
 Github
Github Huggingface
Huggingface 论文
论文通过多模态大语言模型引导基于指令的图像编辑
本仓库包含了论文《通过多模态大语言模型引导基于指令的图像编辑》(ICLR'24 Spotlight)的代码
概述
MGIE 是以下论文的实现:
"通过多模态大语言模型引导基于指令的图像编辑"
傅祖睿、胡文泽、杜显志、王扬、杨寅飞和甘哲
发表于2024年国际学习表示会议(ICLR)
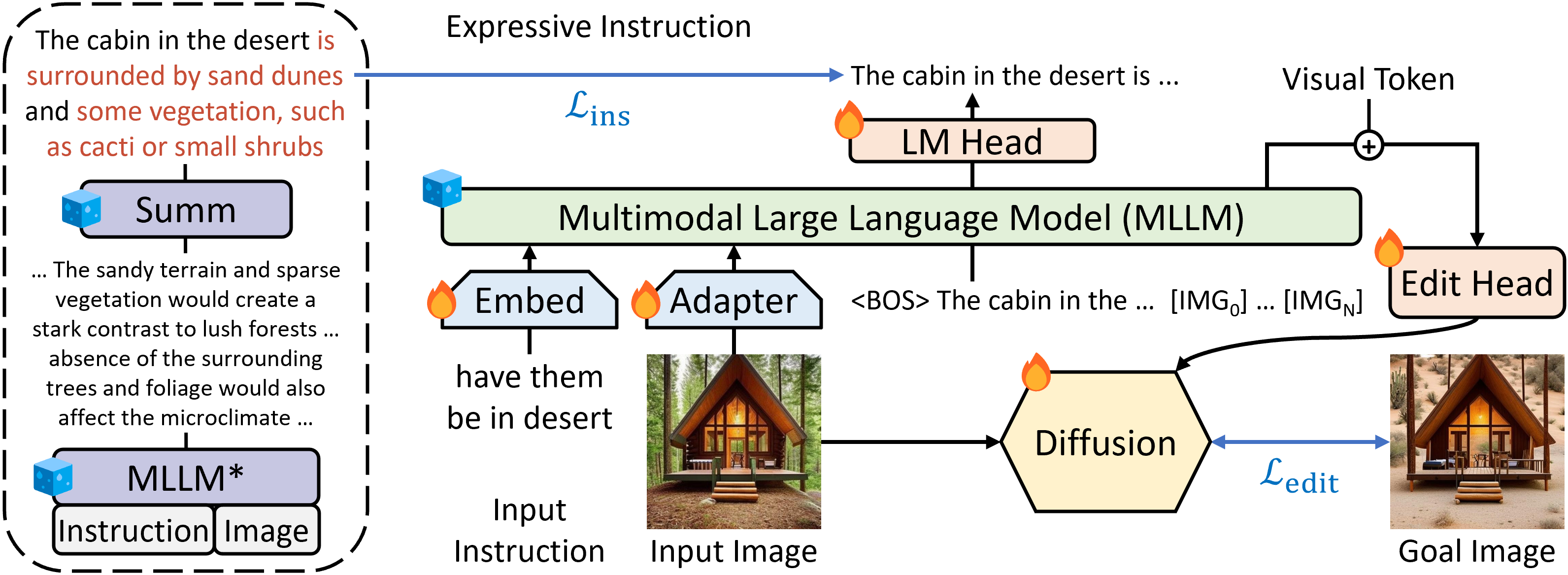
基于指令的图像编辑通过自然命令提高了图像操作的可控性和灵活性,无需详细描述或区域掩码。然而,人类指令有时过于简短,当前方法难以捕捉和遵循。多模态大语言模型(MLLMs)在跨模态理解和视觉感知响应生成方面展现了令人瞩目的能力。我们研究了MLLMs如何促进编辑指令,并提出了MLLM引导的图像编辑(MGIE)。MGIE学习推导出富有表现力的指令并提供明确指导。编辑模型通过端到端训练同时捕捉这种视觉想象并执行操作。
环境要求
conda create -n mgie python=3.10 -y
conda activate mgie
conda update -n base -c defaults conda setuptools -y
conda install -c conda-forge git git-lfs ffmpeg vim htop ninja gpustat -y
conda clean -a -y
pip install -U pip cmake cython==0.29.36 pydantic==1.10 numpy
pip install -U gdown pydrive2 wget jupyter jupyterlab jupyterthemes ipython
pip install -U sentencepiece transformers diffusers tokenizers datasets gradio==3.37 accelerate evaluate git+https://github.com/openai/CLIP.git
pip install -U https://download.pytorch.org/whl/cu113/torch-1.12.0%2Bcu113-cp310-cp310-linux_x86_64.whl https://download.pytorch.org/whl/cu113/torchvision-0.13.0%2Bcu113-cp310-cp310-linux_x86_64.whl https://download.pytorch.org/whl/cu113/torchaudio-0.12.0%2Bcu113-cp310-cp310-linux_x86_64.whl
pip install -U deepspeed
# 克隆此仓库
cd ml-mgie
git submodule update --init --recursive
cd LLaVA
pip install -e .
pip install -U https://download.pytorch.org/whl/cu113/torch-1.12.0%2Bcu113-cp310-cp310-linux_x86_64.whl https://download.pytorch.org/whl/cu113/torchvision-0.13.0%2Bcu113-cp310-cp310-linux_x86_64.whl https://download.pytorch.org/whl/cu113/torchaudio-0.12.0%2Bcu113-cp310-cp310-linux_x86_64.whl
pip install -U ninja flash-attn==1.0.2
pip install -U pydrive2 gdown wget
cd ..
cp mgie_llava.py LLaVA/llava/model/llava.py
cp mgie_train.py LLaVA/llava/train/train.py
快速开始
将官方LLaVA-7B放在_ckpt/LLaVA-7B-v1中,并下载预训练的ckpt(在IPr2Pr + MagicBrush上训练)放在_ckpt/mgie_7b中
demo.ipynb

注意:附加权重差异中的Apple权利特此根据CC-BY-NC许可证授权。Apple不对LLaMa或任何其他第三方软件作出任何陈述,这些软件受其自身条款约束。
使用方法
数据
下载CLIP过滤的IPr2Pr并在_data中处理(包括总结的富有表现力的指令)
process_data.ipynb
这里有示例帮助准备数据
训练
将Vicuna-7B和LLaVA-7B放在_ckpt/vicuna-7b-v1.1和_ckpt/LLaVA-7B-v1中
WANDB_DISABLED='true' torchrun --nnodes=1 --nproc_per_node=8 --master_port=7122 LLaVA/llava/train/train_mem.py --model_name_or_path ./_ckpt/vicuna-7b-v1.1 --version v1 --vision_tower openai/clip-vit-large-patch14 --mm_vision_select_layer -2 --mm_use_im_start_end True --bf16 True --output_dir _snapshot/mgie --num_train_epochs 40 --per_device_train_batch_size 4 --per_device_eval_batch_size 2 --dataloader_num_workers 2 --gradient_accumulation_steps 1 --evaluation_strategy 'no' --save_strategy 'steps' --save_steps 2000 --save_total_limit 10 --learning_rate 5e-4 --weight_decay 0. --warmup_ratio 0.03 --lr_scheduler_type 'cosine' --logging_steps 1 --tf32 True --model_max_length 512 --gradient_checkpointing True --lazy_preprocess True
推理
在_ckpt/mgie_7b中提取训练好的ckpt
extract_ckpt.ipynb
运行我们的演示
demo.ipynb
引用
@inproceedings{fu2024mgie,
author = {Tsu-Jui Fu and Wenze Hu and Xianzhi Du and William Yang Wang and Yinfei Yang, and Zhe Gan},
title = {{通过多模态大语言模型引导基于指令的图像编辑}},
booktitle = {国际学习表示会议 (ICLR)},
year = {2024}
}
致谢
- LLaVA:我们基于的代码库











