
 Github
Github 文档
文档 论文
论文从离散解耦自监督表示中重新合成语音
从离散解耦自监督表示中重新合成语音中描述的方法的实现。
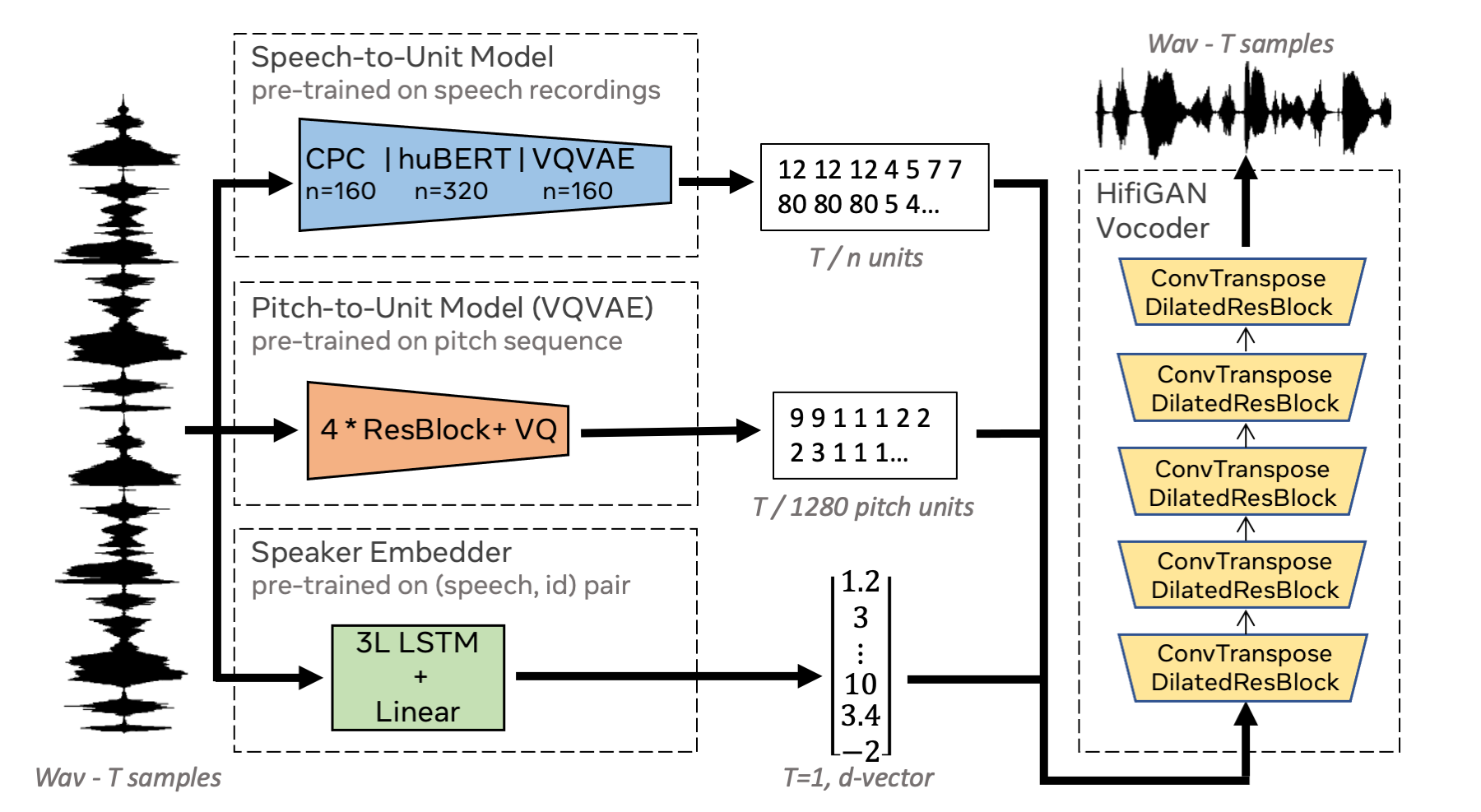
摘要:我们提出使用自监督离散表示来完成语音重新合成的任务。为了生成解耦表示,我们分别提取语音内容、韵律信息和说话者身份的低比特率表示。这允许以可控的方式合成语音。我们分析了各种最先进的自监督表示学习方法,并阐明了每种方法在考虑重建质量和解耦属性时的优势。具体而言,我们评估了F0重建、说话者识别性能(用于重新合成和声音转换)、录音的可理解性,并使用主观人工评估来评估整体质量。最后,我们演示了如何将这些表示用于超轻量级语音编解码器。使用获得的表示,我们可以达到每秒365比特的速率,同时提供比基线方法更好的语音质量。
快速链接
设置
软件
要求:
- Python >= 3.6
- PyTorch v1.8
- 安装依赖
git clone https://github.com/facebookresearch/speech-resynthesis.git cd speech-resynthesis pip install -r requirements.txt
数据
对于LJSpeech:
- 从这里下载LJSpeech数据集到
data/LJSpeech-1.1文件夹。 - 将音频从22.05 kHz降采样到16 kHz并进行填充
bash python ./scripts/preprocess.py \ --srcdir data/LJSpeech-1.1/wavs \ --outdir data/LJSpeech-1.1/wavs_16khz \ --pad
对于VCTK:
- 从这里下载VCTK数据集到
data/VCTK-Corpus文件夹。 - 将音频从48 kHz降采样到16 kHz,修剪尾部静音并进行填充
python ./scripts/preprocess.py \ --srcdir data/VCTK-Corpus/wav48_silence_trimmed \ --outdir data/VCTK-Corpus/wav16_silence_trimmed_padded \ --pad --postfix mic2.flac
训练
F0量化器模型
要训练F0量化器模型,使用以下命令:
python -m torch.distributed.launch --nproc_per_node 8 train_f0_vq.py \
--checkpoint_path checkpoints/lj_f0_vq \
--config configs/LJSpeech/f0_vqvae.json
将<NUM_GPUS>设置为您机器上可用的GPU数量。
重新合成模型
要训练重新合成模型,使用以下命令:
python -m torch.distributed.launch --nproc_per_node <NUM_GPUS> train.py \
--checkpoint_path checkpoints/lj_vqvae \
--config configs/LJSpeech/vqvae256_lut.json
支持的配置
目前,我们支持以下训练方案:
| 数据集 | SSL方法 | 字典大小 | 配置路径 |
|---|---|---|---|
| LJSpeech | HuBERT | 100 | configs/LJSpeech/hubert100_lut.json |
| LJSpeech | CPC | 100 | configs/LJSpeech/cpc100_lut.json |
| LJSpeech | VQVAE | 256 | configs/LJSpeech/vqvae256_lut.json |
| VCTK | HuBERT | 100 | configs/VCTK/hubert100_lut.json |
| VCTK | CPC | 100 | configs/VCTK/cpc100_lut.json |
| VCTK | VQVAE | 256 | configs/VCTK/vqvae256_lut.json |
推理
要生成,只需运行:
python inference.py \
--checkpoint_file checkpoints/vctk_cpc100 \
-n 10 \
--output_dir generations
要合成多个说话者:
python inference.py \
--checkpoint_file checkpoints/vctk_cpc100 \
-n 10 \
--vc \
--input_code_file datasets/VCTK/cpc100/test.txt \
--output_dir generations_multispkr
您还可以使用来自不同数据集的代码进行生成:
python inference.py \
--checkpoint_file checkpoints/lj_cpc100 \
-n 10 \
--input_code_file datasets/VCTK/cpc100/test.txt \
--output_dir generations_vctk_to_lj
预处理新数据集
CPC / HuBERT编码
要使用CPC或HuBERT对新数据集进行量化,请按照GSLM代码中描述的说明进行操作。
解析CPC输出:
python scripts/parse_cpc_codes.py \
--manifest cpc_output_file \
--wav-root wav_root_dir \
--outdir parsed_cpc
解析HuBERT输出:
python parse_hubert_codes.py \
--codes hubert_output_file \
--manifest hubert_tsv_file \
--outdir parsed_hubert
VQVAE编码
首先,您需要下载LibriLight数据集并将其移动到data/LibriLight。
对于VQVAE,使用以下命令训练vqvae模型:
python -m torch.distributed.launch --nproc_per_node <NUM_GPUS> train.py \
--checkpoint_path checkpoints/ll_vq \
--config configs/LibriLight/vqvae256.json
提取VQVAE代码:
python infer_vqvae_codes.py \
--input_dir folder_with_wavs_to_code \
--output_dir vqvae_output_folder \
--checkpoint_file checkpoints/ll_vq
解析VQVAE输出:
python parse_vqvae_codes.py \
--manifest vqvae_output_file \
--outdir parsed_vqvae
许可证
您可以在这里了解更多关于许可证的信息。
引用
@inproceedings{polyak21_interspeech,
author={Adam Polyak and Yossi Adi and Jade Copet and
Eugene Kharitonov and Kushal Lakhotia and
Wei-Ning Hsu and Abdelrahman Mohamed and Emmanuel Dupoux},
title={{Speech Resynthesis from Discrete Disentangled Self-Supervised Representations}},
year=2021,
booktitle={Proc. Interspeech 2021},
}











