



空间增量生成引擎 (SIGE)
论文 | 项目 | 幻灯片 | YouTube
[最新消息!] SIGE已被T-PAMI接收!
[最新消息!] SIGE现已支持Stable Diffusion和Mac MPS后端!我们还发布了DDPM在M1 Macbook Pro上的交互式演示代码!
[最新消息!] SIGE已被NeurIPS 2022接收!我们的代码和基准数据集已公开可用!
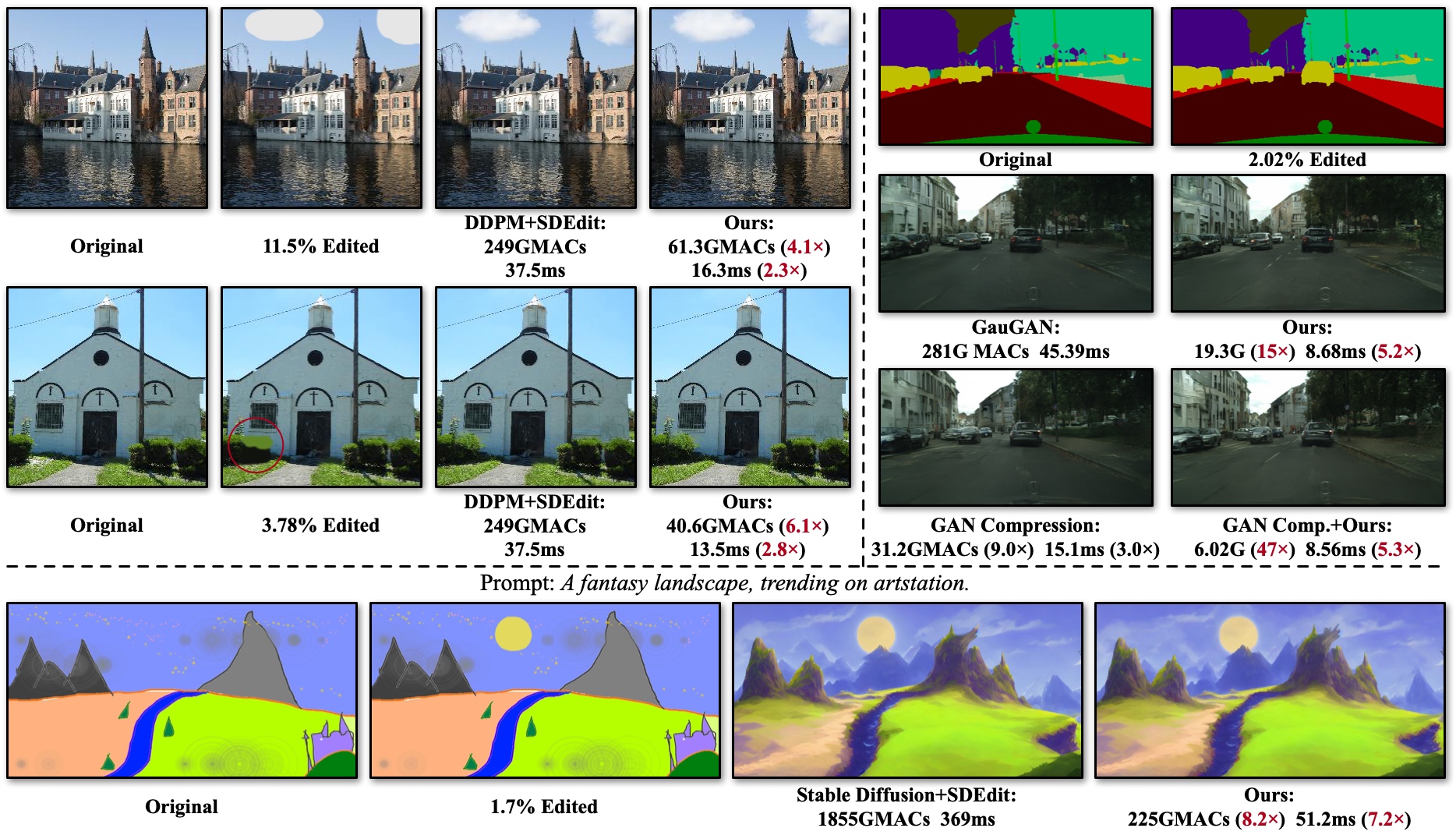 我们提出了空间增量生成引擎(SIGE),这是一个针对图像编辑应用选择性地在编辑区域执行计算的引擎。计算量和延迟是针对单次前向传播测量的。对于上述示例,SIGE显著降低了SDEdit与DDPM(4-6倍)、Stable Diffusion(8倍)和GauGAN(15倍)的计算量,同时保持图像质量。当与现有的模型压缩方法(如GAN压缩)结合时,它进一步将GauGAN的计算量减少了47倍。在NVIDIA RTX 3090上,SIGE实现了高达7.2倍的加速。
我们提出了空间增量生成引擎(SIGE),这是一个针对图像编辑应用选择性地在编辑区域执行计算的引擎。计算量和延迟是针对单次前向传播测量的。对于上述示例,SIGE显著降低了SDEdit与DDPM(4-6倍)、Stable Diffusion(8倍)和GauGAN(15倍)的计算量,同时保持图像质量。当与现有的模型压缩方法(如GAN压缩)结合时,它进一步将GauGAN的计算量减少了47倍。在NVIDIA RTX 3090上,SIGE实现了高达7.2倍的加速。
条件GAN和扩散模型的高效空间稀疏推理</br> 李牧阳、林吉、孟晨林、Stefano Ermon、韩松和朱俊彦</br> 卡内基梅隆大学、麻省理工学院和斯坦福大学</br> NeurIPS 2022
演示
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/30b0a2f3-a385-49f6-8eb5-9db3459633f9.gif" width=600> </p>相比原始DDPM,SIGE在M1 MacBook Pro GPU上实现了2倍更少的转换时间,因为我们选择性地在编辑区域执行计算。
概述
 基于分块的稀疏卷积概述。对于网络中的每个卷积<i>F<sub>l</sub></i>,我们将其封装为SIGE Conv<sub><i>l</i></sub>。原始图像的激活已经预先计算好。在获得编辑后的图像时,我们首先计算原始图像和编辑后图像之间的差异掩码,并将掩码缩减为活跃块索引以定位编辑区域。在每个SIGE Conv<sub><i>l</i></sub>中,我们根据缩减后的索引直接从编辑后的激活<i>A<sub>l</sub></i><sup>edited</sup>中收集活跃块,沿批次维度堆叠这些块,并将它们输入<i>F<sub>l</sub></i>。如果<i>F<sub>l</sub></i>是步长为1的3×3卷积,收集的块会有宽度为2的重叠。在从<i>F<sub>l</sub></i>获得输出块后,我们将它们散布回<i>F<sub>l</sub></i>(<i>A<sub>l</sub></i><sup>original</sup>)以获得编辑后的输出,这近似于<i>F<sub>l</sub></i>(<i>A<sub>l</sub></i><sup>edited</sup>)。
基于分块的稀疏卷积概述。对于网络中的每个卷积<i>F<sub>l</sub></i>,我们将其封装为SIGE Conv<sub><i>l</i></sub>。原始图像的激活已经预先计算好。在获得编辑后的图像时,我们首先计算原始图像和编辑后图像之间的差异掩码,并将掩码缩减为活跃块索引以定位编辑区域。在每个SIGE Conv<sub><i>l</i></sub>中,我们根据缩减后的索引直接从编辑后的激活<i>A<sub>l</sub></i><sup>edited</sup>中收集活跃块,沿批次维度堆叠这些块,并将它们输入<i>F<sub>l</sub></i>。如果<i>F<sub>l</sub></i>是步长为1的3×3卷积,收集的块会有宽度为2的重叠。在从<i>F<sub>l</sub></i>获得输出块后,我们将它们散布回<i>F<sub>l</sub></i>(<i>A<sub>l</sub></i><sup>original</sup>)以获得编辑后的输出,这近似于<i>F<sub>l</sub></i>(<i>A<sub>l</sub></i><sup>edited</sup>)。
性能
效率
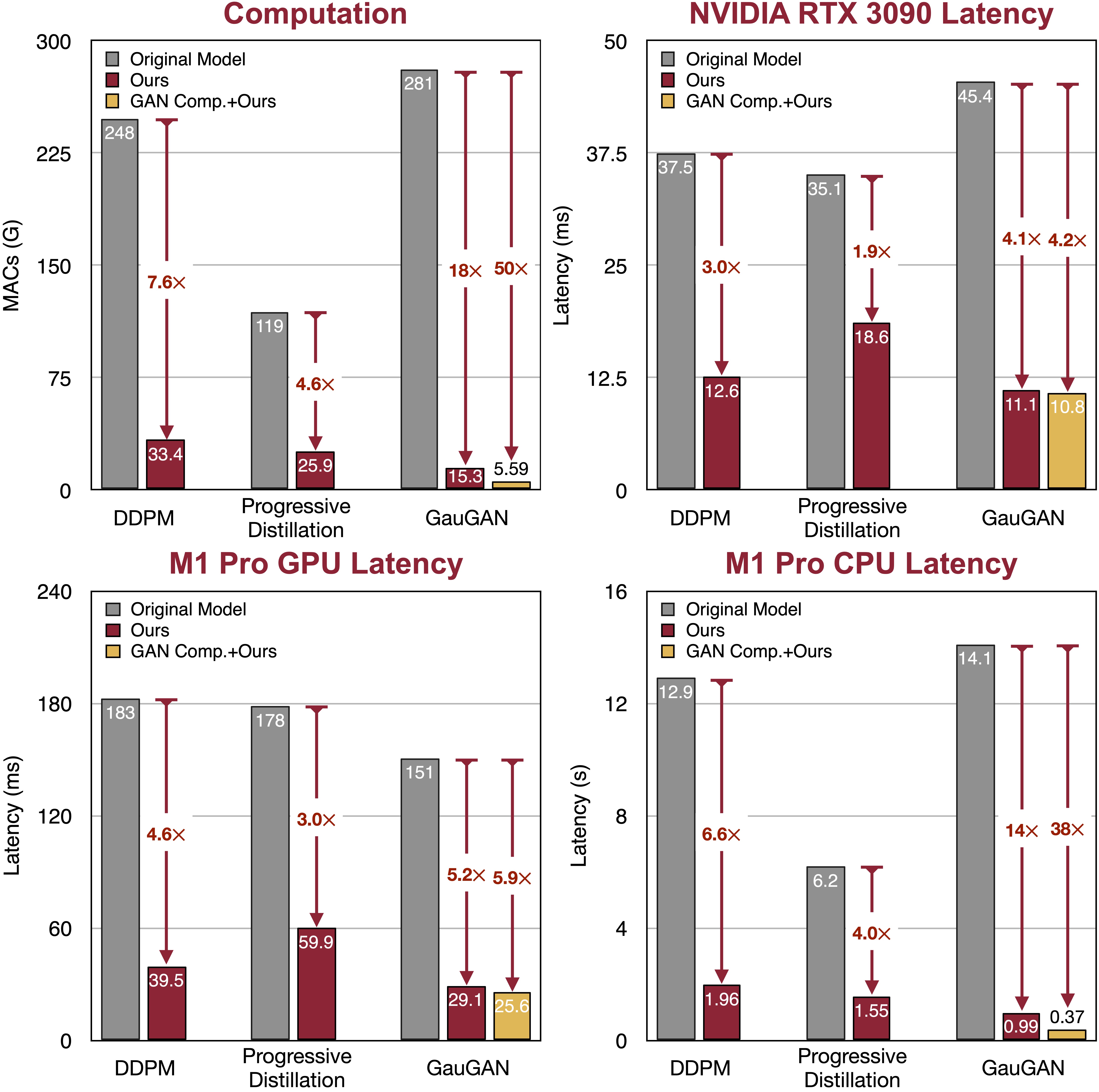 在1.2%的编辑下,SIGE可以将DDPM、Progressive Distillation和GauGAN的计算量减少7-18倍,在NVIDIA RTX 3090上实现2-4倍加速,在Apple M1 Pro GPU上实现3-5倍加速,在M1 Pro CPU上实现4-14倍加速。当与GAN压缩结合时,它进一步将GauGAN的计算量减少50倍,在M1 Pro CPU上实现38倍加速。请查看我们的论文以获取更多细节和结果。
在1.2%的编辑下,SIGE可以将DDPM、Progressive Distillation和GauGAN的计算量减少7-18倍,在NVIDIA RTX 3090上实现2-4倍加速,在Apple M1 Pro GPU上实现3-5倍加速,在M1 Pro CPU上实现4-14倍加速。当与GAN压缩结合时,它进一步将GauGAN的计算量减少50倍,在M1 Pro CPU上实现38倍加速。请查看我们的论文以获取更多细节和结果。
质量
 不同编辑大小下的定性结果。PD是Progressive Distillation。我们的方法很好地保持了原始模型的视觉保真度,而不会丢失全局上下文。
不同编辑大小下的定性结果。PD是Progressive Distillation。我们的方法很好地保持了原始模型的视觉保真度,而不会丢失全局上下文。

在NVIDIA RTX 3090上测量的Stable Diffusion在图像修复和编辑方面的更多定性结果。
参考文献:
- 去噪扩散概率模型(DDPM),Ho等人,ICLR 2020
- 去噪扩散隐式模型(DDIM),Song等人,ICLR 2021
- 用于扩散模型快速采样的渐进蒸馏,Salimans等人,ICLR 2022
- 具有空间自适应归一化的语义图像合成(GauGAN),Park等人,CVPR 2019
- GAN压缩:交互式条件GAN的高效架构,Li等人,CVPR 2020
- 使用潜在扩散模型的高分辨率图像合成,Rombach等人,CVPR 2022
先决条件
入门指南
安装
安装PyTorch后,您应该能够通过PyPI安装SIGE
pip install sige
或通过GitHub:
pip install git+https://github.com/lmxyy/sige.git
或本地安装以进行开发
git clone git@github.com:lmxyy/sige.git cd sige pip install -e .
对于MPS后端,请设置环境变量:
export PYTORCH_ENABLE_MPS_FALLBACK=1
使用示例
请参阅example.py以获取最小SIGE卷积示例。首先按照上述说明安装SIGE,并使用以下命令安装torchprofile:
pip install torchprofile
然后您可以运行:
python example.py
我们还提供了 示例。
示例。
基准测试
要重现DDPM和Progressive Distillation的结果,或下载LSUN Church编辑数据集,请按照diffusion/README.md中的说明操作。
要重现GauGAN和GAN Compression的结果,或下载Cityscapes编辑数据集,请按照gaugan/README.md中的说明操作。
引用
如果您在研究中使用此代码,请引用我们的论文。
@inproceedings{li2022efficient, title={Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models}, author={Li, Muyang and Lin, Ji and Meng, Chenlin and Ermon, Stefano and Han, Song and Zhu, Jun-Yan}, booktitle={Advances in Neural Information Processing Systems (NeurIPS)}, year={2022} }
致谢
我们的代码基于SDEdit、ddim、diffusion_distillation、gan-compression、dpm-solver和stable-diffusion开发。我们参考了sbnet实现基于平铺的稀疏卷积算法。我们的工作还受到torchsparse中收集/分散实现的启发。
我们感谢torchprofile用于MACs测量,clean-fid用于FID计算,以及drn用于Cityscapes mIoU计算。
我们感谢丁耀耀、叶子豪、郑连敏、唐浩天和朱立庚对引擎设计的有益评论。我们还感谢George Cazenavette、邓康乐、高睿涵、陆道涵、王圣宇和张炳良的宝贵反馈。该项目部分得到NSF、MIT-IBM Watson AI Lab、快手公司和索尼公司的支持。
编辑推荐精选


ai-agents-for-beginners
10 节课教你开启构建 AI 代理所需的一切知识
AI Agents for Beginners 是一个专为初学者打造的课程项目,提供 10 节课程,涵盖构建 AI 代理的必备知识,支持多种语言,包含规划设计、工具使用、多代理等丰富内容,助您快速入门 AI 代理领域。


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生�成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号