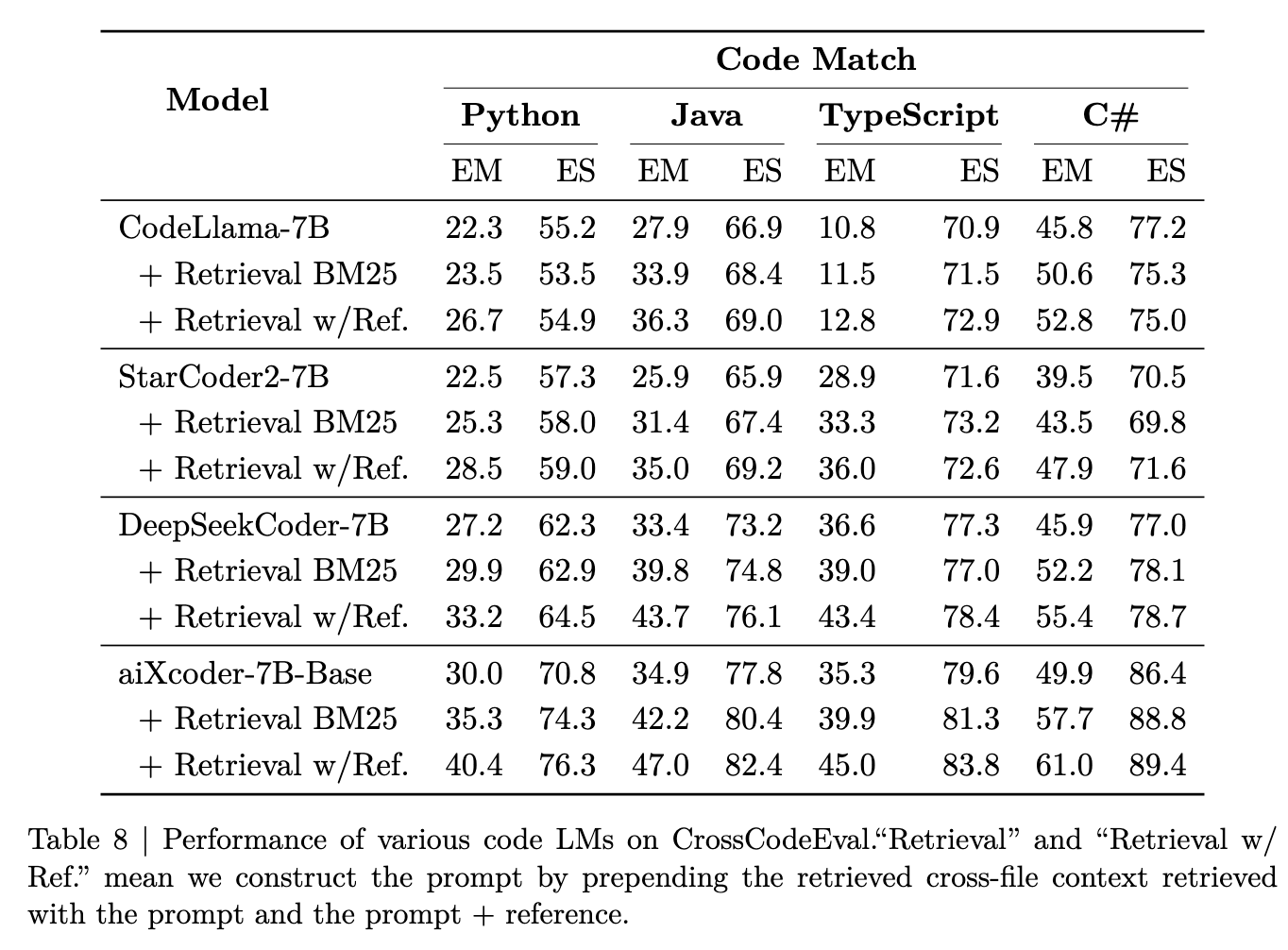
大型语言模型在处理代码时的另一个重要能力是理解跨文件的代码上下文,因为开发人员在编写代码时经常需要考虑当前项目中其他文件的信息。因此,我们采用了CrossCodeEval(Ding等,2023)评估数据集来评估模型提取跨文件上下文信息的能�力。
在表8中,我们将所有模型的上下文长度固定为16K,并使用FIM中的PSM模式格式化输入。模型完成推理后,所有输出结果均使用贪婪搜索进行解码。首先,作为基线,我们评估了各种大型代码模型在单文件场景下的生成能力。
然后,使用BM25作为相似度度量,我们在项目中搜索三个最相似的代码块作为提示,重新评估模型的生成性能。最后,"w/Ref."表示我们假设知道正确的参考代码是什么样的,然后在项目中搜索三个最相似的代码作为提示,再次评估模型的生成性能。
最终,aiXcoder-7B模型在所有语言中表现非常出色,展示了我们的模型提取上下文信息,特别是跨文件上下文信息的能力。
许可证
本仓库中的源代码根据Apache-2.0许可证授权 - 详情请参见LICENSE文件。模型权重根据模型许可证授权用于学术研究用途;商业用途请发送电子邮件至support@aiXcoder.com申请。
致谢
我们要感谢所有为使这项工作成为可能的开源项目和数据集的贡献者。
感谢您对我们的代码大语言模型的关注。我们期待您的贡献和反馈!
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号