
XrayGPT
胸部X光智能分析与报告生成系统
XrayGPT是一个结合医学视觉语言模型技术的人工智能项目,专注于胸部X光片分析和报告生成。该系统整合了经过微调的Vicuna语言模型和MedClip医学视觉编码器,通过线性变换实现对齐。XrayGPT经过大量医患对话和放射学对话训练,可生成准确、清晰的X光分析摘要,为放射科医生提供辅助支持。





XrayGPT:使用医疗视觉语言模型对胸部X光片进行概括。

Omkar Thawakar* , Abdelrahman Shaker* , Sahal Shaji Mullappilly* , Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Jorma Laaksonen, 和 Fahad Shahbaz Khan。
*平等贡献
阿联酋摩罕默德·本·扎耶德人工智能大学
<a href='#'><img src='https://img.shields.io/badge/Project-Page-Green'></a> 
:rocket: 新闻
<hr>- 8月4日: 我们的论文已被BIONLP-ACL 2024接受 :fire:
- 6月14日: 我们的技术报告已发布 here. :fire::fire:
- 5月25日: 我们的技术报告将很快发布。敬请关注!
- 5月19日: 我们的代码、模型和预处理的报告概要已发布。
在线演示
您可以使用提供的示例或上传自己的X光片来尝试我们的演示: 链接1 | 链接2 | 链接3 。
关于XrayGPT
<hr>- XrayGPT旨在刺激围绕基于给定X光片的自动化胸部X光片分析的研究。
- LLM(Vicuna)在医疗数据(10万个患者和医生之间的实际对话)和约30,000个放射学对话上进行了微调,以获取特定领域的相关特征。
- 我们从两个数据集(MIMIC-CXR和OpenI)的自由文本放射线报告中生成交互式和干净的总结(约21.7万个)。这些总结有助于通过在高质量数据上微调线性变换层来提高LLMs的性能。有关我们高质量总结的更多详细信息,请查看数据集创建。
- 我们使用简单的线性变换将冻结的医疗视觉编码器(MedClip)与微调的LLM(Vicuna)进行对齐。

入门
安装
1. 准备代码和环境
克隆存储库并创建 anaconda 环境
git clone https://github.com/mbzuai-oryx/XrayGPT.git cd XrayGPT conda env create -f env.yml conda activate xraygpt
或
git clone https://github.com/mbzuai-oryx/XrayGPT.git cd XrayGPT conda create -n xraygpt python=3.9 conda activate xraygpt pip install -r xraygpt_requirements.txt
设置
1. 为训练准备数据集
请参考dataset_creation了解更多详细信息。
下载预处理的注释 mimic 和 openi。 相应的图像文件夹包含来自数据集的图像。
最终的数据集文件夹结构如下:
dataset
├── mimic
| ├── image
| | ├──abea5eb9-b7c32823-3a14c5ca-77868030-69c83139.jpg
| | ├──427446c1-881f5cce-85191ce1-91a58ba9-0a57d3f5.jpg
| | .....
| ├──filter_cap.json
├── openi
| ├── image
| | ├──1.jpg
| | ├──2.jpg
| | .....
| ├──filter_cap.json
...
3. 准备预训练的Vicuna权重
我们在Vicuna-7B的v1版本上构建了XrayGPT。 我们使用精心挑选的放射线报告样本对Vicuna进行了微调。 从vicuna_weights下载Vicuna权重 最终的权重将在一个单独的文件夹中,结构类似于以下内容:
vicuna_weights
├── config.json
├── generation_config.json
├── pytorch_model.bin.index.json
├── pytorch_model-00001-of-00003.bin
...
然后,在模型配置文件"xraygpt/configs/models/xraygpt.yaml"的第16行设置vicuna权重的路径。 在放射学样本上微调Vicuna,请下载我们精选的放射学和医疗保健对话样本,并参考原始的Vicuna repo进行微调。Vicuna_Finetune
4. 下载预训练的Minigpt-4检查点
下载预训练的minigpt-4检查点。ckpt
5. XrayGPT的训练
A. 第一阶段的预训练
在第一阶段的预训练中,模型使用来自预处理的MIMIC数据集的图像-文本对进行训练。
要启动第一阶段的训练,运行以下命令。在我们的实验中,我们使用4个AMD MI250X GPU。
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/xraygpt_mimic_pretrain.yaml
2. 第二阶段的OpenI微调
在第二阶段,我们使用由我们预处理的小型高质量图像-文本对OpenI数据集。
运行以下命令。在我们的实验中,我们使用AMD MI250X GPU。
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/xraygpt_openi_finetune.yaml
在本地机器上启动演示
下载预训练的xraygpt检查点。link
将此ckpt添加到"eval_configs/xraygpt_eval.yaml"。
在您的本地机器上尝试gradio demo.py,使用以下命令:
python demo.py --cfg-path eval_configs/xraygpt_eval.yaml --gpu-id 0
示例
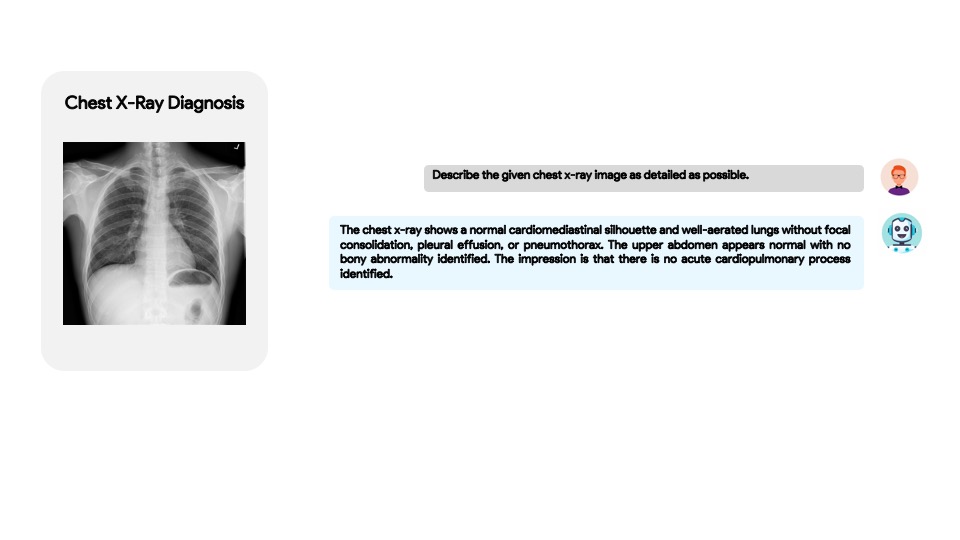 |  |
 |  |
致谢
<hr>- MiniGPT-4 利用先进的大型语言模型增强视觉语言理解。我们的模型建立在MiniGPT-4的基础之上。
- MedCLIP 从无配对的医疗图像和文本中进行对比学习。我们使用了MedCLIP中的医疗感知图像编码器。
- BLIP2 XrayGPT的模型架构遵循BLIP-2。
- Lavis 此存储库建立在Lavis之上!
- Vicuna Vicuna的出色语言能力令人惊叹,并且是开源的!
引用
如果您在研究或应用中使用XrayGPT,请使用以下BibTeX引用:
@article{Omkar2023XrayGPT, title={XrayGPT: Chest Radiographs Summarization using Large Medical Vision-Language Models}, author={Omkar Thawkar, Abdelrahman Shaker, Sahal Shaji Mullappilly, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Jorma Laaksonen and Fahad Shahbaz Khan}, journal={arXiv: 2306.07971}, year={2023} }
许可
本存储库采用CC BY-NC-SA许可。请参考此处的许可条款。
编辑推荐精选


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。


TRELLIS
用于可扩展和多功能 3D 生成的结构化 3D 潜在表示
TRELLIS 是一个专注于 3D 生成的项目,它利用结构化 3D 潜在表示技术,实现了可扩展且多功能的 3D 生成。项目提供了多种 3D 生成的方法和工具,包括文本到 3D、图像到 3D 等,并且支持多种输出格式,如 3D 高斯、辐射场和网格等。通过 TRELLIS,用户可以根据文本描述或图像输入快速生成高质量的 3D 资产,适用于游戏开发、动画制作、虚拟现实等多个领域。


ai-agents-for-beginners
10 节课教你开启构建 AI 代理所需的一切知识
AI Agents for Beginners 是一个专为初学者打造的课程项目,提供 10 节课程,涵盖构建 AI 代理的必备知识,支持多种语言,包含规划设计、工具使用、多代理等丰富内容,助您快速入门 AI 代理领域。


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号