




![]()
![]()
![]()
![]()
![]()
学习多人姿态估计的精细局部表征(ECCV 2020聚焦)

*这是[残差步骤网络][11]的PyTorch实现,该网络在2019年COCO关键点挑战赛中获胜,并在COCO测试开发集和测试挑战集上排名第一,如[COCO排行榜][1]所示。
<div align="center"> <p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/09e30a73-b172-47cf-848f-4a231b1024e4.png" width="410px"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/a6b77d1d-816f-496a-bbb6-feeba5196325.png" width="410px"></p> </div>新闻
- 2020年9月: 我们的RSN已被整合到优秀的MMPose框架中。感谢他们的努力。欢迎使用他们的代码库和预训练模型库。⭐
- 2020年7月: 我们的论文被ECCV 2020接收为Spotlight论文 :rocket:
- 2019年9月: 我们的工作在COCO 2019关键点挑战赛中获得第一名和最佳论文奖 :trophy:
<hr />摘要: 在本文中,我们提出了一种新颖的方法,称为残差步骤网络(RSN)。RSN有效地聚合具有相同空间大小的特征(层内特征),以获得精细的局部表征,保留丰富的低层空间信息,从而实现精确的关键点定位。此外,我们提出了一种高效的注意力机制 - 姿态优化机(PRM)来进一步优化关键点位置。我们的方法在2019年COCO关键点挑战赛中获得第一名,并在COCO和MPII基准测试中取得了最先进的结果,且没有使用额外的训练数据和预训练模型。我们的单一模型在COCO测试开发集上达到78.6,在MPII测试数据集上达到93.0。集成模型在COCO测试开发集上达到79.2,在COCO测试挑战集上达到77.1。
残差步骤网络的流程
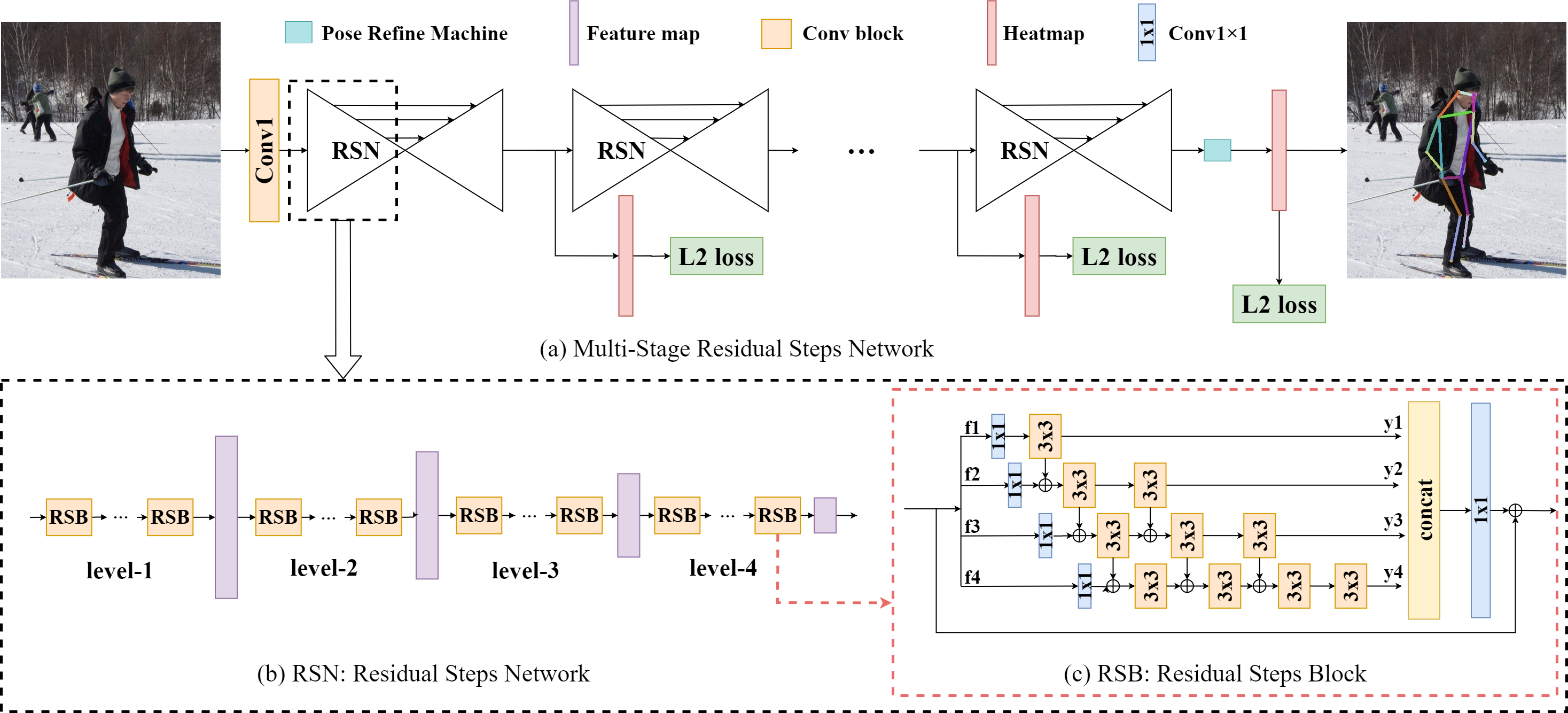
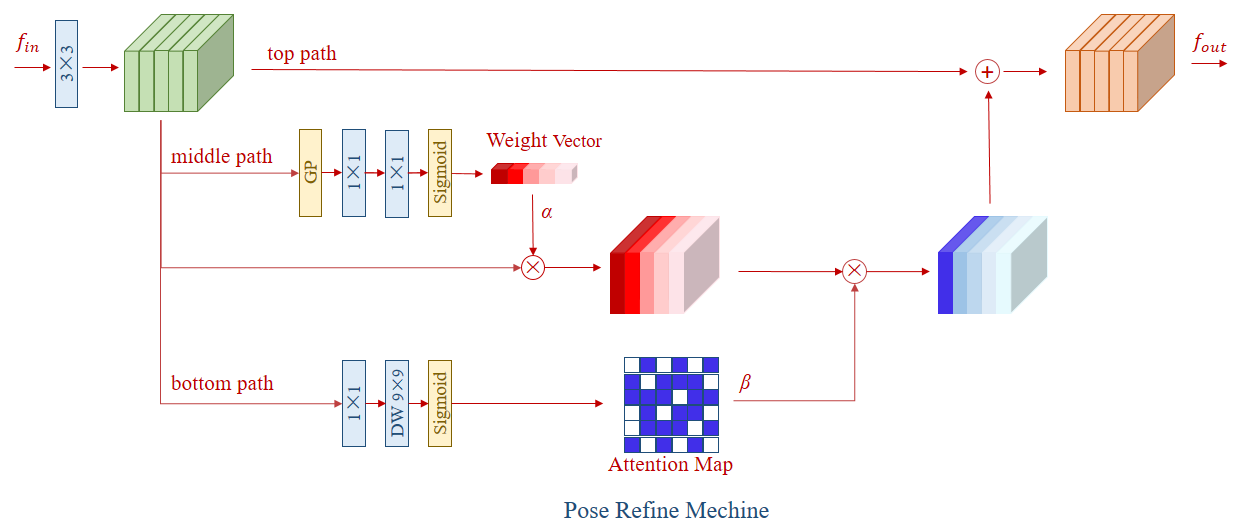
姿态优化机的架构
我们方法在COCO和MPII验证数据集上的一些预测结果


结果(原始版本)
COCO验证数据集上的结果
| 模型 | 输入尺寸 | GFLOPs | AP | AP<sup>50</sup> | AP<sup>75</sup> | AP<sup>M</sup> | AP<sup>L</sup> | AR |
|---|---|---|---|---|---|---|---|---|
| Res-18 | 256x192 | 2.3 | 70.7 | 89.5 | 77.5 | 66.8 | 75.9 | 75.8 |
| RSN-18 | 256x192 | 2.5 | 73.6 | 90.5 | 80.9 | 67.8 | 79.1 | 78.8 |
| RSN-50 | 256x192 | 6.4 | 74.7 | 91.4 | 81.5 | 71.0 | 80.2 | 80.0 |
| RSN-101 | 256x192 | 11.5 | 75.8 | 92.4 | 83.0 | 72.1 | 81.2 | 81.1 |
| 2×RSN-50 | 256x192 | 13.9 | 77.2 | 92.3 | 84.0 | 73.8 | 82.5 | 82.2 |
| 3×RSN-50 | 256x192 | 20.7 | 78.2 | 92.3 | 85.1 | 74.7 | 83.7 | 83.1 |
| 4×RSN-50 | 256x192 | 29.3 | 79.0 | 92.5 | 85.7 | 75.2 | 84.5 | 83.7 |
| 4×RSN-50 | 384x288 | 65.9 | 79.6 | 92.5 | 85.8 | 75.5 | 85.2 | 84.2 |
COCO测试开发数据集上的结果
| 模型 | 输入尺寸 | GFLOPs | AP | AP<sup>50</sup> | AP<sup>75</sup> | AP<sup>M</sup> | AP<sup>L</sup> | AR |
|---|---|---|---|---|---|---|---|---|
| RSN-18 | 256x192 | 2.5 | 71.6 | 92.6 | 80.3 | 68.8 | 75.8 | 77.7 |
| RSN-50 | 256x192 | 6.4 | 72.5 | 93.0 | 81.3 | 69.9 | 76.5 | 78.8 |
| 2×RSN-50 | 256x192 | 13.9 | 75.5 | 93.6 | 84.0 | 73.0 | 79.6 | 81.3 |
| 4×RSN-50 | 256x192 | 29.3 | 78.0 | 94.2 | 86.5 | 75.3 | 82.2 | 83.4 |
| 4×RSN-50 | 384x288 | 65.9 | 78.6 | 94.3 | 86.6 | 75.5 | 83.3 | 83.8 |
| 4×RSN-50<sup>+</sup> | - | - | 79.2 | 94.4 | 87.1 | 76.1 | 83.8 | 84.1 |
COCO测试挑战数据集上的结果
| 模型 | 输入尺寸 | GFLOPs | AP | AP<sup>50</sup> | AP<sup>75</sup> | AP<sup>M</sup> | AP<sup>L</sup> | AR |
|---|---|---|---|---|---|---|---|---|
| 4×RSN-50<sup>+</sup> | - | - | 77.1 | 93.3 | 83.6 | 72.2 | 83.6 | 82.6 |
MPII数据集上的结果
| 模型 | 分割 | 输入尺寸 | 头部 | 肩部 | 肘部 | 手腕 | 臀部 | 膝盖 | 脚踝 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| 4×RSN-50 | 验证 | 256x256 | 96.7 | 96.7 | 92.3 | 88.2 | 90.3 | 89.0 | 85.3 | 91.6 |
| 4×RSN-50 | 测试 | 256x256 | 98.5 | 97.3 | 93.9 | 89.9 | 92.0 | 90.6 | 86.8 | 93.0 |
结果(Pytorch版本)
COCO验证集结果
| 模型 | 输入尺寸 | GFLOPs | AP | AP<sup>50</sup> | AP<sup>75</sup> | AP<sup>M</sup> | AP<sup>L</sup> | AR |
|---|---|---|---|---|---|---|---|---|
| Res-18 | 256x192 | 2.3 | 65.2 | 87.3 | 71.5 | 61.2 | 72.2 | 71.3 |
| RSN-18 | 256x192 | 2.5 | 70.4 | 88.8 | 77.7 | 67.2 | 76.7 | 76.5 |
注意
- + 表示使用集成模型。
- 所有模型均在8块V100 GPU上训练。
- 我们使用自己原创的深度学习平台进行了所有实验,论文中的所有结果都是在这个平台上报告的。它与Pytorch之间存在一些差异。
仓库结构
本仓库的组织结构如下:
$RSN_HOME
|-- cvpack
|
|-- dataset
| |-- COCO
| | |-- det_json
| | |-- gt_json
| | |-- images
| | |-- train2014
| | |-- val2014
| |
| |-- MPII
| |-- det_json
| |-- gt_json
| |-- images
|
|-- lib
| |-- models
| |-- utils
|
|-- exps
| |-- exp1
| |-- exp2
| |-- ...
|
|-- model_logs
|
|-- README.md
|-- requirements.txt
快速开始
安装
-
参考[Pytorch网站][2]安装Pytorch。
-
克隆本仓库,并在**/etc/profile或~/.bashrc中配置RSN_HOME**,例如:
export RSN_HOME='/path/of/your/cloned/repo'
export PYTHONPATH=$PYTHONPATH:$RSN_HOME
- 安装依赖:
pip3 install -r requirements.txt
- 参考[cocoapi网站][3]安装COCOAPI,或者:
git clone https://github.com/cocodataset/cocoapi.git $RSN_HOME/lib/COCOAPI
cd $RSN_HOME/lib/COCOAPI/PythonAPI
make install
数据集
COCO
-
从[COCO网站][4]下载图片,并将train2014/val2014分别放入**$RSN_HOME/dataset/COCO/images/**。
-
从[Google Drive][6]或[百度网盘][10](提取码:fc51)下载ground truth,并放入**$RSN_HOME/dataset/COCO/gt_json/**。
-
从[Google Drive][6]或[百度网盘][10](提取码:fc51)下载检测结果,并放入**$RSN_HOME/dataset/COCO/det_json/**。
MPII
-
从[MPII网站][5]下载图片,并将图片放入**$RSN_HOME/dataset/MPII/images/**。
-
从[Google Drive][6]或[百度网盘][10](提取码:fc51)下载ground truth,并放入**$RSN_HOME/dataset/MPII/gt_json/**。
-
从[Google Drive][6]或[百度网盘][10](提取码:fc51)下载检测结果,并放入**$RSN_HOME/dataset/MPII/det_json/**。
日志
创建一个目录来保存日志和模型:
mkdir $RSN_HOME/model_logs
训练
进入指定的实验目录,例如:
cd $RSN_HOME/exps/RSN50.coco
然后运行:
python config.py -log
python -m torch.distributed.launch --nproc_per_node=gpu_num train.py
其中gpu_num是GPU的数量。
测试
python -m torch.distributed.launch --nproc_per_node=gpu_num test.py -i iter_num
其中gpu_num是GPU的数量,iter_num是你想要测试的迭代次数。
引用
如果我们的项目对您的研究有帮助,请考虑在您的出版物中引用它们。
@inproceedings{cai2020learning,
title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
booktitle={ECCV},
year={2020}
}
@inproceedings{cai2019res,
title={Res-steps-net for multi-person pose estimation},
author={Cai, Yuanhao and Wang, Zhicheng and Yin, Binyi and Yin, Ruihao and Du, Angang and Luo, Zhengxiong and Li, Zeming and Zhou, Xinyu and Yu, Gang and Zhou, Erjin and others},
booktitle={Joint COCO and Mapillary Workshop at ICCV},
year={2019}
}
编辑推荐精选


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。


TRELLIS
用于可扩展和多功能 3D 生成的结构化 3D 潜在表示
TRELLIS 是一个专注于 3D 生成的项目,它利用结构化 3D 潜在表示技术,实现了可扩展且多功能的 3D 生成。项目提供了多种 3D 生成的方法和工具,包括文本到 3D、图像到 3D 等,并且支持多种输出格式,如 3D 高斯、辐射场和网格等。通过 TRELLIS,用户可以根据文本描述或图像输入快速生成高质量的 3D 资产,适用于游戏开发、动画制作、虚拟现实等多个领域。


ai-agents-for-beginners
10 节课教你开启构建 AI 代理所需的一切知识
AI Agents for Beginners 是一个专为初学者打造的课程项目,提供 10 节课程,涵盖构建 AI 代理的必备知识,支持多种语言,包含规划设计、工具使用、多代理等丰富内容,助您快速入门 AI 代理领域。


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号