
augmentoolkit
AI开源领域特定数据生成解决方案
Augmentoolkit是一款开源AI工具,专门用于创建领域特定数据。它能将原始文本高效转化为高质量自定义数据集,适用于训练语言模型和分类器。该工具利用开源AI技术,无需依赖OpenAI,提供了易用、可定制和经济的数据生成方案。Augmentoolkit致力于简化LLM数据创建,使其成为模型开发中的便捷环节。




Augmentoolkit — 无限领域特定指令数据
您的定制LLM需要定制数据。Augmentoolkit可快速、廉价、轻松地创建高质量数据。
现在您可以使用开源AI将任何原始文本转换为用于训练新LLM(或分类器)的高质量自定义数据集。使数据收集成为模型创建过程中的轻松步骤。Augmentoolkit是易用、可定制、开源且经济高效的数据生成解决方案。无需OpenAI。
Augmentoolkit是一个AI驱动的工具,可让您使用开源AI创建特定领域的数据。

最新功能更新 — 2024年7月9日
Augmentoolkit现在可以在自定义数据上训练小型分类模型 — 在CPU上。基本上:
- LLM根据您提供的一小部分真实文本生成分类数据
- 分类器在LLM数据上训练
- 保存分类器并与LLM进行准确性评估
- 如果分类器不够好,添加更多数据并训练新的分类器。如果足够好,循环停止。
我使用这个流程在IMDb数据集上训练了一个情感分析distilbert模型,没有使用人工标签。它获得了88%的准确率 — 仅比使用人工标签训练的模型低约5%。
所以一个点击按钮就能运行的脚本几乎达到了斯坦福NLP艰苦努力的相同结果。这就是这个新流程的预期效用。
使用这个流程创建模型的成本可能只有一两美元,如果有的话。每个分类器的成本不到一杯咖啡。大规模制作分类器,让规模数据为您所用。
分类器创建器(名称可能会更改)的目标是使大规模数据分类和组织变得轻而易举。分类器通常被机器学习社区中更硬核的成�员使用,现在有了Augmentoolkit,您可以大规模创建它们。
要开始使用,请修改classifier_trainer_config.yaml并运行classifier_trainer_processing.py!
好了,回到您定期安排的README。
引用:

优势
Augmentoolkit让LLM数据变得简单。
- 低成本: Augmentoolkit使用开源LLM,因此可以在消费级硬件上几乎无成本运行,或通过Together.ai等API廉价运行。
- 轻松: 只需将一些文件放入文件夹,然后运行Python脚本即可使用Augmentoolkit。如果这太麻烦,您也可以使用图形用户界面。之前开始的运行会自动继续,因此您不必担心中断会浪费时间和/或金钱。
- 快速: 使用API时,您可以在一小时内生成数百万个可训练的标记。完全异步的代码让您能快速获得结果。
- 反幻觉,高质量数据: Augmentoolkit检查所有重要输出的幻觉和失败,确保每个生成的数据集始终保持高质量。精心设计的少样本示例强制使用的开源模型保持一致性和智能性。
我们还尽最大努力促进生成数据后的步骤 -- 训练您的LLM:
- 用一顿晚餐的价格训练AI: 使用提供的训练配置,您可以用极小的金额在自己的数据上执行相当于AI的完整微调。当然,VRAM使用因模型而异 -- 这可能对您有利。
- 一天内创建您的LLM: 使用合理的数据集大小和提供的训练配置,LLM训练可以在一天内完成。快速廉价地迭代。
- 使用相同的配方,就能得到相同的面包: Augmentoolkit�数据集已成功用于专业咨询项目。本README中链接的视频文档准确展示了如何使用此工具来实现相同的目标。您需要的代码、设置和提示都在这里。
- 自信地训练AI,特别是如果这是您的第一次: 借助视频文档和活跃的GitHub问题支持,您可以确信会从中获得一个好的LLM。
最后,使用您创建的模型应该简单且有价值:
- 将训练模型作为学习手段: 正在处理需要掌握的大型复杂主题?使用Augmentoolkit训练LLM可创建一个理解您试图弄清楚的大局的助手。我以前从我创建的AI中学到过东西,您 — 或您的用户/员工/客户 — 也可以。
- 有文档的LLM设置(包括RAG!): 从量化到聊天,第一次做这个可能需要30分钟按照提供的一步一步的视频说明(很简单!)来设置。第二次可能只需不到五到十分钟。这里非常重视教程。
Augmentoolkit现在还可以构建分类器。它们比LLM数据更便宜、更快,而且可以在本地计算机上训练。
演示视频和视频教程:
请注意,视频文档目前是为Augmentoolkit构建的,Augmentoolkit是为Verus社区构建的Augmentoolkit的姐妹项目。运行过程应该是相同的,训练LLM的过程肯定是相同的。但当提到"Augmentoolkit"和Verus项目时,这就是原因。
Augmentoolkit特定的视频文档正在制作中。
目录:
- 快速开始
- 自我推广(如果您是企业请阅读!)
- 愿景(介绍)
- 使用方法
- 如何使用输出结果
- 路线图
- 社区
- 最新更新信息
- 觉得这很酷?在其他地方与我联系!
- 贡献
- 加入数据集生成Discord!
- 使用"Aphrodite模式"(已弃用)
快速开始
终端
安装依赖后:
- 将仓库下载到有互联网连接的计算机上
- 安装其依赖(
pip install -r requirements.txt) - 打开
config.yaml - 将您的API密钥、喜欢的模型名称和首选AI服务的端点URL粘贴到
config.yaml内的相关字段中。务必保留引号。推荐:Together.ai与Hermes Mixtral作为LARGE_LOGICAL_MODEL和LOGICAL_MODEL效果非常好。 - 在命令行中打开此项目的文件夹,输入
python processing.py并回车(启动脚本版本)。
Web界面
- 安装依赖(
pip install -r requirements.txt) - 找到
raw_txt_input文件夹的绝对路径 - 运行
export GRADIO_TEMP_DIR=<raw_txt_input_absolute_path> - 运行
python app.py
面向企业
我与希望使用大量优质训练数据创建(或改进)专业大语言模型的初创公司和企业合作。您的企业需要AI数据集吗?或者您想将您自己拥有的AI模型应用到通用模型难以处理的领域吗?我很乐意帮助您轻松创建这种定制AI,以及用于构建更多此类AI的文档化工具。鉴于我创建了这个项目的原始版本,我可能是完成这项任务的最佳人选。您可以通过这个Calendly链接安排一个简短的通话,与我讨论您的需求:https://calendly.com/evanpeterarmstrong/discovery-call。
注意:Augmentoolkit的基础版本是完全开源的,采用MIT许可。咨询选项适用于那些想要快速获得定制修改和高质量结果的人(我花了5个月的学习和迭代才掌握开源模型管道,并在我现有的机器学习经验基础上使Augmentoolkit运作良好)。如果您是业余爱好者,有时间尝试其基础版本用于休闲或个人用途,那就尽管去做吧!
愿景
数据集创建一直是微调创建过程中最痛苦且最重要的步骤。 大多数人不得不求助于以下两种方法之一:A)消耗大量OpenAI API积分,或B)花费几十甚至上百个小时,根据您与机器人的对话累积混合数据集。OpenAI方法基于付费服务(您违反了其服务条款),它随时可能将您封禁,其写作风格您可能讨厌,而且每个月都在变差,其合成数据严重缺乏多样性。手写示例太慢,无法迭代,而且根本无法扩展,这意味着您错过了随数据增加而带来的巨大潜在性能提升。如果您是一家公司,为批量创建示例付费,那么可能比OpenAI还要昂��贵 - 同样完全无法扩展。而且,如果我们真的在创造能写作的机器,为什么我们还要花大部分时间写作呢?
Augmentoolkit旨在使高质量数据生成变得简单、快速、可共享、可配置,并适用于所有人。它旨在轻松创建关于任何以纯文本形式存在的知识的数据集。 它旨在让模型能够为自己生成额外的训练数据。它旨在让任何爱好者,无论计算能力如何,都能通过廉价生成大量数据来为AI的进步做出贡献。它旨在通过使数据收集变得像运行脚本一样简单来扩展可以构建的微调模型的可能性。无论您是在微调公司聊天机器人以理解您公司的信息,还是在创建能解释您使命和目标的社区AI大使,或者在做其他完全不同的事情,Augmentoolkit的存在都是为了让您的数据问题变得不那么棘手。
我们将使数据集创建成为创建新的大语言模型过程中最愉快、最强大和最灵活的部分。
目前您可以:
- 从书籍、文档或任何其他基于文本的信息源创建多轮对话式问答数据。
- 仅使用无监督、未标记的文本作为输入来训练文本分类器。成本几乎为零。达到非常接近使用人工标记数据训练的分类器的结果。
- 修改和调整提示或设置,使其完全适合您的特定用例 - 无需更改代码。
- 创建纯合成数据以调整大语言模型的写作风格(进行中)
Augmentoolkit主要操作(问答生成)的流程图可以在使用部分找到。关于分类器创建的信息可以在分类器部分找到。
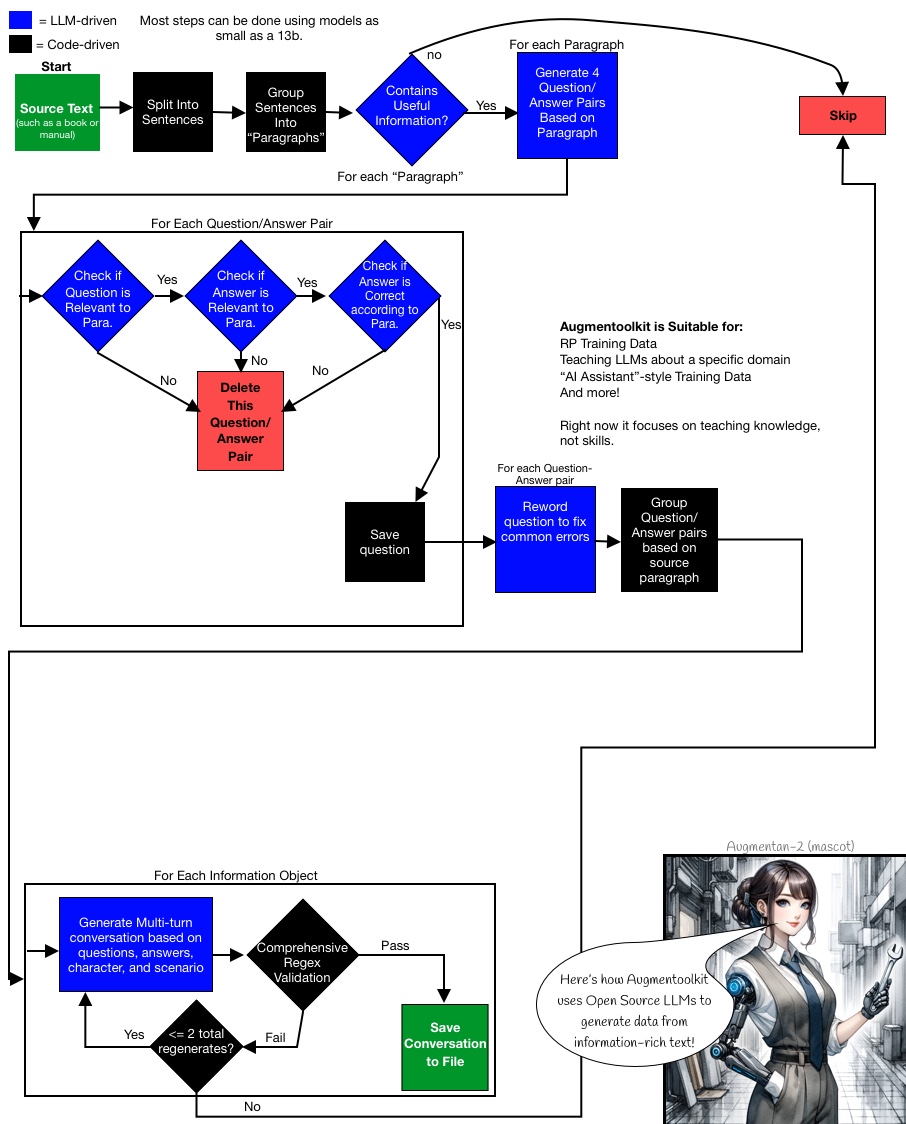
高层概述(对于Augmentoolkit的主要操作形式)是:输入书籍或手册,输出信息丰富的对话。用这些对话训练模型,它就学会了谈论这些信息。广泛的验证将幻觉保持在最低限度。与持续预训练相结合,可以教导模型谈论特定领域。
更深入和专业的解释: Augmentoolkit接受包含信息的人工编写文本,并将其转化为指令调优数据。基本上,它使用大语言模型将预训练数据转换为对话式多轮问答数据:
- 它接受输入文本,并将其分成块。
- 它使用每个块的信息生成测试该信息的问题,并生成使用该信息的答案。
- 它检查生成的问题和答案是否准确,并且只使用文本中提供的信息(确保大语言模型没有产生新的幻想信息)。
- 最后,它编写一个人类和AI之间的交互,其中人类提出问题,AI回答这些问题。
- 在检查这个对话是否忠实地包含了原始问题和答案后,结果被保存为新生成数据集的一部分。 您可以在使用部分看到这个过程的流程图。
然而,数据集生成不仅仅是关于问答。**Augmentoolkit已经扩展到能够从头开始训练分类器,**使用未标记的文本。只需向Augmentoolkit提供一些文本和一些类别的描述,您就能得到一个高质量的分类器,能够以真正大规模廉价处理数据。在分类器部分阅读更多关于分类器创建的信息。
使用方法
安装
首先,将仓库克隆到您的计算机上:
git clone https://github.com/e-p-armstrong/augmentool.git
然后,安装项目的依赖项。
pip install -r requirements.txt
您可能会收到一些消息,说torchvision和torchaudio需要较旧版本的Pytorch。这应该可以安全忽略。
如果您想在代码中使用Aphrodite,您还需要添加
pip install aphrodite-engine
但是,建议只在另一个窗口中运行您正在使用的本地推理引擎,并将其API端点放在config.yaml中,而不是使用内置的aphrodite模式。这种模�式现在可以被认为是过时的。
注意:对于大规模数据集生成,在Vast.ai或Runpod等服务上租用每小时几美元的GPU可能比使用Together.ai等API更具成本效益。然而,API更快且几乎不需要设置。因此,目前建议的流程是:使用API进行实验,使用租用的计算资源进行生产。
我将很快制作一个使用Augmentoolkit进行本地数据集生成的视频教程。
如果输出文件夹不为空,Augmentoolkit会继续之前开始的运行。如果您不是试图继续中断的数据集生成,请重命名或移动它。
Config.yaml,逐步说明
您可以通过修改config.yaml轻松自定义Augmentoolkit的特定运行方式。WebUI也有能力自定义设置。让我们逐一浏览YAML文件中的每个字段,以便您了解如何根据需要进行更改:
首先是API部分:
API:
API_KEY: 在此处输入您的密钥
BASE_URL: https://api.together.xyz
LARGE_LOGICAL_MODEL: meta-llama/Llama-3-70b-chat-hf
LOGICAL_MODEL: meta-llama/Llama-3-70b-chat-hf
QUANTIZATION_SMALL: "gptq"
QUANTIZATION_LARGE: "gptq"
逐个字段解释:
API_KEY这是您放置喜欢的API提供商的API密钥的地方。如果您正在运行本地服务器,请在此处放置一个虚拟值,以便请求的格式不会破坏。BASE_URL这是您使用的API提供商的基本URL。一些可能的值:- http://127.0.0.1:5000/v1/ <- 本地模型。
- https://api.together.xyz <- together.ai,以低价提供高质量的开源模型。但他们的服务有时存在可靠性问题。
- https://api.groq.com/openai/v1 <- Groq。他们免费提供API,但有低速率限制。
- https://api.openai.com/v1/ # <- OpenAI
- 任何其他接受OAI风格请求的API,基本上是市面上的任何API(openrouter, fireworks等)
LARGE_LOGICAL_MODEL您想使用的大型模型的名称。这个模型将用于最后的生成步骤。这应该是一个相当强大的模型。用于驱动Augmentoolkit的模型被分为两个模型,以在管道早期的较简单步骤中节省成本。(如果您使用的是本地服务器,这个字段可能无关紧要。)LOGICAL_MODEL您想用于前几个生成步骤的模型的名称。它可以是一个相当便宜的模型,但更强大的模型仍会产生更好的最终输出。QUANTIZATION_...如果您在Aphrodite模式下运行,请更改这些。方法(例如,"gptq","awq")必须与所使用的模型量化类型匹配。_SMALL设置LOGICAL_MODEL的量化类型,而_LARGE设置LARGE_LOGICAL_MODEL的类型。**如果Augmentoolkit不处于Aphrodite模式,这个设置不起作用,可以忽略(无论如何,aphrodite模式已经过时,因为作为本地服务器运行比使用其代码更好)。 接下来是PATH部分:
PATH:
INPUT: "./raw_text_input_vision_paper"
OUTPUT: "./output"
DEFAULT_PROMPTS: "./prompts"
PROMPTS: ./prompts_vision_paper
逐项说明:
INPUT是存储原始文本输入的文件夹的相对路径。这个文件夹包含你想要作为管道输入的文本文件。文件可以是任何格式,部分文件甚至可以嵌套在子文件夹中,因此在处理新的数据源时几乎不需要进行清理工作。OUTPUT是存储管道输出的文件夹的相对路径。这个文件夹将包含由管道生成的数据集文件(.jsonl),以及一个配套的持续预训练数据集。中间生成的内容(用于调试或可解释性)也会存放在这里。DEFAULT_PROMPTS是存储 Augmentoolkit 核心提示的文件夹的相对路径。这个文件夹包含整个管道中使用的提示文件。如果在PROMPTS文件夹中找不到提示,Augmentoolkit 将使用DEFAULT_PROMPTS作为备用文件夹。PROMPTS是存储当前运行 Augmentoolkit 所用提示的文件夹的相对路径。与DEFAULT_PROMPTS相比,PROMPTS本质上是一个覆盖:如果在PROMPTS文件夹中找到了提示,它将被使用,而不是DEFAULT_PROMPTS文件夹中同名的提示。这允许你为原始提示可能不太适合的新类型输入数据创建不同的提示。参见prompts_code_override和prompts_vision_paper_override以了解如何使用。
接下来是 SYSTEM 部分:
SYSTEM:
CHUNK_SIZE: 1900
USE_FILENAMES: False
COMPLETION_MODE: false
CONCURRENCY_LIMIT: 60
DOUBLE_CHECK_COUNTER: 1
FINAL_ASSISTANT_PROMPT_NO_RAG: |
你是一个乐于助人、友好的AI助手。
FINAL_ASSISTANT_PROMPT_RAG: |
你是一个乐于助人、友好的AI助手。
上下文信息如下:
----------------------
{data}
MODE: api
STOP: true
SUBSET_SIZE: 10
USE_SUBSET: true
逐项说明:
CHUNK_SIZE是将通过管道传递的文本"块"的最大字符数。一个块是生成问题的基础 —— 它是 Augmentoolkit 构建的问答数据集的核心构建块。USE_FILENAMES决定了AI在生成问题时是否允许看到每个文本/信息块所来自的文件名。如果开启,问题可能经常会采用"根据文件Y,X是什么?"的格式。如果你的文件是书籍,这可能很有用 —— 例如,你可能会得到"根据OSS的《简单破坏》,如何破坏一辆汽车?"而如果关闭,问题可能只是"如何破坏一辆汽车?"如果你希望机器��人有一些元知识,这很好,但通常应该关闭。如果你希望AI知道文件的作者,那么将名称格式化为"文本名称,作者名称"。逗号很重要。COMPLETION_MODE是一个布尔值,决定是以聊天模式(默认,设置为false时)还是完成模式(设置为true时)向提供者发送提示。完成模式可能在某些模型上产生更高质量的响应,但许多提供者不支持它。CONCURRENCY_LIMIT是一个整数;它是可以向提供者同时发出的最大请求数。这对于控制成本和防止频率限制很有用。DOUBLE_CHECK_COUNTER是一个整数;它是管道将对生成的问题进行双重检查的次数。对于每个问答对,采取多数票:如果是正面的,保留问答对;如果是负面的,丢弃问答对。平局则丢弃。这是一个权衡参数:更高意味着更高质量但成本远高。3是一个好的起点。FINAL_ASSISTANT_PROMPT_NO_RAG是用于控制最终生成的数据集形式的设置。你在这里写的内容将成为数据集中不使用RAG支持输出部分的AI系统提示。这是我们让LLM依赖我们教授的知识的地方。FINAL_ASSISTANT_PROMPT_RAG与其NO_RAG表亲类似,但用于数据集中使用RAG支持输出的部分。这是我们让LLM结合理解和检索信息来产生答案的地方。一个关键区别:{data}出现的地方,它将被数据集中每个样本的RAG上下文替换。所以将它放在你希望上下文出现在提示中的位置。MODE是管道将运行的模式。api是默认模式,用于运行支持OpenAI标准的API的管道。也支持cohere,用于运行Cohere API的管道(在cohere模式下BASE_URL无效)。STOP是一个布尔值,决定管道是否使用停止标记。除非你使用的API��任意限制了可以使用的停止标记数量(如OpenAI),否则你应该始终将其设置为true。SUBSET_SIZE控制如果USE_SUBSET开启时通过管道传递的块数。这对于快速和低成本地调试和测试很有用 —— 只会处理前SUBSET_SIZE个块。USE_SUBSET是一个布尔值,决定管道是否使用输入数据的子集。
注意:
SKIP:
QUESTION_CHECK: False
ANSWER_RELEVANCY_CHECK: True # 如果使用负面问题提示覆盖,则开启
这让你可以控制是否想跳过管道的某些步骤。在任何情况下,通常都不应该跳过QUESTION_CHECK,但如果你使用"负面"提示覆盖(默认位于 ./prompts_override_negative_question),则可以跳过ANSWER_RELEVANCY_CHECK。因此,如果你想简单地跳过相应的步骤,就开启其中任何一个。这些选项允许一定程度的控制流控制,而无需触及代码。
分类器创建器
新功能!
分类器创建器让你能在几分钟内训练一个完整的分类模型。生成可以在本地或通过API完成,而模型训练则在CPU上本地完成(分类器训练就是这么简单!)
什么时候你需要一个分类器?也许你想浏览一个数据集并将数据分类为"高质量"或"低质量",然后只训练高质量的数据。或者,你可能想为一个应用程序制作一些自定义审核。又或者,你可能想在大量文本中搜寻特定类型的信息。分类器是老派的,但它们仍然很酷,而且出人意料地有用。
以下是运行它的方法(快速入门)。
pip install -r requirements.txt
然后,修改 classifier_trainer_config.yaml 以包含正确的API密钥和基本URL。
接着,从Hugging Face下载IMDb数据集:
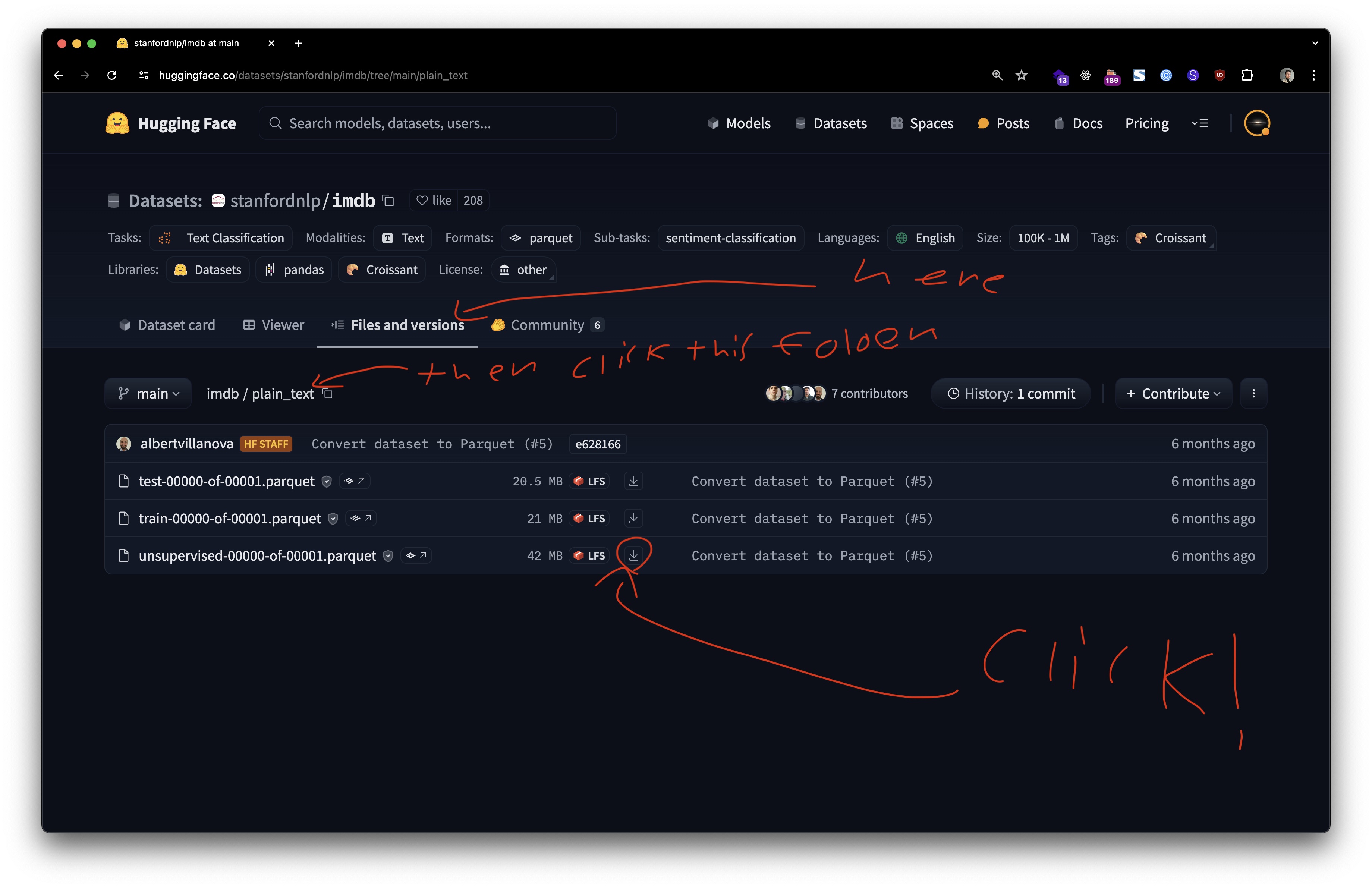
并将其放入 classifier_trainer_config.yaml 文件指向的"input"文件夹中。
然后运行:python classifier_trainer_processing.py
这个新管道的提示可以在 prompts_classifier 中找到。
大多数 config 设置与普通的Augmentoolkit相同,但以下是不同之处:
-
LOGICAL_MODEL在此流程中,LOGICAL_MODEL 负责大部分用于构建自定义分类器训练数据的分类工作。像 Llama 3 8b 这样的模型效果很好。 -
LARGE_LOGICAL_MODEL用于:1) 创建 LLM 分类器遵循的"规则"(基于您对任务的描述和类别含义)。大型逻辑模型还用于在模型评估阶段进行分类,以确保分类器质量高,不只是学习小型模型的愚蠢行为。 -
在
SYSTEM标题下的REQUIRED_ACCURACY: 0.90,这个字段(小于1)是训练后的分类器模型必须"正确"(与 LLM 分类相比)的分类百分比,以通过并跳出持续改进循环。根据您选择的分类器模型和任务,您可能需要将其设置得稍低一些——有些可能相当小。 -
CLASSIFICATIONCLASSES是一个字符串列表,包含模型将用于对文本进行分类的类别名称。例如,["negative", "positive"]。这些在实际训练数据中将分别显示为0和1。此流程的早期版本仅支持二元分类(2个类别),但它的构建方式使得未来添加更多类别相对容易,所以请期待这一功能的到来。DESC是一个描述类别含义的字符串。比如"分类文本(电影评论)是正面还是负面。"或"文本是否表达了积极或消极情绪。"或如果文本明显是元数据、目录、出版信息、版权信息——任何不是书籍或文章实际内容的部分,将其分类为元数据。如果明显是有实际意义的内容,将其分类为内容。如果包含两者,则分类为元数据。PREDICT_ON_WHOLE_SET_AT_THE_END是一个布尔值,决定是否在最后对整个输入文本运行新训练的分类器。如果您向 Augmentoolkit 提供的数据与您最终想要分成两个不同类别的数据相同,请打开此选项。
TRAINING:
MODEL_PATH是您想要训练分类器的 Hugging Face 模型路径。此流程在distilbert-base-uncased上经过测试。TRAIN_SET_SIZE首次训练运行要采用的块数。一个不错的默认值是 500。TRAIN_SET_INCREMENT每次分类器未能匹配 LLM 性能时要添加的新块数。TEST_SET_SIZE评估新分类器性能与 LLM 对比时采用的测试样本数。分类器与 LLM 一致的次数决定准确率分数。TRUNCATION_TYPE某些块对于分类器模型的上下文长度来说太大。因此您可以进行截断。选项有:head-tail(取前几个 token 和末尾的一堆 token);end truncation(切断块大小末尾不适合的多余内容)MAX_ITERS为避免陷入无限花钱循环,在这里设置一个整数,标记将执行的数据生成+训练运行的最大次数。请注意,分类器创建器比 Augmentoolkit 便宜得多,所以这个值可以设置得相当高而无需担心。5
注意,分类器创建器还可以接受 .json、.jsonl 和 .parquet 文件作为输入,前提是它们有一个"text"列!这让您可以使用 Hugging Face 上的现成数据集,如 Enron 邮件 或 FineWeb!
主要区别一览:
- 分类器创建器制作一个小型分类器模型,可以廉价地在大量数据上运行,将其分类
- 分类器创建器使用 LLM 和强大的少样本提示来教导分类器任何类型的分类任务
- 分类器创建器持续工作直到达到特定的准确率阈值
- 使用分类器创建器制作的数据集训练的模型似乎与使用人工标注数据训练的模型性能非常相似
- 然而,分类器创建器只需一两美元就能生成分类器——如果您使用 API 的话。如果是本地运行,甚至更便宜。
- 分类器创建器接受 .txt、.md、.json、.jsonl 和 .parquet 文件。JSON、JSONL 和 Parquet 文件必须有一个"text"列。这确保了与大多数自然文本以及 Hugging Face 上的许多数据集的兼容性。
- 分类器可用于在大型数据集中查找优质数据,或识别具有特定特征的数据(例如,如果您需要阅读大量文档来查找某些内容),或作为更大的 AI 驱动系统的一部分部署(如用于审核或分析)。
如果您对新流程或 Augmentoolkit 有任何问题,请随时联系我!我的联系方式在此仓库底部。
重要文件(如果您要修改代码)
从常见到不常见的顺序排列:
processing.py是运行流程的主文件。它定义了流程的核心控制流程。control_flow_functions.py是定义流程使用的大量辅助函数的地方。这里定义了参数、采样参数以及每个单独步骤的控制流程。它与processing.py的区别在于processing.py是整个流程的控制流程,而control_flow_functions.py主要是每个单独步骤的控制流程。这里定义了输出处理器——如果您更改了提示并遇到生成失败��问题,这里是您需要查看的地方。 查看parse_validation_step可以了解输出处理器的示例,基本上它将 LLM 响应作为输入并返回一个问答对。engine_wrapper_class.py包含一个类,作为许多不同 LLM API 的单一接口。如果您想使用不兼容 OpenAI 的其他 API 提供商,这里是需要更改代码的地方。generation_step_class包含一个存储单个生成步骤参数的类。生成步骤基本上保存一些采样参数、一个提示和一个引擎包装器,并可以用这些设置调用该引擎包装器。通常,如果您在修改步骤后遇到错误,您会更改此处以添加额外的日志记录——Augmentoolkit 中 LLM 调用的工作方式是创建一个带有提示路径和一些采样参数的生成步骤对象,然后用特定调用 LLM 的参数调用该对象的 .generate() 方法。generation_functions文件夹中还有一些其他杂项实用函数。app.py包含 gradio WebUI 代码。这是图形界面。字段基于config.yaml。
步骤的可视化解释
这里是一个流程图,详细说明了 Augmentoolkit 典型运行的进行方式。源文本可以是任何包含可以提问的信息的内容。
如何使用生成的内容
在您的 OUTPUT 文件夹中需要注意的重要文件是 simplified_data_no_rag.jsonl、simplified_data_rag.jsonl 和 pretraining.json。这些是您最常用于训练的文件。其他顶级文件是为了提供更多信息,比如每个对话生成自哪个文件的哪个块。但对于训练,您需要 simplified_data_no_rag.jsonl、simplified_data_rag.jsonl 和 pretraining.json。它们都已经格式化,可以与开源训练库 Axolotl 一起使用。您只需像使用 _model_training_configs/ 中提供的配置那样使用这些数据集即可。
对话文件的格式称为"shareGPT",这是许多数据集中常见的格式。然而,pretraining.json 被格式化为预训练数据。要将事实信息融入 LLM,建议您使用完整微调或(更便宜的)GaLore 调优,结合对源文本和 Augmentoolkit 生成的指令数据进行持续预训练。如果您想要更详细的示例,请查看提供的配置,或 视频文档 的第二个视频。
在最近的更新中,Augmentoolkit 增加了从问题生成、输入块过滤和对话生成中获取数据的功能。这些可以通过文件名中含有 _DATAGEN_OUTPUT 的 .jsonl 文件识别。当您查看其中一个文件时,您就会明白它们具体是什么。
它们采用 ShareGPT 格式,便于训练,可以用作更多样化的数据来充实训练运行。它们还可以用来制作专门作为 Augmentoolkit 一部分运行的 LLM 专家——在足够多的这些数据上训练模型,您将获得一个强大的本地推理工具。
路线图
在未来几周和几个月内,Augmentoolkit 将扩展更多的流程、功能和更新。我正在与 AlignmentLab AI 合作进行其中一些工作!
即将推出的一个特定流程是超长上下文指令数据。如果您想看到其他类型的流程,请告诉我,我也会添加它们!
你有数据生成或数据清洗的代码吗?我欢迎添加新管道的PR!你只需要做以下几件事:1)确保它有某种形式的 config.yaml 文件用于设置,2)确保它有自己的脚本(如 processing.py),3)将任何实用函数放在 augmentoolkit/ 目录中。
让我们一起打造世界上最好的数据生成工具!
社区
修改Augmentoolkit通常需要大量提示开源LLM。这和许多其他AI开发方面一样,都很难掌握。我正在建立一个社区,让这一切变得简单。
这个社区不是典型的虚假大师"AI工具"炒作。它是由开发者为开发者服务的。
目前我们有一个完整的开源提示视频课程,每周进行AI开发问答,还可以选择与我进行每月一对一交流,我会尽力帮助你的项目。这里有一群志同道合的专业人士和爱好者。
我很乐意邀请你加入。点击这个链接查看登陆页面,看看是否有兴趣加入。
最新更新信息
截至2024年6月12日,Augmentoolkit进行了重大更新。两个全新的提示覆盖文件夹让你可以生成旨在使模型更智能和更详细的数据,同时在预训练中获得更多指令数据。根据来之不易的经验进行了调整,以优化最终模型质量。提示的全面改革使管道更加灵活和强大。现在使用YAML而不是JSON来处理提示,因为它支持换行。在 ./pure_synthetic_pipeline 中可以找到一个全新数据生成程序的早期版本,该程序甚至可以在没有任何文本输入的情况下创建数据集。对常见错误有了更好的日志记录。哦,而且代码几乎完全重构了!
在最近的更新中,RP模式被移除。如果你需要,可以回退到之前的版本。因此,代码现在更加清晰,更易于维护。
这些变更中的许多灵感来自于最近发布的Verustoolkit,这是我为(并作为)Verus社区开发的。Verustoolkit专门针对Verus,但它是开源的,所以我将其关键改进移植到了这里。如果你对区块链技术的未来感兴趣,去看看吧!
觉得这很酷?在别处�与我联系!
如果你认为这个项目很酷很有用,太好了!我真诚地为你对我的工作感兴趣而高兴。如果你对这个项目非常感兴趣,你可能也会对我的其他一些endeavors感兴趣:
- 一个关于提示工程开源模型的通讯/博客 — 这是Augmentoolkit和类似复杂LLM项目背后的艺术和科学。如果你好奇的话,我还提供提示工程咨询。
- 我有时在X/Twitter上发帖,有时加入讨论空间
- 让我们在LinkedIn上连接!
- 我在TheBloke的Discord服务器和许多其他AI Discord上都很活跃。找我@heralax!
- 顺便说一下,我提到我做咨询吗?:) 我也许能帮助你的AI业务变得更好,使用Augmentoolkit或直接提示。我们至少应该聊聊天并建立联系
- 给我发邮件:evanpeterarmstrong@gmail.com
贡献
欢迎贡献!无论是新的API端点,还是你发现效果很好的一组提示,或者是一个全新的管道,请提交PR!这里的审核很快。任何能够进一步推动民主化数据集生成目标的内容都受欢迎。
加入数据集生成Discord!
MrDragonFox — Mistral和TheBloke Discord的一位管理员 — 有一个服务器,他正在那里开发一个新的量化引擎。那里有一个讨论Augmentoolkit的角落!来看看并在https://discord.com/invite/foxengine-ai上连接吧!
本地生成
本地生成的一个限制是你一次只能运行一个模型。Augmentoolkit通常使用两种不同的模型:一个小模型用于大量工作,一个大而智能的模型用��于困难任务。如果你想在本地高效生成,你需要使用 config.yaml 中的 PHASE 选项。WORK_IN_PHASES 将被打开,PHASE_INDEX 应根据你的数据集生成运行进度设置。阶段索引0 = 过滤掉没有相关上下文的块,使用小模型;索引1 = 问题生成,使用大模型;索引2 = 问题验证,使用小模型;索引3 = 上下文修订和对话生成,最后阶段,使用大模型。
启动你的本地openai兼容LLM服务器,使用较小的模型。将配置设置为:
PHASE:
WORK_IN_PHASES: True
PHASE_INDEX: 0
设置好所有其他设置(输入文本,base_url等),然后运行 processing.py。当完成后,将配置改为:
PHASE:
WORK_IN_PHASES: True
PHASE_INDEX: 1
重启你的本地LLM服务器以使用更大更强大的LLM。然后再次运行 processing.py — 由于Augmentoolkit的自动恢复功能,它会从你离开的地方继续。当该步骤完成后,将配置设置为
PHASE:
WORK_IN_PHASES: True
PHASE_INDEX: 2
让你的本地LLM服务器使用小模型。最后,一旦完成,用大模型运行第3阶段:
PHASE:
WORK_IN_PHASES: True
PHASE_INDEX: 3
这个过程取代了之前更繁琐的本地推理方法。现在,你可以从配置中管理它。 如果你想设置后就不管它,你可以接受使用更强大模型的较长生成时间,这不会影响你。
为了加快生成速度并提高成本效率,最好使用Runpod.io或类似的GPU租赁服务(推荐2个H100或8个A40)。对于大规模数据集生成任务,这可能比使用API更便宜,而且不会遇到消费级硬件有时会遇到的痛苦的生成速度问题。
祝你数据集生成愉快!现在数据终于成为了一个简单的过程,尽情享受制作精彩的自定义模型吧。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多�种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提��升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号