
Video-ChatGPT
创新视频对话技术开启细致视频理解新纪元
Video-ChatGPT是一个融合大型视觉和语言模型的视频对话系统。该项目构建了10万条视频-指令对数据集,开发了首个视频对话量化评估框架,在视频推理、创意生成、空间和时间理解等任务中表现出色。这一开源项目为视频内容理解和人机交互带来了新的发展方向。




Oryx 视频聊天GPT :movie_camera: :speech_balloon:
<p align="center"> <img src="https://i.imgur.com/waxVImv.png" alt="Oryx 视频聊天GPT"> </p>视频聊天GPT:通过大型视觉和语言模型实现详细的视频理解 [ACL 2024 🔥]
Muhammad Maaz* , Hanoona Rasheed* , Salman Khan 和 Fahad Khan
* 同等贡献的第一作者
穆罕默德·本·扎耶德人工智能大学
多样化视频生成性能基准测试 (VCGBench-Diverse)
![]()
视频生成性能基准测试
![]()
零样本问答评估
![]()
![]()
![]()
![]()
| 演示 | 论文 | 演示片段 | 离线演示 | 训练 | 视频指令数据 | 定量评估 | 定性分析 |
|---|---|---|---|---|---|---|---|
 |  | 离线演示 | 训练 | 视频指令数据集 | 定量评估 | 定性分析 |
:loudspeaker: 最新更新
- 2024年6月14日: VideoGPT+ 发布。它在多个基准测试中取得了最先进的结果。查看 VideoGPT+ :fire::fire:
- 2024年6月14日: 半自动视频标注流程 发布。查看 GitHub, HuggingFace. :fire::fire:
- 2024年6月14日: VCGBench-多样化基准 发布。它提供了18个视频类别的4,354个人工标注的问答对,用于全面评估视频对话模型的性能。查看 GitHub, HuggingFace. :fire::fire:
- 2024年5月16日: Video-ChatGPT 被ACL 2024接收! 🎊���🎊
- 2023年9月30日: 我们的VideoInstruct100K数据集可以从 HuggingFace/VideoInstruct100K 下载。 :fire::fire:
- 2023年7月15日: 我们的基于视频的对话模型定量评估基准现在有了专门的网站:https://mbzuai-oryx.github.io/Video-ChatGPT。 :fire::fire:
- 2023年6月28日: 更新了GitHub readme,展示了Video-ChatGPT与最近模型(Video Chat、Video LLaMA和LLaMA Adapter)的基准比较。在这些先进的对话模型中,Video-ChatGPT继续保持最先进的性能。:fire::fire:
- 2023年6月8日: 发布了训练代码、离线演示、指令数据和技术报告。所有资源包括模型、数据集和提取特征都可在此处获取。 :fire::fire:
- 2023年5月21日: Video-ChatGPT: 演示发布。
在线演示 :computer:
:fire::fire: 您可以使用提供的示例或上传自己的视频来尝试我们的演示 点击这里. :fire::fire:
:fire::fire: 或点击图片试用演示! :fire::fire:
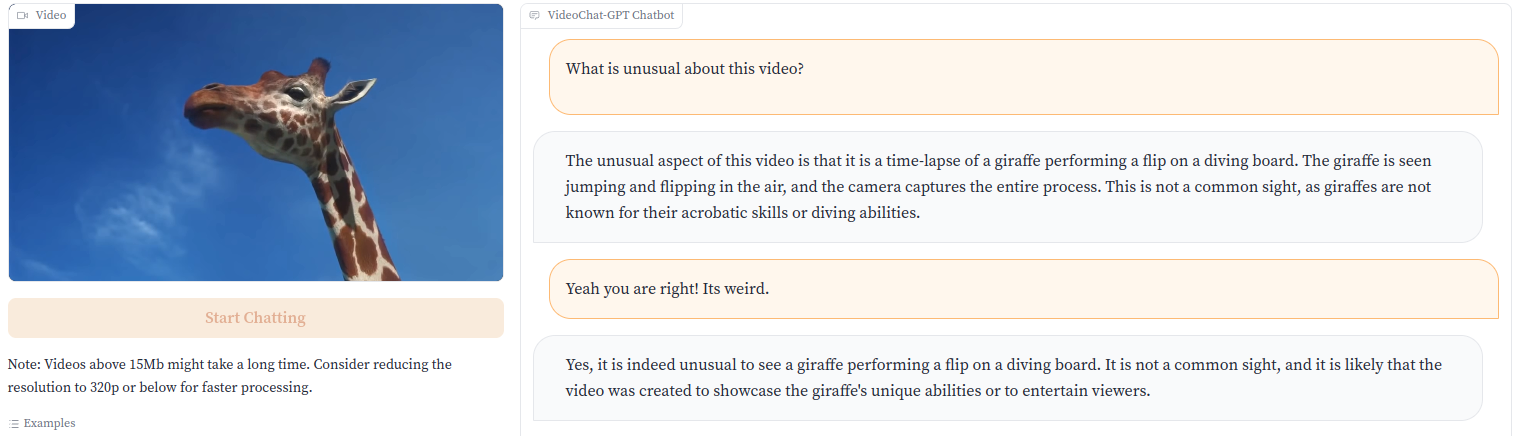 您可以在这里访问我们演示的所有视频。
您可以在这里访问我们演示的所有视频。
Video-ChatGPT 概述 :bulb:
Video-ChatGPT 是一个能够针对视频生成有意义对话的视频对话模型。它结合了大语言模型的能力和经过预训练的视觉编码器,适用于时空视频表示。
<p align="center"> <img src="https://raw.githubusercontent.com/mbzuai-oryx/Video-ChatGPT/main/docs/images/Video-ChatGPT.gif" alt="Video-ChatGPT 架构概述"> </p>贡献 :trophy:
- 我们引入了10万对高质量的视频-指令对,以及一个新颖的、可扩展的注释框架,该框架生成多样化的高质量视频特定指令集。
- 我们开发了第一个用于基准测试视频对话模型的定量视频对话评估框架。
- 独特的多模态(视觉-语言)能力,结合视频理解和语言生成,通过定量和定性比较在视频推理、创造性、空间和时间理解以及动作识别任务上进行全面评估。
安装 :wrench:
我们建议为项目设置一个conda环境:
conda create --name=video_chatgpt python=3.10 conda activate video_chatgpt git clone https://github.com/mbzuai-oryx/Video-ChatGPT.git cd Video-ChatGPT pip install -r requirements.txt export PYTHONPATH="./:$PYTHONPATH"
此外,安装 FlashAttention 用于训练,
pip install ninja git clone https://github.com/HazyResearch/flash-attention.git cd flash-attention git checkout v1.0.7 python setup.py install
离线运行演示 :cd:
要离线运行演示,请参考 offline_demo.md 中的说明。
训练 :train:
有关训练说明,请查看 train_video_chatgpt.md。
视频指令数据集 :open_file_folder:
我们正在发布用于训练Video-ChatGPT模型的10万条高质量视频指令数据集。您可以从这里下载该数据集。有关我们用于生成数据的人工辅助和半自动标注框架的更多详细信息,请参阅VideoInstructionDataset.md。
定量评估 :bar_chart:
我们的论文引入了一个新的基于视频的对话模型定量评估框架。要探索我们的基准测试并更深入地了解该框架,请访问我们的专用网站:https://mbzuai-oryx.github.io/Video-ChatGPT。
有关如何进行定量评估的详细说明,请参阅QuantitativeEvaluation.md。
为了详细概述性能,提供了基于视频的生成性能基准测试和零样本问答评估表格。
零样本问答评估
| 模型 | MSVD-QA | MSRVTT-QA | TGIF-QA | Activity Net-QA | ||||
|---|---|---|---|---|---|---|---|---|
| 准确率 | 得分 | 准确率 | 得分 | 准确率 | 得分 | 准确率 | 得分 | |
| FrozenBiLM | 32.2 | -- | 16.8 | -- | 41.0 | -- | 24.7 | -- |
| Video Chat | 56.3 | 2.8 | 45.0 | 2.5 | 34.4 | 2.3 | 26.5 | 2.2 |
| LLaMA Adapter | 54.9 | 3.1 | 43.8 | 2.7 | - | - | 34.2 | 2.7 |
| Video LLaMA | 51.6 | 2.5 | 29.6 | 1.8 | - | - | 12.4 | 1.1 |
| Video-ChatGPT | 64.9 | 3.3 | 49.3 | 2.8 | 51.4 | 3.0 | 35.2 | 2.7 |
基于视频的生成性能基准测试
| 评估方面 | Video Chat | LLaMA Adapter | Video LLaMA | Video-ChatGPT |
|---|---|---|---|---|
| 信息准确性 | 2.23 | 2.03 | 1.96 | 2.40 |
| 细节关注度 | 2.50 | 2.32 | 2.18 | 2.52 |
| 上下文理解 | 2.53 | 2.30 | 2.16 | 2.62 |
| 时序理解 | 1.94 | 1.98 | 1.82 | 1.98 |
| 一致性 | 2.24 | 2.15 | 1.79 | 2.37 |
定性分析 :mag:
Video-ChatGPT在多项任务中的全面性能评估。
视频推理任务 :movie_camera:

创意和生成任务 :paintbrush:

空间理解 :globe_with_meridians:

视频理解和对话任务 :speech_balloon:

动作识别 :runner:

问答任务 :question:

时序理解 :hourglass_flowing_sand:

致谢 :pray:
- LLaMA:朝着开放高效的大型语言模型迈出的重要一步!
- Vicuna:具有惊人的语言能力!
- LLaVA:我们的架构受到LLaVA的启发。
- 感谢我们在MBZUAI的同事对视频标注任务的重要贡献��, 包括Salman Khan、Fahad Khan、Abdelrahman Shaker、Shahina Kunhimon、Muhammad Uzair、Sanoojan Baliah、Malitha Gunawardhana、Akhtar Munir、 Vishal Thengane、Vignagajan Vigneswaran、Jiale Cao、Nian Liu、Muhammad Ali、Gayal Kurrupu、Roba Al Majzoub、 Jameel Hassan、Hanan Ghani、Muzammal Naseer、Akshay Dudhane、Jean Lahoud、Awais Rauf、Sahal Shaji、Bokang Jia, 没有他们这个项目就无法实现。
如果您在研究或应用中使用Video-ChatGPT,请使用以下BibTeX引用:
@inproceedings{Maaz2023VideoChatGPT, title={Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models}, author={Maaz, Muhammad and Rasheed, Hanoona and Khan, Salman and Khan, Fahad Shahbaz}, booktitle={Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)}, year={2024} }
许可证 :scroll:
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="知识共享许可协议" style="border-width:0" src="https://yellow-cdn.veclightyear.com/ab5030c0/69b2c627-4276-48d0-8b6a-891ff58a69b5.png" /></a><br />本作品采用<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/">知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议</a>进行许可。
期待您的反馈、贡献和星标!:star2: 如有任何问题或疑问,请在这里提出。
<img src="https://yellow-cdn.veclightyear.com/ab5030c0/5ea012c7-a7f2-4568-868a-4369580d7813.png" width="200" height="100"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/a6660cc0-7a8d-4ace-bd0c-24a7a212aadd.png" width="100" height="100"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/f3d831d4-2bfe-41b6-a184-fad24c184cff.png" width="360" height="85">
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的��语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号