



语音数据集工具2
简介
这是一个用于快速制作语音数据集的工具,可以一键导出VITS等项目所需的训练数据集
注意:您正在查看项目的r1.0分支,该分支将停止更新新功能,仅作维护和存档用途,未来项目经过重构后将以r2.0分支为主
特点:
图形用户界面!
中文文档
支持两种数据导入方式:音频+字幕和纯音频自动切割(未来会增加更多)
自动优化音频切割效果,(尽量)避免出现断音
可直接导出符合VITS等项目要求的数据集格式,可设置声道数和采样率
引入语音评测功能,通过为数据打分可以快速从海量数据中筛选出高质量数据集
软件架构
数据库:sqlite、peewee
界面:PySide6
音频处理:FFMPEG、pydub等
安装指南
运行编译好的exe文件
访问GitHub的Release页面或Gitee的发行版页面,根据提示下载相应的压缩包,双击即可启动程序
从源代码运行
-
克隆本项目
Gitee:
git clone https://gitee.com/kslizi/sound_dataset_tools2.gitGitHub:
git clone https://github.com/kslz/sound_dataset_tools2.git -
安装ffmpeg
您可以通过配置环境变量,也可以将下载的ffmpeg压缩包解压后,在exe根目录下新建lib文件夹,将解压得到的bin文件夹改名为ffmpeg,然后复制到lib目录下。最终的目录结构如图所示
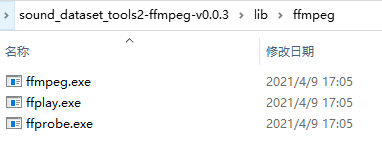
-
安装其他库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
使用说明
运行项目
python main.py
选择工作区
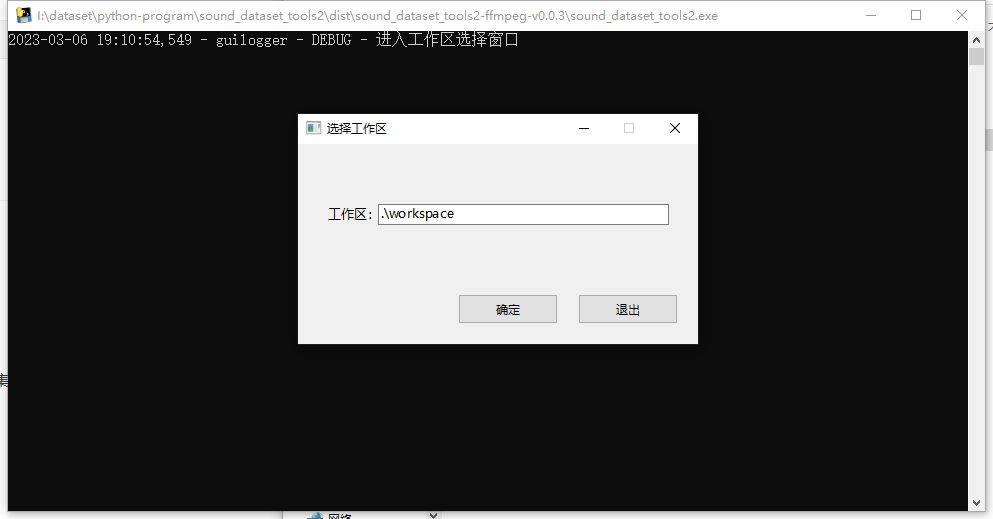
如果当前目录空间不足,可以指定其他目录。导入的文件、数据库、生成的数据集都会存放在指定目录中
数据集选择界面
您可以在这里添加、修改、删除数据集。每个数据集之间互相独立。点击"进入"按钮,进入数据集。
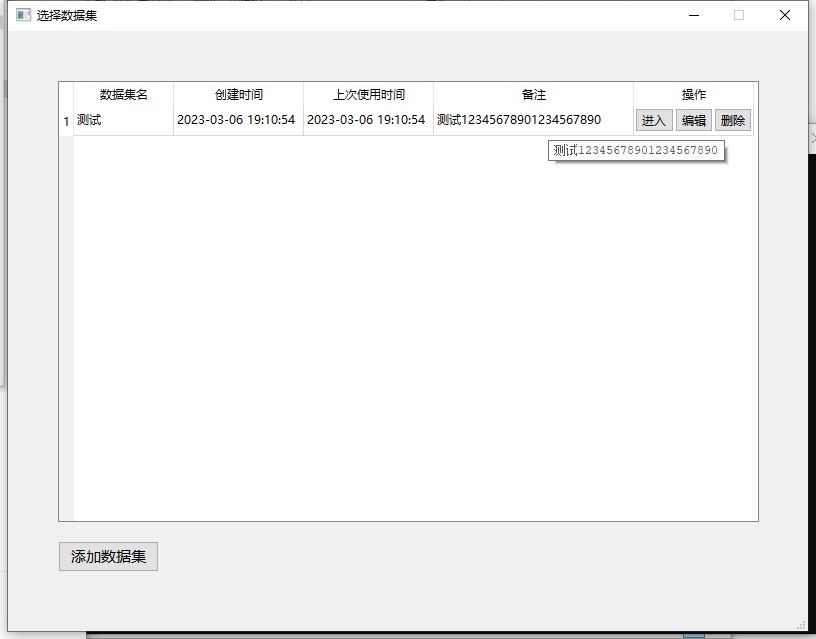
数据集概览界面
在此您可以对数据进行导入、导出、处理等操作
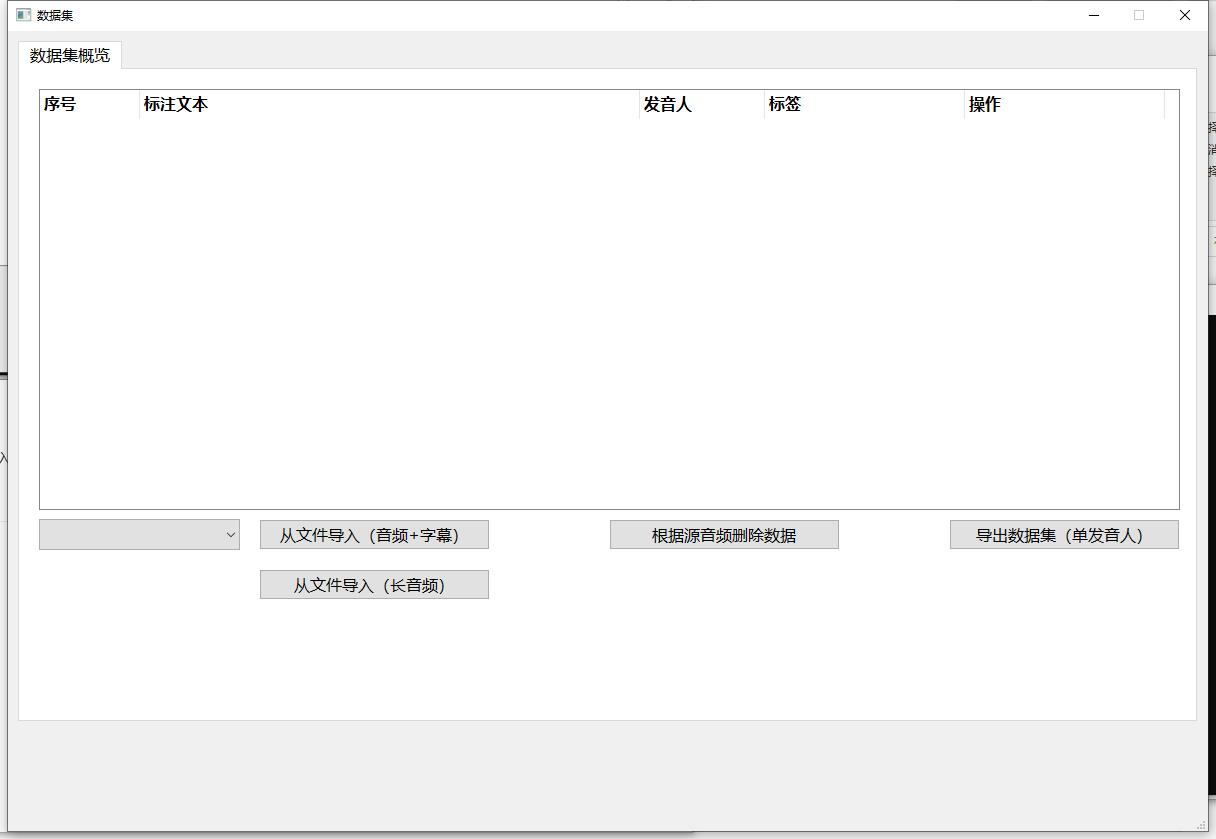
导入数据
注意:所有导入数据的方式都经过了自动优化,关于自动优化的具体逻辑请参见文末。
从文件导入(音频+字幕)
点击按钮,在弹窗中选择预先处理好的音频和字幕文件,支持视频文件和几乎所有(ffmpeg支持的)格式的音频文件导入,同时请输入发音人。关于字幕的获取请参见文末。
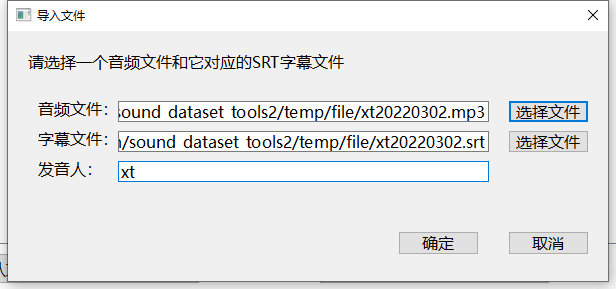
导入后的界面如图所示,您可以在左侧的下拉框中选择翻页,也可以点击试听音频段
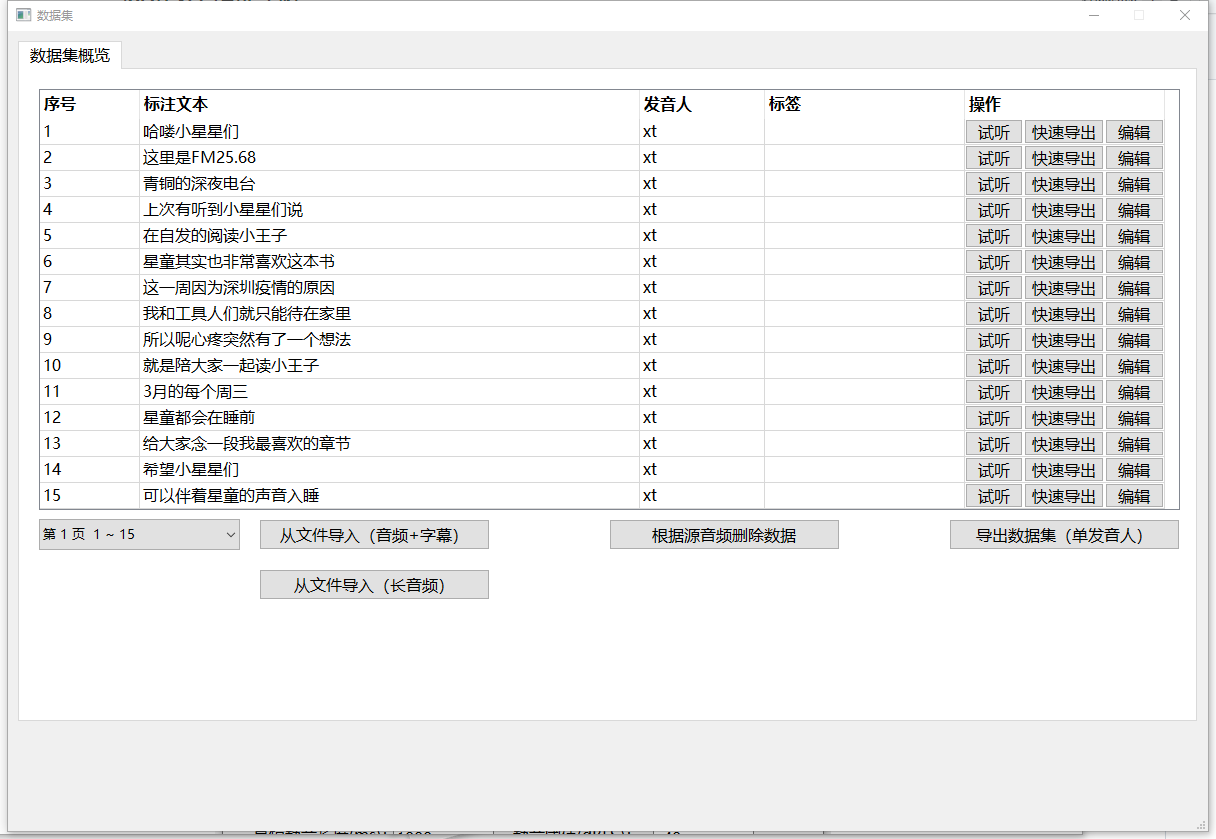
点击快速导出后会将当前音频导出至 .\workspace\output\fastoutput\ 目录下
从文件导入(长音频)
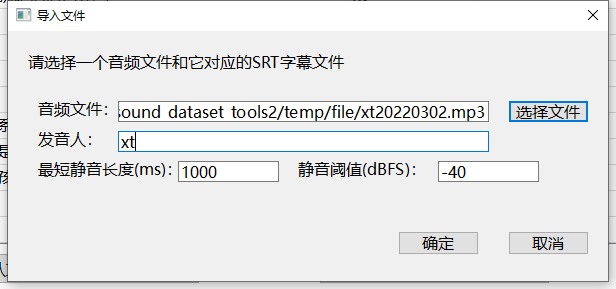
点击按钮,在弹窗中选择预先处理好的音频文件,支持视频文件和几乎所有(ffmpeg支持的)格式的音频文件导入,同时请输入合适的发音人、最短静音长度、静音阈值信息
最短静音长度:当静音长度达到这个数值时进行一次裁切
静音阈值:当音频响度低于这个数值时则视为静音,如果您的音频底噪很低,可以适当调低此值获得更好的结果,反之则提高。
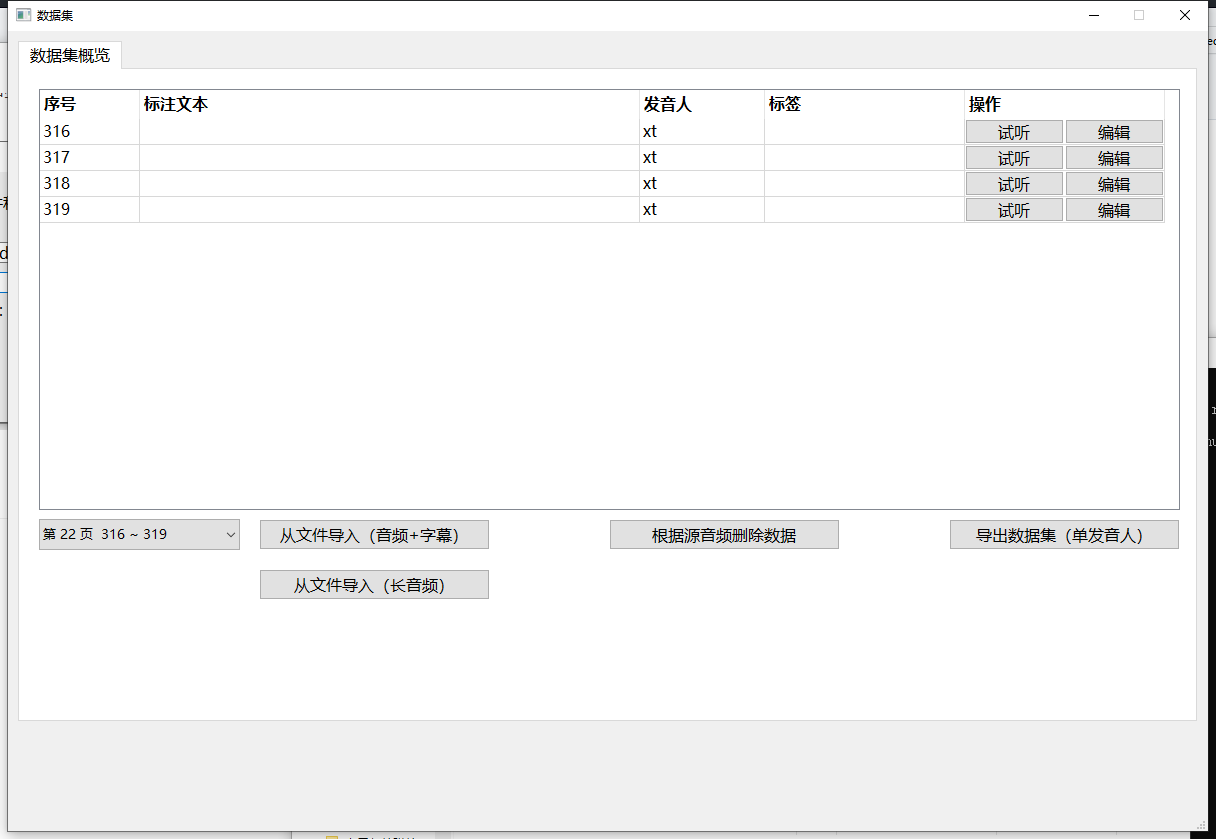
导入后的界面如图所示,需要注意的是因为只有短音频,所以裁切出的音频段没有标注文本,将在未来引入语音识别以进行自动标注。
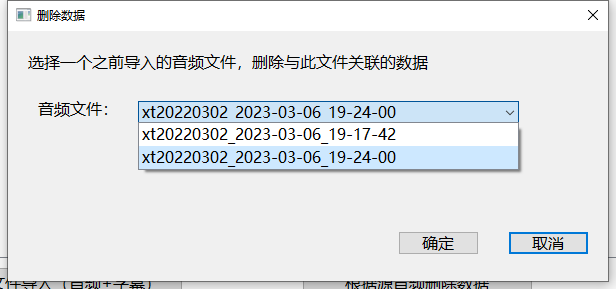
删除数据
根据源音频删除数据
点击按钮后选择一个当前数据集中数据对应的音频,点击确定后音频本身和相关联的数据都会被删除
导出数据
导出数据集(单发音人)
After clicking the button, select parameters. You can also choose a corresponding preset and click the apply button to apply it. If you don't understand the meaning of these values, you can use the default settings.
Note:
Normalization: This refers to loudness matching, which will automatically scale the audio volume according to the input value.
In the current export logic, data containing English or numbers in the annotation text will be skipped. However, if the annotation text is empty, it will still be exported.
Click next to proceed with the dataset export. The window may freeze for a moment, please wait patiently.
[图片]
[图片]
The exported files can be found in the corresponding directory.
[图片]
Speech Evaluation
The speech evaluation function can score sentences through commercial evaluation interfaces to quickly select high-quality data.
Currently, the Tanbei speech evaluation interface has been integrated.
Tanbei Speech Evaluation
Add Authorization Information
First, go to the Software Settings - Authorization Management page, click the add button, enter the name and other fields, and select Speech Evaluation for the application type.
[图片]
For Tanbei-related fields, please go to the Tanbei Open Platform - Speech Evaluation page to activate the service and view (currently in free trial period, hurry if you want to use it for free).
[图片]
After adding, it will automatically verify. Please turn off the proxy program during this process.
Perform Data Evaluation
Then go to the data processing page, click on Tanbei Speech Evaluation, select the corresponding authorization information to start the evaluation.
[图片]
[图片]
Export Based on Evaluation Results
Return to the dataset overview page, click the export button, select Tanbei Evaluation in the evaluation-related section, and fill in the corresponding score requirements.
[图片]
Note: If evaluation is selected, data that has not been evaluated will not be exported. Also, since Tanbei evaluation only supports Chinese, all English data will not be exported after selection.
Click next, confirm, and then start exporting.
[图片]
[图片]
Additionally: Export results when evaluation is not selected
[图片]
Development Plan
Compile exe version
Annotation through ASR
Apply speech evaluation
Apply voice print recognition
Export multi-speaker dataset
Quick export
......
Common Questions
-
How to get subtitles?
Use tools like Jianying or VideoSRT to get SRT subtitle files. You can refer to the following links:
-
What's the logic of automatic optimization?
The optimization logic is to cut 10ms from the start position forward, compare the loudness of this 10ms with the segment from start to start+10, if the loudness before is smaller, move the start forward, until finding a position with the smallest loudness. The end follows a similar logic. This can avoid audio being cut off as much as possible.
Also, subtitles generated by Jianying sometimes split one sentence into multiple sentences, with intervals within 33 milliseconds between each sentence. When encountering this situation, the program will combine these subtitles into one sentence.
-
How to upgrade the exe version?
After downloading the new compressed package, replace the exe file in it with the old version software in the same path, overwriting the original file.
-
To be continued...
编辑推荐精选


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。

DeepEP
DeepSeek开源的专家并行通信优化框架
DeepEP是一个专为大规模分布式计算设计的通信库,重点解决专家并行模式中的通信瓶颈问题。其核心架构采用分层拓扑感知技术,能够自动识别节点间物理连接关系,优化数据传输路径。通过实现动态路由选择与负载均衡机制,系统在千卡级计算集群中维持稳定的低延迟特性,同时兼容主流深度学习框架的通信接口。


DeepSeek
全球领先开源大模型,高效智能助手
DeepSeek是一家幻方量化创办的专注于通用人工智能的中国科技公司,主攻大模型研发与应用。DeepSeek-R1是开源的推理模型,擅长处理复杂任务且可免费商用。


问小白
DeepSeek R1 满血模型上线
问小白是一个基于 DeepSeek R1 模型的智能对话平台,专为用户提供高效、贴心的对话体验。实时在线,支持深度思考和联网搜索。免费不限次数,帮用户写作、创作、分析和规划,各种任务随时完成!

KnowS
AI医学搜索引擎 整合4000万+实时更新的全球医学文献
医学领域专用搜索引擎整合4000万+实时更新的全球医学文献,通过自主研发AI模型实现精准知识检索。系统每日更新指南、中英文文献及会议资料,搜索准确率较传统工具提升80%,同时将大模�型幻觉率控制在8%以下。支持临床建议生成、文献深度解析、学术报告制作等全流程科研辅助,典型用户反馈显示每周可节省医疗工作者70%时间。


Windsurf Wave 3
Windsurf Editor推出第三次重大更新Wave 3
新增模型上下文协议支持与智能编辑功能。本次更新包含五项核心改进:支持接入MCP协议扩展工具生态,Tab键智能跳转提升编码效率,Turbo模式实现自动化终端操作,图片拖拽功能优化多模态交互,以及面向付费用户的个性化图标定制。系统同步集成DeepSeek、Gemini等新模型,并通过信用点数机制实现差异化的资源调配。

腾讯元宝
腾讯自研的混元大模型AI助手
腾讯元宝是腾讯基于自研的混元大模型推出的一款多功能AI应用,旨在通过人工智能技术提升用户在写作、绘画、翻译、编程、搜索、阅读总结等多个领域的工作与生活效率。


Grok3
埃隆·马斯克旗下的人工智能公司 xAI 推出的第三代大规模语言模型
Grok3 是由埃隆·马斯克旗下的人工智能公司 xAI 推出的第三代大规模语言模型,常被马斯克称为“地球上最聪明的 AI”。它不仅是在前代产品 Grok 1 和 Grok 2 基础上的一次飞跃,还在多个关键技术上实现了创新突破。


OmniParser
帮助AI理解电脑屏幕 纯视觉GUI元素的自动化解析方案
开源工具通过计算机视觉技术实现图形界面元素的智能识别与结构化处理,支持自动化测试脚本生成和辅助功能开发。项目采用模块化设计,提供API接口与多种输出格式,适用于跨平台应用场景。核心算法优化了元素定位精度,在动态界面和复杂布局场景下保持稳定解析能力。

流畅阅读
AI网页翻译插件 双语阅读工具,还原母语级体验
流畅阅读是一款浏览器翻译插件,通过上下文智能分析提升翻译准确性,支持中英双语对照显示。集成多翻译引擎接口,允许用户自定义翻译规则和快捷键配置,操作数据全部存储在本地设备保障隐私安全。兼容Chrome、Edge、Firefox等主流浏览器,基于GPL-3.0开源协议开发,提供持续的功能迭代和社区支持。
推荐工具精选








AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号